Bilik-Instruct
收藏Hugging Face2025-12-23 更新2025-12-24 收录
下载链接:
https://huggingface.co/datasets/LocalDoc/Bilik-Instruct
下载链接
链接失效反馈官方服务:
资源简介:
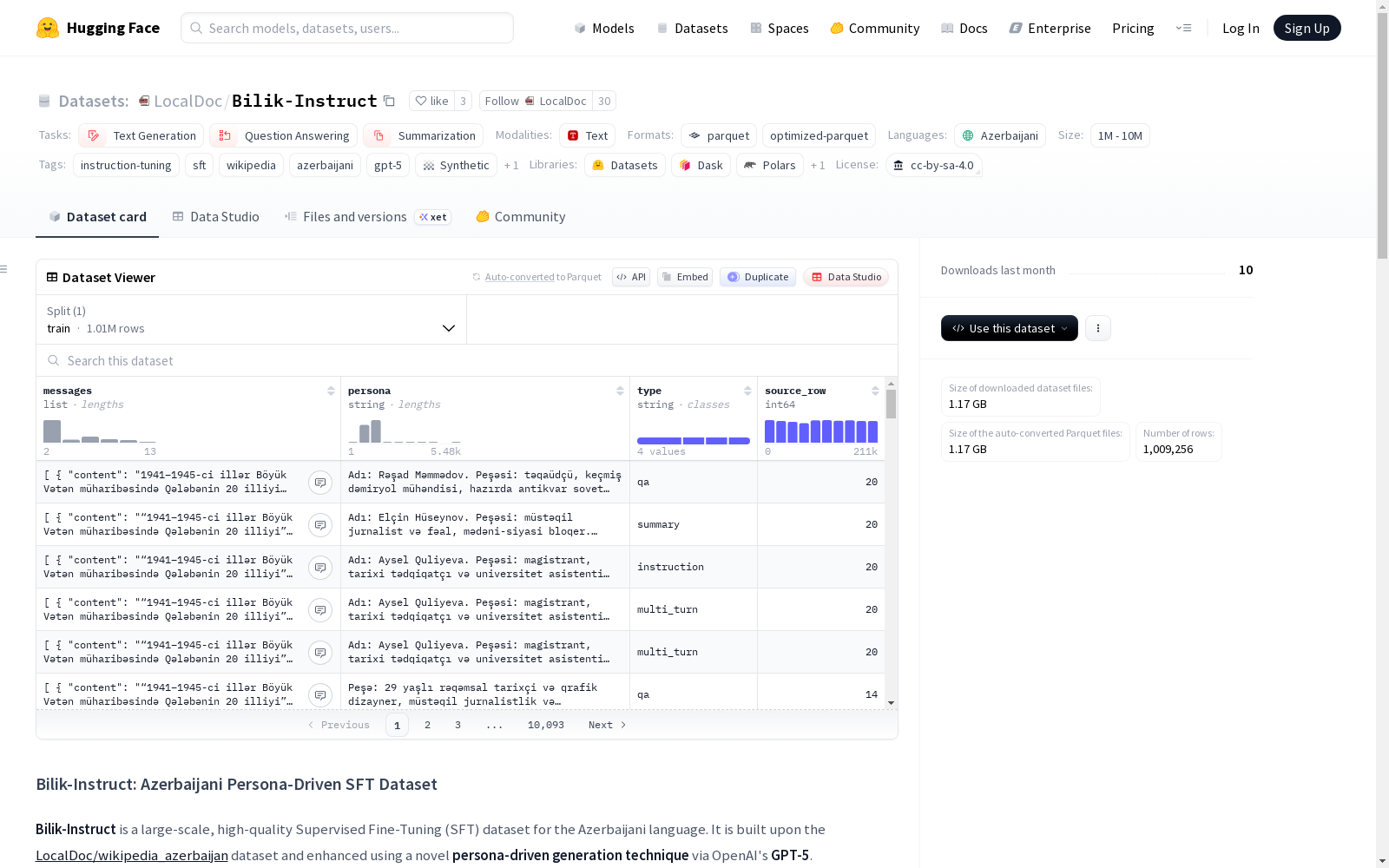
Bilik-Instruct是一个用于阿塞拜疆语的大规模、高质量的监督微调(SFT)数据集。该数据集基于LocalDoc/wikipedia_azerbaijan数据集,并通过OpenAI的GPT-5使用新颖的persona驱动生成技术进行增强。其目标是超越正式的百科全书式语言,捕捉各种领域中的自然、对话式阿塞拜疆语。数据集包含约100万样本,涵盖多轮对话、问答、摘要和一般指令等多种类型。数据集的生成过程包括persona生成和风格化SFT生成两个步骤,以确保语言的多样性和自然性。数据集的结构包括messages、persona、type和source_row等字段。数据集遵循CC BY-SA 4.0许可,并要求在使用时引用。
Bilik-Instruct is a large-scale, high-quality supervised fine-tuning (SFT) dataset for the Azerbaijani language. This dataset is built upon the LocalDoc/wikipedia_azerbaijan dataset, and enhanced by OpenAI's GPT-5 using a novel persona-driven generation technique. Its goal is to move beyond formal encyclopedic language and capture natural, conversational Azerbaijani across various domains. The dataset contains approximately 1 million samples, covering diverse types such as multi-turn conversations, question answering, summarization, and general instruction tasks. The dataset's generation process consists of two steps: persona generation and stylized SFT generation, which ensure the diversity and naturalness of the language. The dataset includes fields such as messages, persona, type, and source_row. The dataset is licensed under CC BY-SA 4.0, and proper citation is required when using it.
