AbdomenAtlas 2.0
收藏arXiv2025-10-17 更新2025-11-05 收录
下载链接:
https://github.com/BodyMaps/AbdomenAtlas2.0
下载链接
链接失效反馈官方服务:
资源简介:
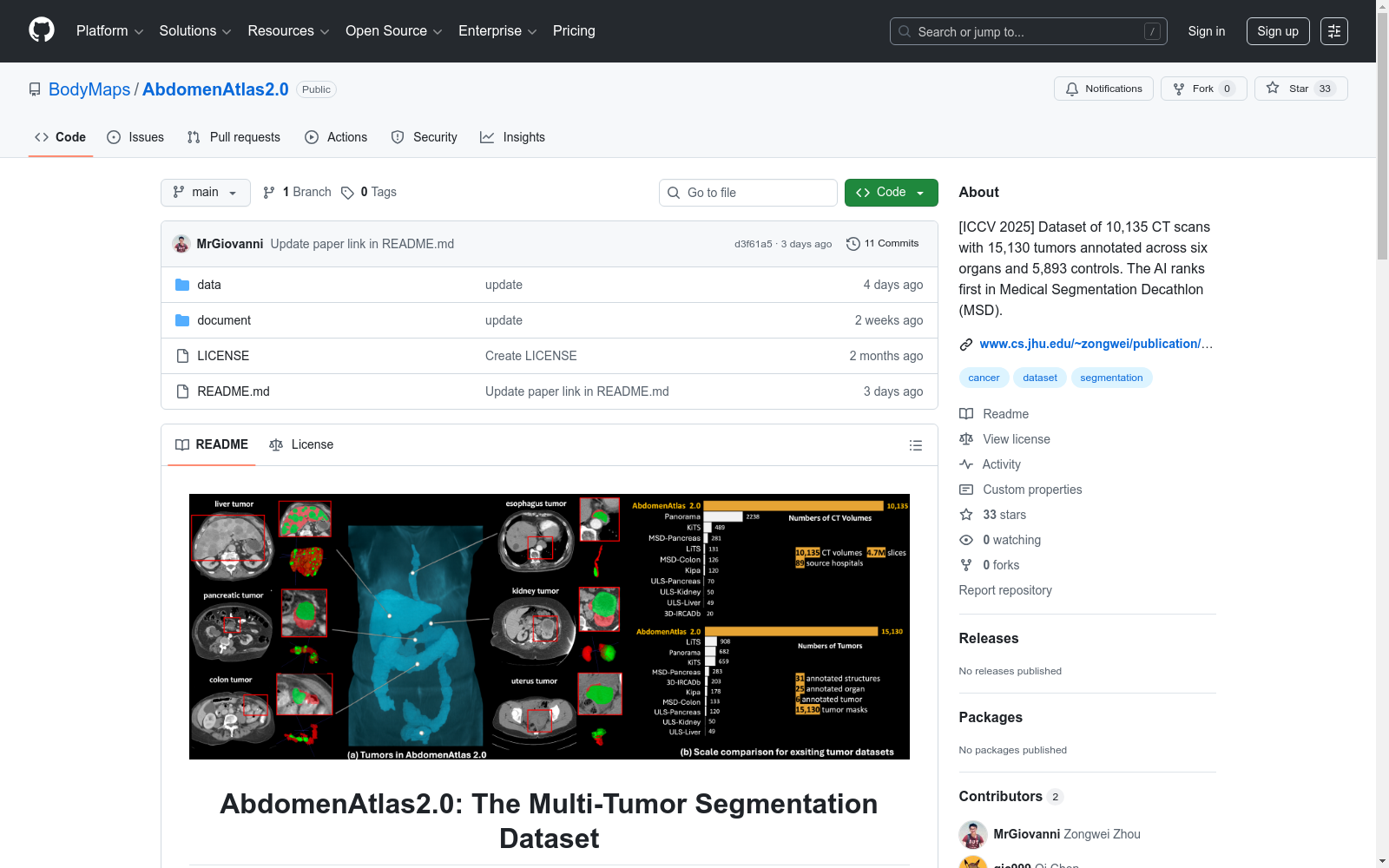
AbdomenAtlas 2.0是一个包含10135个CT扫描的大型数据集,涵盖六个器官(胰腺、肝脏、肾脏、结肠、食道和子宫)的肿瘤分割,并包含5,893个对照扫描。该数据集由23名放射科专家手动标注,比现有的公开肿瘤数据集大几个数量级。它提供了一个强大的基础,用于训练人工智能在六个器官中进行肿瘤分割,并在内部测试中实现了显著的改进。
AbdomenAtlas 2.0 is a large-scale dataset containing 10,135 CT scans, covering tumor segmentation annotations for six organs including the pancreas, liver, kidneys, colon, esophagus and uterus, and comprising 5,893 control scans. This dataset was manually annotated by 23 radiologists, and is several orders of magnitude larger than existing public tumor segmentation datasets. It provides a robust foundation for training AI models to perform tumor segmentation on these six organs, and has achieved remarkable performance improvements in internal validation tests.
