simarora/ConcurrentQA
收藏数据集概述
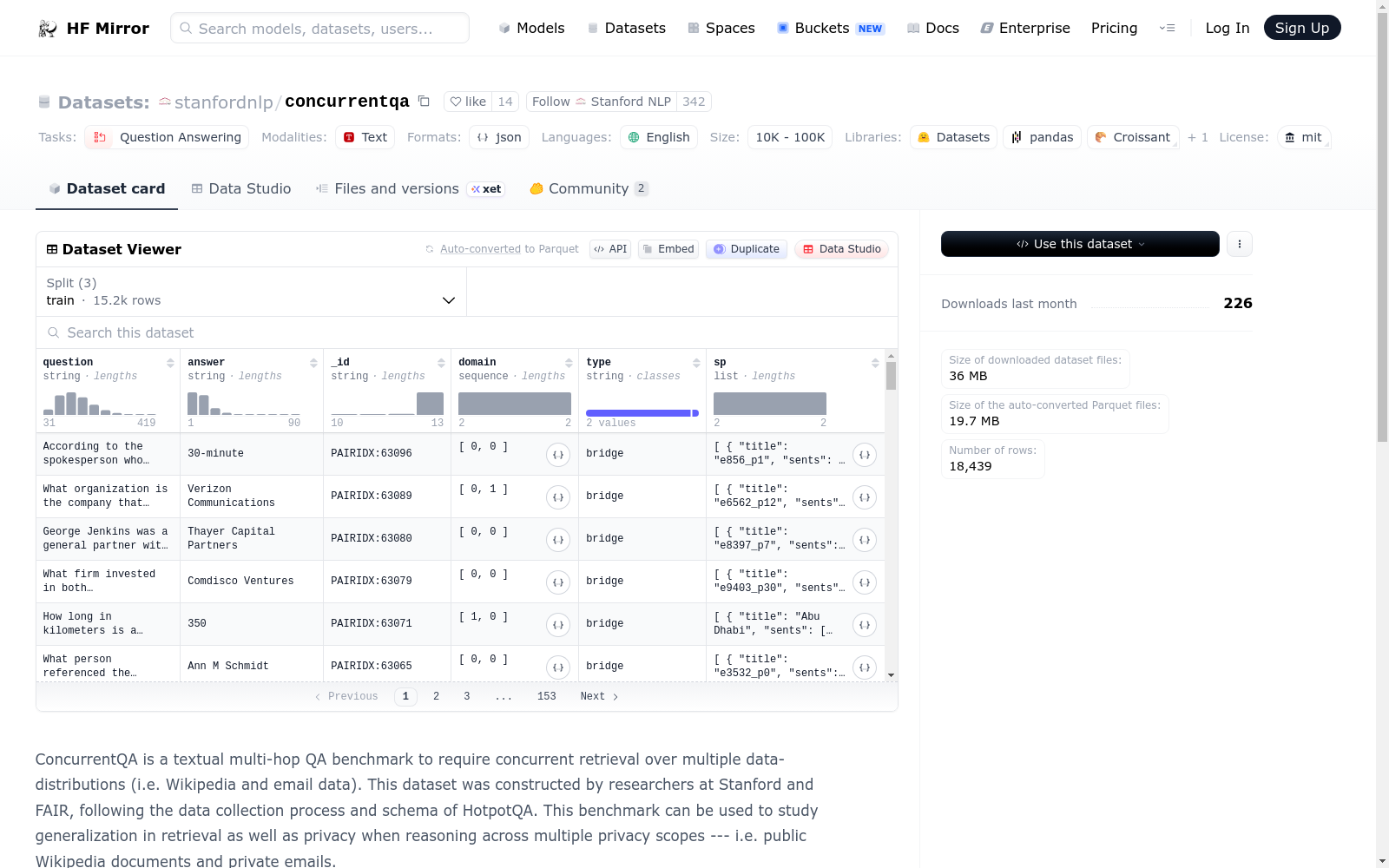
名称: ConcurrentQA
类型: 文本多跳问答基准
目的: 该数据集旨在要求在多个数据分布(如Wikipedia和电子邮件数据)上进行并发检索,用于研究检索中的泛化能力以及跨多个隐私范围(公共Wikipedia文档和私人电子邮件)进行推理时的隐私问题。
构建者: 由斯坦福大学和FAIR的研究人员构建
数据收集和架构: 遵循HotpotQA的数据收集过程和架构
任务:
- 主要任务: 问答(Question-Answering)
- 相关任务: 检索(Retrieval),相关数据集可在此处找到:ConcurrentQA-Retrieval
语言: 英语(en)
许可证: MIT
数据下载命令: bash cd .. mkdir corpora cd corpora
wget https://dl.fbaipublicfiles.com/concurrentqa/corpora/enron_only_corpus.json wget https://dl.fbaipublicfiles.com/concurrentqa/corpora/combined_corpus.json wget https://dl.fbaipublicfiles.com/concurrentqa/corpora/wiki_only_corpus.json wget https://dl.fbaipublicfiles.com/concurrentqa/corpora/title2sent_map.json
相关资源:
- 模型训练和结果分析代码可在ConcurrentQA GitHub仓库找到。
引用: bibtex @article{arora2023reasoning, title={Reasoning over Public and Private Data in Retrieval-Based Systems}, author={Simran Arora and Patrick Lewis and Angela Fan and Jacob Kahn and Christopher Ré}, year={2023}, journal={Transactions of the Association for Computational Linguistics}, }