创建时间:
2025-12-21
原始信息汇总
Bilik-Instruct 数据集概述
基本信息
- 数据集名称:Bilik-Instruct
- 完整名称:Bilik-Instruct: Azerbaijani Persona-Driven SFT Dataset
- 发布者:LocalDoc
- 发布日期:2025年
- 托管平台:Hugging Face
- 数据集地址:https://huggingface.co/datasets/LocalDoc/Bilik-Instruct
- 许可证:Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)
- 源数据集:LocalDoc/wikipedia_azerbaijan
数据集描述
Bilik-Instruct 是一个用于阿塞拜疆语的大规模、高质量监督微调数据集。它基于 LocalDoc/wikipedia_azerbaijan 数据集构建,并通过 OpenAI 的 GPT-5 采用新颖的角色驱动生成技术进行增强。该数据集的目标是超越正式、百科全书式的语言,捕捉不同领域的自然、会话式阿塞拜疆语。
关键特征
- 任务类别:文本生成、问答、摘要
- 语言:阿塞拜疆语(拉丁字母)
- 标签:指令微调、监督微调、维基百科、阿塞拜疆语、GPT-5、合成数据、角色驱动
- 规模类别:1M < n < 10M
- 数据性质:合成数据
数据集统计
- 总样本数:1,009,256
- 训练集大小:3,368,854,045 字节
- 下载大小:1,165,118,613 字节
- 数据拆分:仅包含训练集
数据构成
- 多轮对话:30%
- 问答:25%
- 摘要:25%
- 通用指令:20%
生成方法
数据集采用两步流程确保语言多样性:
- 角色生成:为源数据集中的每个维基百科文章生成多样化的合成角色。
- 风格化监督微调生成:使用这些角色生成训练样本,并施加严格约束,包括自然性、特异性和上下文连贯性。
数据结构
数据集包含以下特征字段:
messages:采用标准 ChatML 格式的字典列表,包含生成的对话。persona:用于引导用户问题风格的详细合成角色。type:样本类别,可为:qa、summary、instruction或multi_turn。source_row:原始 LocalDoc/wikipedia_azerbaijan 数据集中文章的索引。
使用与引用
- 使用条款:该数据集衍生自维基百科内容。任何基于此数据训练的衍生作品都应注明阿塞拜疆语维基百科贡献者。合成组件使用 OpenAI API 生成,请遵守 OpenAI 关于生成内容的使用政策。
- 引用格式: bibtex @dataset{bilik_instruct_2025, author = {LocalDoc}, title = {Bilik-Instruct: Azerbaijani Persona-Driven SFT Dataset}, year = {2025}, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/LocalDoc/Bilik-Instruct} }
局限性
- 幻觉:虽然基于维基百科文本,但模型偶尔可能生成看似合理但不正确的细节。
- 偏见:数据集反映了维基百科和 OpenAI 模型中存在的偏见。
搜集汇总
数据集介绍
构建方式
在阿塞拜疆语自然语言处理领域,构建高质量监督微调数据集面临资源稀缺的挑战。Bilik-Instruct数据集采用创新的两阶段流水线构建方法,其基础源于LocalDoc/wikipedia_azerbaijan语料库。首先,针对每篇维基百科文章,利用GPT-5-Mini模型生成多样化的合成人物角色,例如模拟特定背景的提问者视角。随后,基于这些人物角色,通过GPT-5模型在严格约束下生成训练样本,确保语言的自然性与问题的自包含性,有效避免了机械化的翻译腔调。
