qpl-multi-decomposer-fixed-ds
收藏Hugging Face2026-05-16 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/d4nieldev/qpl-multi-decomposer-fixed-ds
下载链接
链接失效反馈官方服务:
资源简介:
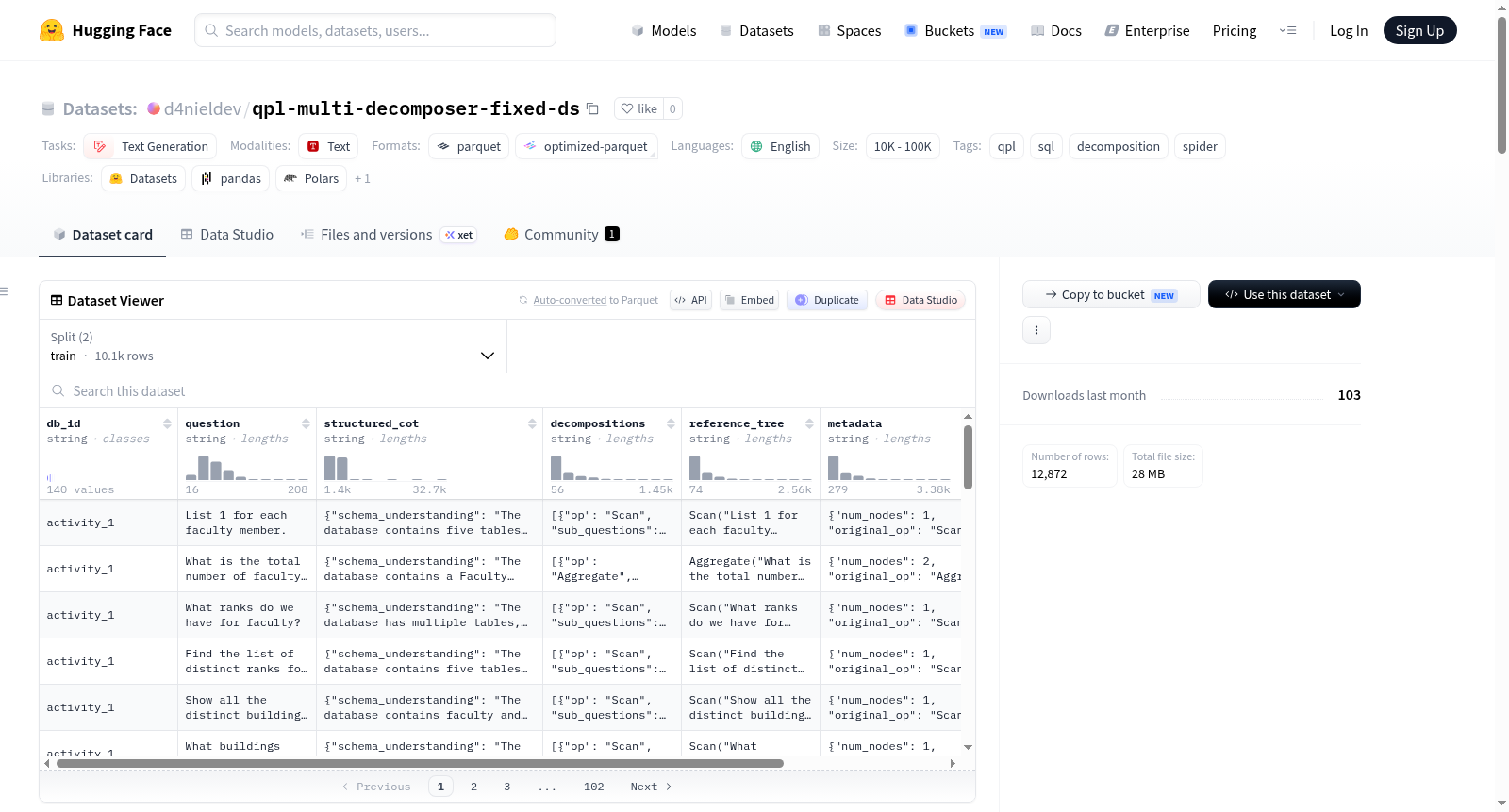
QPL Multi-Decomposer Dataset — Fixed 是一个经过人工审查和清理的文本生成数据集,专门用于查询规划语言(QPL)的分解任务。该数据集基于 Spider 数据库,旨在通过链式思维推理和多操作符分解,将自然语言问题转化为结构化的查询规划。数据集包含训练集(10,143 个样本)和验证集(2,729 个样本),总计超过 12,800 个样本。每个样本包含 7 个关键字段:数据库标识(db_id)、自然语言问题(question)、结构化的链式思维推理(structured_cot,以 JSON 字符串形式包含模式理解和 9 种 QPL 操作符的探索过程)、所有有效的顶层分解列表(decompositions,JSON 字符串)、参考 QPL 树(reference_tree)、元数据(metadata)以及 QPL 表达式(qpl)。数据集的核心改进在于对原始 LLM 生成数据中约 25% 的训练样本进行了人工审查,识别并移除了 22.4% 的无效分解(如牵强的“NOT X” Except、冗余的自连接等),并重写了这些无效操作的推理链为拒绝解释。修改后,训练集中操作符的分布为:Scan(5,524)、Filter(4,333)、Join(3,624)、Aggregate(2,185)、Except(1,105)、TopSort(565)、Intersect(557)、Sort(293)、Union(224)。验证集则保持原始版本不变,作为保留评估数据。该数据集适用于训练和评估文本到 SQL 分解模型、查询规划生成模型以及多步推理系统。
The QPL Multi-Decomposer Dataset — Fixed is a human-reviewed and curated text generation dataset dedicated to Query Planning Language (QPL) decomposition tasks. Built upon the Spider database, this dataset aims to convert natural language questions into structured query plans via Chain-of-Thought (CoT) reasoning and multi-operator decomposition. It comprises a training set (10,143 samples) and a validation set (2,729 samples), with a total of over 12,800 samples. Each sample contains 7 key fields: database ID (db_id), natural language question (question), structured Chain-of-Thought reasoning (structured_cot, a JSON string containing schema understanding and the exploration process of 9 QPL operators), list of all valid top-level decompositions (decompositions, JSON string), reference