Helsinki-NLP/opus-100
收藏Hugging Face2024-02-28 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Helsinki-NLP/opus-100
下载链接
链接失效反馈官方服务:
资源简介:
OPUS-100 是一个多语言翻译数据集,涵盖了广泛的语言和语言对。数据集的大小从少于1K到超过10M不等,主要用于翻译任务。数据来源于扩展的数据集。README 文件中列出了每个语言对的配置名称、特征、分割和大小。
OPUS-100 is a multilingual translation dataset encompassing a wide array of languages and language pairs. The scale of its subsets ranges from less than 1K to over 10M, and it is primarily employed for translation-related tasks. The dataset is derived from expanded source datasets. The configuration names, features, data splits, and sizes for each language pair are listed in the README file.
提供机构:
Helsinki-NLP
原始信息汇总
数据集概述
基本信息
- 名称: OPUS-100
- 语言: 支持多种语言,包括但不限于英语、中文、法语、德语等。
- 许可证: 未知
- 多语言性: 翻译
数据集大小
- 规模: 包含多个子集,规模从小于1K到超过10M不等。
数据集结构
- 任务类型: 翻译
- 配置名称: 包含多种语言对的配置,如af-en, am-en, an-en等。
数据集内容
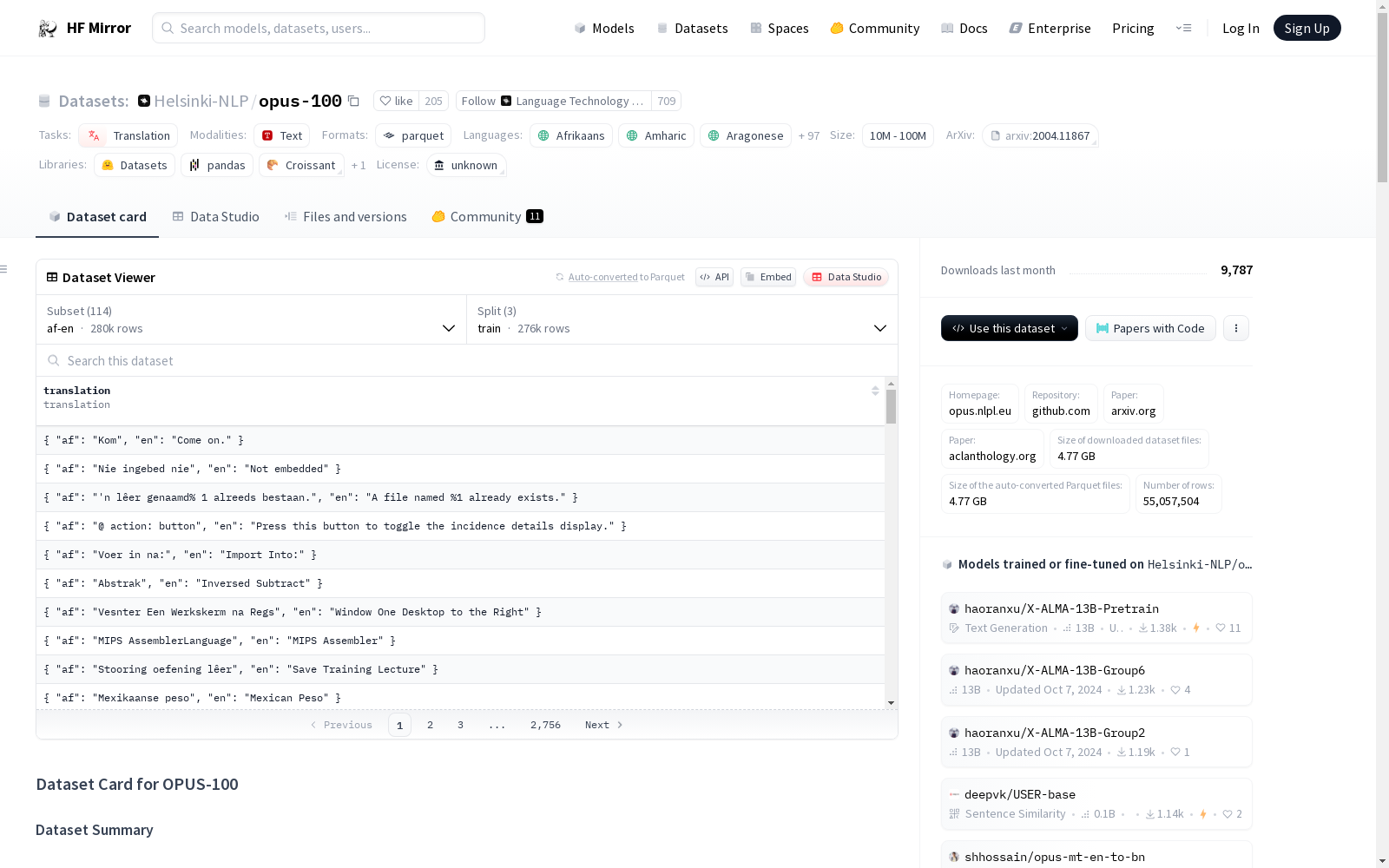
- 特征: 每个配置包含一个名为
translation的特征,指定了源语言和目标语言。 - 分割: 数据集通常分为
test,train,validation三个部分,每个部分包含的示例数和字节数不同。
示例数据集详情
-
配置名称: af-en
- 特征:
translation,包含语言对af(阿非利卡语)和en(英语)。 - 分割:
test: 2000个示例,135908字节。train: 275512个示例,18726247字节。validation: 2000个示例,132769字节。
- 下载大小: 14852797字节
- 数据集大小: 18994924字节
- 特征:
-
配置名称: am-en
- 特征:
translation,包含语言对am(阿姆哈拉语)和en(英语)。 - 分割:
test: 2000个示例,588021字节。train: 89027个示例,21950572字节。validation: 2000个示例,566069字节。
- 下载大小: 12630031字节
- 数据集大小: 23104662字节
- 特征:
其他配置
- 数据集包含多个其他语言对的配置,每个配置的详细信息包括特征、分割、下载大小和数据集大小。这些信息在README文件中有详细记录,可根据需要查阅。