特点
该数据集的核心特征在于其人物角色驱动的生成范式与丰富的内容构成。数据集包含约一百万条样本,涵盖多轮对话、问答、摘要及通用指令四种类型,比例分配均衡。每条样本均附有详细的人物角色描述,引导生成风格各异的自然对话,显著提升了语言风格的多样性。数据结构采用标准的ChatML格式,并保留了与源文章的索引关联,为模型训练提供了清晰的上下文与可追溯的语料来源。
使用方法
对于旨在提升阿塞拜疆语对话能力的模型开发者而言,该数据集可直接用于监督微调训练。使用者可通过Hugging Face平台加载数据集,并依据样本中的‘type’字段筛选特定任务类型进行针对性训练。在模型训练过程中,应充分关注‘messages’字段中的多轮对话结构,以学习连贯的上下文理解与生成能力。鉴于数据合成过程中可能存在的幻觉与偏见,建议在实际应用中结合人工评估与后处理技术,以确保模型输出的准确性与公正性。
背景与挑战
背景概述
在低资源语言的自然语言处理领域,阿塞拜疆语长期以来面临高质量指令微调数据稀缺的困境。为应对这一挑战,LocalDoc研究团队于2025年发布了Bilik-Instruct数据集,该数据集基于阿塞拜疆语维基百科语料,采用创新的角色驱动生成技术,通过GPT-5模型构建了涵盖对话、问答、摘要等多种任务类型的大规模监督微调数据集。该数据集的诞生标志着阿塞拜疆语自然语言处理研究从基础资源建设向高级语言理解应用的重要转型,为开发具有文化适应性的智能对话系统奠定了数据基础。
当前挑战
该数据集旨在解决阿塞拜疆语自然语言处理中高质量对话与指令数据的稀缺性挑战,其核心任务在于生成自然流畅、符合母语者表达习惯的多样化语言样本。在构建过程中,研究团队面临多重技术难题:首先需克服从结构化维基百科文本到自然对话的风格转换障碍,避免生成机械化的翻译腔调;其次,角色驱动方法要求生成具有连贯上下文的多轮对话,同时确保每个问题的自包含性;此外,数据生成过程还需平衡语言多样性控制与内容准确性,最大限度减少模型幻觉现象,并处理源数据与生成模型中固有的社会文化偏见问题。
常用场景
经典使用场景
在低资源语言模型开发领域,Bilik-Instruct数据集为阿塞拜疆语的自然语言处理任务提供了关键支持。其最经典的使用场景在于指令微调,通过包含多轮对话、问答、摘要和通用指令的多样化样本,研究人员能够训练模型生成更自然、符合本地语言习惯的响应。该数据集特别强调从百科全书式语言向日常对话风格的转变,使得模型在理解用户意图和生成上下文连贯的回复方面表现卓越,为构建高质量的阿塞拜疆语对话系统奠定了数据基础。
解决学术问题
该数据集有效解决了阿塞拜疆语作为低资源语言在人工智能研究中面临的数据稀缺问题。通过角色驱动的生成技术,它克服了传统合成数据往往存在的机械单调性,促进了语言模型在风格多样性和语境适应性方面的研究。其意义在于为少样本或零样本学习场景提供了丰富的监督信号,推动了跨语言模型迁移学习的发展,并对保护语言多样性、促进数字包容性产生了深远影响,为类似低资源语言的语料构建提供了可复制的范式。
衍生相关工作
围绕Bilik-Instruct数据集,已衍生出一系列专注于低资源语言模型优化的经典研究工作。这些工作主要探索如何利用其角色驱动架构来提升模型在特定领域(如文化、历史)的对话能力,以及如何将其与多语言预训练模型结合以实现更好的知识迁移。部分研究进一步分析了合成数据中幻觉和偏见问题的缓解策略,为该数据集在更安全、可靠的应用部署方面提供了方法论指导,同时也激励了针对其他类似语言构建高质量指令数据集的后续倡议。
以上内容由遇见数据集搜集并总结生成