提供机构:
约翰霍普金斯大学
创建时间:
2025-10-17
搜集汇总
数据集介绍
构建方式
在医学影像分析领域,构建大规模高质量标注数据集面临标注成本高昂的挑战。AbdomenAtlas 2.0采用创新的SMART-Annotator半自动标注流程,通过四个关键阶段实现高效标注:首先基于公开数据集训练器官特异性分割模型,随后通过FROC曲线分析确定最优敏感度阈值,接着由资深放射科医师审核AI生成的肿瘤候选区域以消除假阳性,最后由初级医师进行精细修订并经由资深医师最终确认。这套流程将单次扫描标注时间从传统手工标注的5分钟缩短至5秒,在保证超过90%敏感度的同时将假阳性率控制在每扫描1.2-2.4个的合理范围,显著提升了标注效率与质量。
特点
作为目前最大规模的人类标注肿瘤分割数据集,AbdomenAtlas 2.0展现出多维度优势:其包含10,135个CT扫描和4.7百万切片,涵盖肝脏、胰腺、肾脏、结肠、食管和子宫六种器官的15,130个肿瘤实例,规模超越现有公共肿瘤数据集总和。该数据集首次提供食管和子宫肿瘤的体素级标注,填补了罕见肿瘤研究空白。数据来源覆盖全球89家医院的多样化患者群体,肿瘤尺寸分布均衡,包含5,709个早期微小肿瘤(<20mm),为模型训练提供了丰富的形态学多样性。多阶段质量控制机制确保了标注精度,使其成为腹部多器官肿瘤研究的基准数据集。
使用方法
该数据集支持多种研究范式:对于分布内性能优化,建议采用500-1,500个真实扫描配合合成数据训练,可达到性能饱和状态;针对分布外泛化能力提升,需充分利用其多中心数据特性进行跨机构验证。具体实施时,研究者可基于ResEncM等先进架构,采用滑动窗口策略进行模型训练,通过测试时数据增强提升推理稳定性。数据集提供的六种肿瘤类型支持独立或联合训练模式,其丰富的早期肿瘤样本特别适合开发高灵敏度检测算法。在医学分割十项全能挑战中的领先表现验证了其在实际临床应用中的卓越价值。
背景与挑战
背景概述
AbdomenAtlas 2.0数据集由约翰斯·霍普金斯大学等机构于2025年联合创建,旨在解决医学影像中腹部肿瘤分割任务面临的数据稀缺问题。该数据集包含10,135例CT扫描数据,涵盖胰腺、肝脏、肾脏、结肠、食管和子宫六类器官的15,130个肿瘤实例,所有标注均由23名放射科专家通过半自动标注流程完成。其规模超越现有公共肿瘤数据集数个数量级,首次提供了食管与子宫肿瘤的体素级标注,为多器官肿瘤分割研究奠定了重要基础。
当前挑战
该数据集致力于应对腹部多器官肿瘤分割的泛化性挑战,尤其在早期小肿瘤检测和跨医疗机构数据分布差异方面存在显著难度。构建过程中面临标注效率瓶颈,传统体素级标注需耗费专家大量时间,通过开发SMART-Annotator智能标注系统将单例标注时间从5分钟压缩至5秒。数据多样性不足亦构成关键挑战,需从89家医院收集多中心数据以提升模型在分布外测试中的性能,而合成数据生成技术则成为突破标注成本限制的重要路径。
常用场景
经典使用场景
在医学影像分析领域,AbdomenAtlas 2.0数据集最经典的应用场景是作为腹部肿瘤分割模型的训练基准。该数据集包含来自89家医院的10,135例CT扫描数据,涵盖肝脏、胰腺、肾脏、结肠、食管和子宫六种器官的15,130个肿瘤实例,其规模远超现有公共数据集。研究人员利用该数据集训练深度学习模型时,能够显著提升模型在分布内测试中的分割精度,在医学分割十项挑战赛中取得领先性能。
衍生相关工作
该数据集的发布催生了多项重要衍生研究。基于其构建的ResEncM模型在MSD挑战赛中超越通用模型获得第一,在六种肿瘤分割任务中分别实现1.4%-7.3%的DSC提升。同时,数据集支撑的DiffTumor合成肿瘤生成方法证明,将合成数据与真实数据结合训练可使模型仅用40%-60%的真实标注数据即可达到性能饱和,为数据高效学习开辟了新途径。
数据集最近研究
最新研究方向
在腹部肿瘤分割领域,AbdomenAtlas 2.0数据集正推动基于真实与合成数据融合的规模化学习研究。该数据集通过整合来自89家医疗机构的10,135例CT扫描数据,突破了传统数据标注的瓶颈,揭示了数据规模与模型性能间的非线性关系。前沿研究聚焦于利用合成肿瘤数据优化模型训练效率,实验表明仅需500例真实扫描配合合成数据即可达到1,500例纯真实数据的性能水平,显著降低了标注成本。同时,该数据集首次公开的食管与子宫肿瘤体素级标注,为罕见肿瘤的算法研究提供了新范式。跨中心验证表明,基于该数据集的模型在外部数据上的泛化性能提升达14%DSC,凸显了数据多样性对临床部署的关键价值。
相关研究论文
- 1通过约翰霍普金斯大学 · 2025年
以上内容由遇见数据集搜集并总结生成


