collectivat/amazic
收藏Hugging Face2025-02-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/collectivat/amazic
下载链接
链接失效反馈官方服务:
资源简介:
该存储库包含由Col·lectivaT与CIEMEN合作创建,并得到巴塞罗那市政府和加泰罗尼亚政府资助的多种Tamazight语言数据集。数据集分为单语和双语两部分,单语部分包括语言学习材料和IRCAM文本语料库中的句子,双语部分包括从AWAL贡献中提取的数据、Tatoeba.org的句子转写、Tamazight谚语的加泰罗尼亚语翻译以及Common Voice本地化的英-Tamazight平行语段。
This repository houses multilingual Tamazight language datasets developed in collaboration between Col·lectivaT and CIEMEN, with funding support from the Barcelona City Council and the Government of Catalonia. The datasets are divided into two core categories: monolingual and bilingual. The monolingual category includes language learning materials and sentences sourced from the IRCAM text corpus. The bilingual category comprises data extracted from AWAL contributions, sentence transcriptions from Tatoeba.org, Catalan translations of Tamazight proverbs, and English-Tamazight parallel segments localized for Common Voice.
提供机构:
collectivat
原始信息汇总
数据集概述
基本信息
- 名称: Tamazight语言数据
- 许可证: cc-by-2.0
- 语言: zgh, fr, ca, en, es, ary, ar
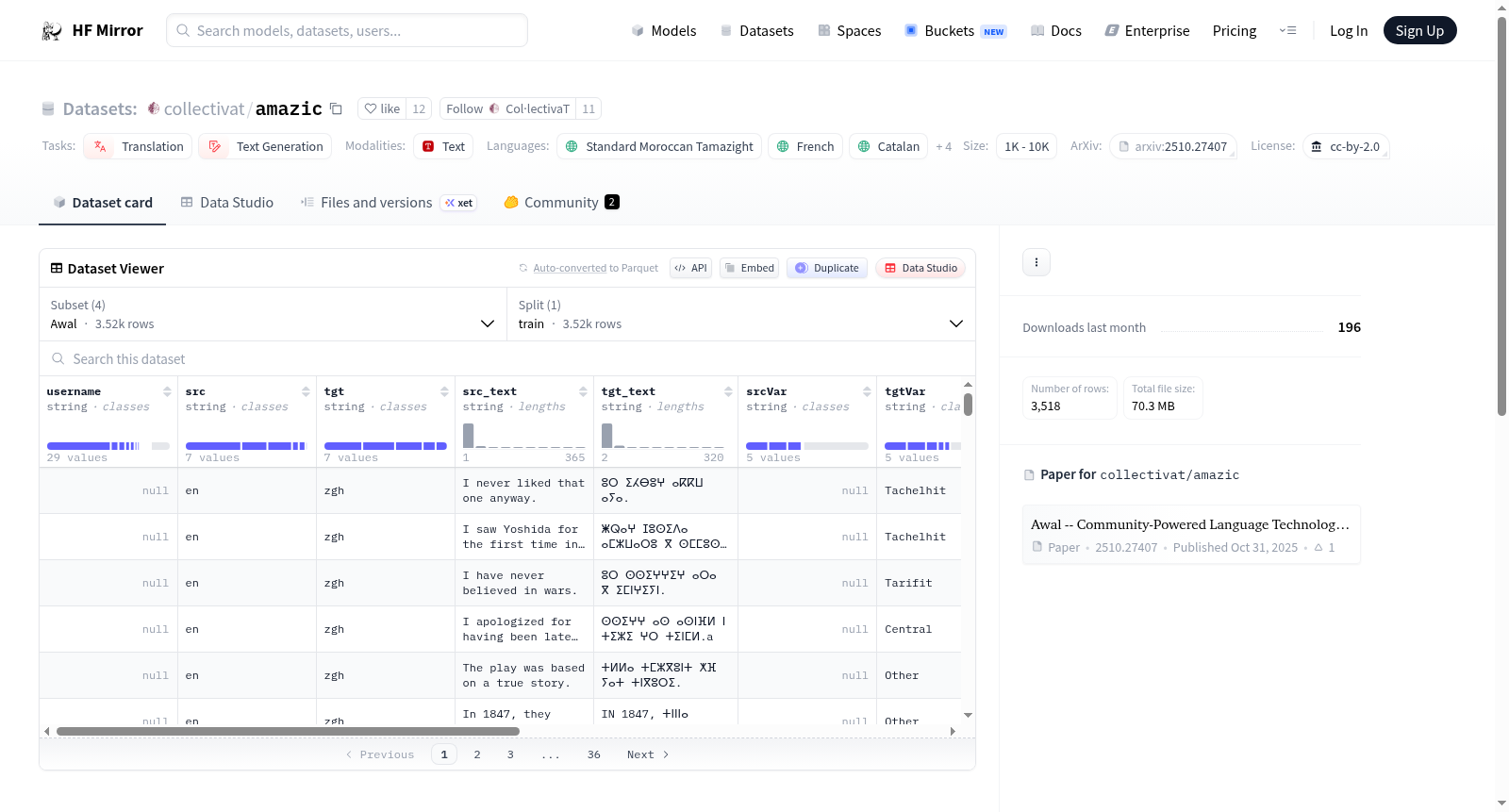
数据文件配置
- Awal:
- 配置名称: Awal
- 数据文件: parallel/awal/raw-dumps/Contribution-24.03.14.json
- 默认: true
- IRCAM-clean-tifinagh:
- 配置名称: IRCAM-clean-tifinagh
- 数据文件: mono/IRCAM-clean-tifinagh.txt
- tc_wajdm_v1:
- 配置名称: tc_wajdm_v1
- 数据文件: mono/tc_wajdm_v1.txt
- CV-localization:
- 配置名称: CV-localization
- 数据文件: parallel/CV-localization/pontoon-CV-zgh-en.tsv
任务类别
- 翻译
- 文本生成
数据集大小
- 范围: 100K<n<1M
数据集内容
- 单语数据:
- tc_wajdm_v1.txt: 来自语言学习材料“tc wawjdm”的文本。
- IRCAM-clean-tifinagh.txt: 从IRCAM的文本语料库中提取的Tifinagh脚本句子。
- 平行语料:
- AWAL: 从AWAL提取的数据。
- tatoeba-translit: Tatoeba.org的平行句子,使用Python脚本转写为Tifinagh。
- proverbs: Tamazight谚语及其加泰罗尼亚语翻译。