QPL tree (reference_tree), metadata, and QPL expression (qpl). The core improvement of this dataset is realized through human review of approximately 25% of the training samples from the raw LLM-generated data: 22.4% of invalid decompositions (such as far-fetched "NOT X" Except clauses, redundant self-joins, etc.) were identified and removed, and the reasoning chains of these invalid operations were rewritten into rejection explanations. After modification, the operator distribution in the training set is as follows: Scan (5,524), Filter (4,333), Join (3,624), Aggregate (2,185), Except (1,105), TopSort (565), Intersect (557), Sort (293), Union (224). The validation set remains unchanged from the original version, serving as the held-out evaluation data. This dataset is applicable for training and evaluating text-to-SQL decomposition models, query planning generation models, and multi-step reasoning systems.
创建时间:
2026-05-02
搜集汇总
数据集介绍
构建方式
该数据集源自于对原始数据集 `d4nieldev/qpl-multi-decomposer-ds` 的细致人工审查与修正。原始训练集由大语言模型生成,存在若干系统性的分解错误。为此,研究团队对所有包含 `Scan` 及其他至少一种运算符的样本行(共计 2,524 行,约占训练集的 25%)进行了逐一审核,并依据严谨的评判标准将每个分解标记为 `VALID`、`BORDERLINE` 或 `INVALID`。审核过程中,团队识别并剔除了诸如“NOT X”矫揉造作的 Except、同一表的主键自连接等十余种典型无效模式。对于被移除的分解,其在 `decompositions` 字段中被彻底删除,同时在 `structured_cot` 中保留了该运算符的推理块,但将其重写为简洁的拒绝解释,并移除了仅适用于有效分解的 `<analysis>` 与 `<confidence>` 标签。最终,共有 737 行被修改,980 个无效分解被移除,显著提升了数据纯净度。
使用方法
该数据集专为文本生成任务设计,尤其适用于训练和评估能够进行结构化推理的文本到SQL模型。在使用时,用户可直接通过 Hugging Face Datasets 库加载 `default` 配置下的 `train` 和 `validation` 两个数据分割。模型可以以 `question` 字段为输入,以 `structured_cot` 和 `decompositions` 字段作为监督信号,学习逐步推理并生成有效的 QPL 分解。研究实践表明,可通过构建序列到序列模型,将自然语言问题映射至包含链式推理和分解表达式的文本形式。由于数据集中已明确区分了有效分解与拒绝理由,训练过程中可以设计损失函数以惩罚无效分解的生成,从而提升模型对分解正确性的辨别能力。此外,`reference_tree` 字段提供了标准的教师信号,支持进行知识蒸馏或对比学习等高级训练范式。