搜集汇总
数据集介绍
构建方式
OPUS-100数据集是通过收集并整理来自互联网的平行语料构建而成的。这些语料涵盖了100种不同的语言对,包括英语与其他语言的翻译。构建过程涉及了对语料的清洗、去重以及格式化,以确保数据的质量和一致性。数据集以多种规模提供,从数以千计的样本到数以百万计的样本不等,以满足不同研究需求。
特点
OPUS-100数据集的一个显著特点是它的多语言性和大规模。它包含了100种语言对的翻译数据,为多语言研究和应用提供了丰富的资源。此外,数据集具有明确的划分,包括训练集、验证集和测试集,方便研究人员进行模型训练和评估。每个语言对的翻译数据量也相当庞大,有助于提高翻译模型的准确性和泛化能力。
使用方法
使用OPUS-100数据集,研究人员可以将其作为翻译模型的训练数据,通过在训练集上进行模型训练,并在验证集上进行参数调整,最后在测试集上评估模型的性能。此外,该数据集还支持跨语言研究和多语言模型训练,为探索更广泛的语言处理任务提供了可能。用户可以根据需要下载特定的语言对数据,并根据任务需求进行数据预处理和模型训练。
背景与挑战
背景概述
在当今全球化的世界中,多语言文本翻译已成为信息交流的关键技术之一。为了推动这一领域的研究,Helsinki-NLP/opus-100 数据集应运而生,该数据集由赫尔辛基大学自然语言处理实验室的研究团队创建,旨在为机器翻译研究提供一个大规模、多语言的翻译数据集。自创建以来,Helsinki-NLP/opus-100 数据集已对机器翻译领域产生了深远的影响,被广泛应用于各类学术研究和工业应用中。
当前挑战
尽管 Helsinki-NLP/opus-100 数据集在机器翻译领域具有重要价值,但在其构建和使用过程中仍面临一些挑战。首先,数据集的多语言特性使得数据收集和清洗工作变得异常复杂,特别是在处理低资源语言时。其次,翻译质量评估标准的多样性以及不同语言之间的差异也为研究带来了挑战。此外,随着数据集规模的不断扩大,如何有效地管理和使用这些数据资源也成为了亟待解决的问题。
常用场景
经典使用场景
在机器翻译领域,Helsinki-NLP/opus-100数据集提供了丰富的语言对翻译示例,支持跨语言交流的研究。其多语言特性使得该数据集适用于构建和训练翻译模型,帮助研究人员理解和提升不同语言之间的转换质量。
衍生相关工作
基于Helsinki-NLP/opus-100数据集,衍生了许多重要的研究成果。例如,研究人员利用该数据集训练的翻译模型在多个翻译比赛中取得了优异成绩,推动了机器翻译技术的发展。此外,该数据集还激发了关于跨语言信息检索、多语言文本生成等研究方向的探索。
数据集最近研究
最新研究方向
随着多语言翻译领域的迅猛发展,Helsinki-NLP/opus-100 数据集成为该领域研究的重要资源。该数据集涵盖了超过100种语言的翻译任务,为研究者提供了广泛的语言对进行模型训练和评估。最新的研究方向包括但不限于:1) 针对低资源语言的翻译模型研究,利用OPUS-100中的丰富语言对来提高模型在稀缺资源语言上的表现;2) 探索基于注意力机制的翻译模型,进一步优化翻译质量;3) 利用OPUS-100中的大规模数据集进行跨语言学习,提升模型在不同语言之间的泛化能力。这些研究对于推动多语言翻译技术的进步具有重要意义,有助于构建更加高效和准确的翻译模型,满足全球范围内的语言交流需求。
以上内容由遇见数据集搜集并总结生成