- CV-localization: 从Pontoon提取的Common Voice本地化项目中的英文和Tamazight段落。
搜集汇总
数据集介绍
构建方式
在语言资源稀缺的背景下,Amazic数据集通过多源整合与协作构建而成。该数据集汇集了来自语言学习材料、学术机构文本库以及社区贡献的平行语料,涵盖了单语与双语文本。具体而言,单语部分从IRCAM文本库中提取并转换为提非纳文字符,双语部分则整合了AWAL平台的用户贡献、Tatoeba.org的转写句子以及谚语翻译。数据构建过程注重原始来源的多样性与脚本的统一处理,体现了对塔马齐格特语资源的系统性收集与整理。
特点
Amazic数据集展现了塔马齐格特语资源的丰富性与多维度特征。其语料覆盖提非纳文、法文、加泰罗尼亚文等多种语言变体,支持翻译与文本生成任务。数据集不仅包含日常用语与谚语,还涉及技术文档与界面本地化内容,如Common Voice和Telegram的翻译片段。这种跨领域、多脚本的语料组合,为研究低资源语言的机器翻译与自然语言处理提供了独特的实验基础。
使用方法
针对塔马齐格特语的自然语言处理研究,Amazic数据集可通过配置灵活调用。用户可根据任务需求选择单语或平行语料配置,例如使用IRCAM-clean-tifinagh进行语言建模,或采用AWAL平行数据进行翻译模型训练。数据集以标准文本格式提供,支持直接加载至主流机器学习框架。对于本地化研究,CV-localization等子集可服务于跨语言界面适配分析,为低资源语言技术开发提供实证支持。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的数据稀缺问题长期制约着相关技术的发展。针对这一挑战,由Col·lectivaT组织主导,联合CIEMEN机构,并在巴塞罗那市议会与加泰罗尼亚政府资助下,于近年创建了Amazic数据集。该数据集聚焦于塔马齐格特语(Tamazight)及其变体,核心研究问题在于为这一北非本土语言构建高质量、多用途的语料资源,以支持机器翻译、文本生成等任务。它的出现,为塔马齐格特语的数字化保存与计算语言学应用提供了关键基础设施,对促进语言技术公平性与文化多样性具有深远影响。
当前挑战
该数据集旨在解决塔马齐格特语在机器翻译与文本生成等任务中面临的数据匮乏根本性挑战。具体而言,挑战体现在两方面:其一,领域问题层面,塔马齐格特语作为低资源语言,其方言变体多、书写系统(如提非纳文)数字化程度低,导致模型训练面临严重的语料稀疏与表征学习困难。其二,构建过程层面,数据收集面临来源分散、质量参差的困境,例如需从IRCAM语料库、AWAL平台贡献内容及各类本地化文件中进行提取、清洗与对齐,并处理不同脚本间的转写与验证问题,确保平行语料的准确性与一致性。
常用场景
经典使用场景
在自然语言处理领域,低资源语言的研究常面临数据稀缺的挑战。Amazic数据集通过整合多种塔马齐格特语(Tamazight)的平行语料与单语文本,为机器翻译与文本生成任务提供了关键资源。该数据集典型应用于训练跨语言模型,尤其在柏柏尔语族语言与法语、英语、加泰罗尼亚语等之间的翻译系统构建中,支持从传统提非纳文字到现代拉丁字母的转换研究,促进了语言技术的文化适应性发展。
解决学术问题
该数据集有效应对了低资源语言在计算语言学中的代表性不足问题。通过汇集IRCAM语料库的提非纳文文本、AWAL平台的数字贡献内容以及本地化界面翻译,它解决了塔马齐格特语在机器翻译、语言模型预训练及文字标准化研究中缺乏高质量标注数据的问题。其多脚本、多领域的语料结构为语言技术中的形态学分析、跨文字转换及语言资源均衡化提供了实证基础,推动了语言多样性在人工智能领域的学术探索。
衍生相关工作
围绕该数据集衍生的经典工作包括多语言神经机器翻译系统的优化研究,特别是在低资源场景下的跨文字迁移学习。例如,基于AWAL贡献数据与Tatoeba句对的研究推动了提非纳文-拉丁文转换器的开发;结合IRCAM语料的工作深化了柏柏尔语族语言的形态学建模。此外,数据集支撑了如《Awal TICAM'26》等学术论文中的语言资源分析,为后续的塔马齐格特语语言模型预训练及数字工具本地化项目提供了可扩展的基准。
以上内容由遇见数据集搜集并总结生成