背景与挑战
背景概述
在自然语言处理与数据库交叉领域,将自然语言问题转化为可执行的SQL查询是语义解析(Semantic Parsing)的核心任务之一。近年来,基于查询计划语言(QPL)的分解策略为复杂查询提供了结构化的中间表示,但现有数据集常依赖大语言模型自动生成,其逻辑一致性与语义准确性存在显著缺陷。qpl-multi-decomposer-fixed-ds数据集应运而生,由匿名研究团队于2023年创建,旨在修正原始版本中因LLM生成而广泛存在的错误分解模式。该数据集基于经典Spider基准进行了人工审查与清洗,通过剔除无效分解并重写链式推理拒绝解释,提升了训练数据的可信度。其发布不仅为QPL驱动的查询分解研究提供了高质量的标注资源,还强调了人工干预在自动化数据集构建中的关键作用,对语义解析领域的数据质量控制具有示范意义。
当前挑战
核心挑战在于解决自然语言问题到查询分解的结构化映射问题。领域层面,现有的LLM自动分解方法易产生语义错误或结构冗余的分解模式,例如引入无意义的“NOT X”求反操作、基于主键的自连接、以及复杂度倒置的子查询,这些错误会误导模型学习错误的逻辑拆解策略,进而降低下游SQL生成的准确率。数据集构建过程中,研究团队面临大规模错误模式分类与清洗的挑战:在10,143条训练样本中,需对约25%的候选行逐一审查,最终识别并移除980个无效分解,同时保持解析后的链式推理文本逻辑连贯。此外,验证集保留原始未修正版本,要求模型能适应训练集与验证集间的质量差异,增加了评估的复杂性。
常用场景
经典使用场景
该数据集是为文本到SQL(Text-to-SQL)任务中查询计划分解(Query Plan Decomposition)而精心构建的监督学习资源。它以Spider数据集为基础,将自然语言问题与对应的结构化SQL查询计划分解相关联,旨在训练模型理解复杂查询的层次化逻辑结构。经典的使用方式是将`question`字段作为输入,引导模型生成包含多个算子(如Scan、Filter、Join等)的分解序列及其子问题,并借助`structured_cot`字段中的思维链推理过程,实现从自然语言到多步执行计划的精准映射。
解决学术问题
该数据集直面Text-to-SQL领域中多步骤查询计划预测质量参差不齐的困境,尤其聚焦于分解过程中的语义一致性与结构合理性。通过人工审核并剔除大量无效分解(如冗余的自连接、伪投影聚合等),它显著提升了训练标签的纯净度,有效缓解了自动生成数据中常见的错误传播问题。此举为研究复杂的SQL子任务分解策略、算子选择的可解释性和推理链的鲁棒性奠定了基础,推动了模型在跨领域复杂查询推理上的泛化能力。
实际应用
在实际应用中,该数据集支撑了智能数据库查询接口的研发,使用户能够以自然语言直接与关系型数据库交互,尤其适用于商业智能分析、数据报表自动生成和学术数据库搜索等场景。通过将用户问题分解为可执行的SQL子任务,系统能透明地展示查询意图与执行路径,增强结果的可解释性。同时,该数据集的精确标注也有助于优化教育领域的SQL教学辅助工具,帮助学习者理解复杂查询的结构化表达。
数据集最近研究
最新研究方向
在文本到SQL解析与查询计划分解的前沿探索中,该数据集聚焦于语义复杂度消解与逻辑算子质量校准。通过系统性标注和修正多分解器生成的SQL查询计划,特别是针对无效分解模式如“NOT X”异常、自连接冗余及投影虚假聚合等问题进行人工审查与链式思维重写,该研究推动了结构化推理的鲁棒性提升。相关工作与Spider Benchmark等跨领域NL2SQL任务紧密关联,旨在通过高保真度的分解信号增强模型对复杂查询的泛化能力,其清理后的训练数据为构建可信赖的语义解析基线提供了关键支撑,对知识库查询优化及自然语言交互系统具有奠基性意义。
以上内容由遇见数据集搜集并总结生成


