relsim
收藏Relational Visual Similarity 数据集概述
基本信息
- 数据集名称:Relational Visual Similarity (relsim)
- 发布年份:2025
- 发布平台:arXiv
- 论文标题:Relational Visual Similarity
- 论文链接:https://arxiv.org/abs/2512.07833
- 代码仓库:github/relsim
- HuggingFace数据集:HuggingFace Dataset
- 数据查看器:Data Viewer
- 定性展示:Qualitative Gallery
- 图像检索演示:Image Retrieval
核心概念
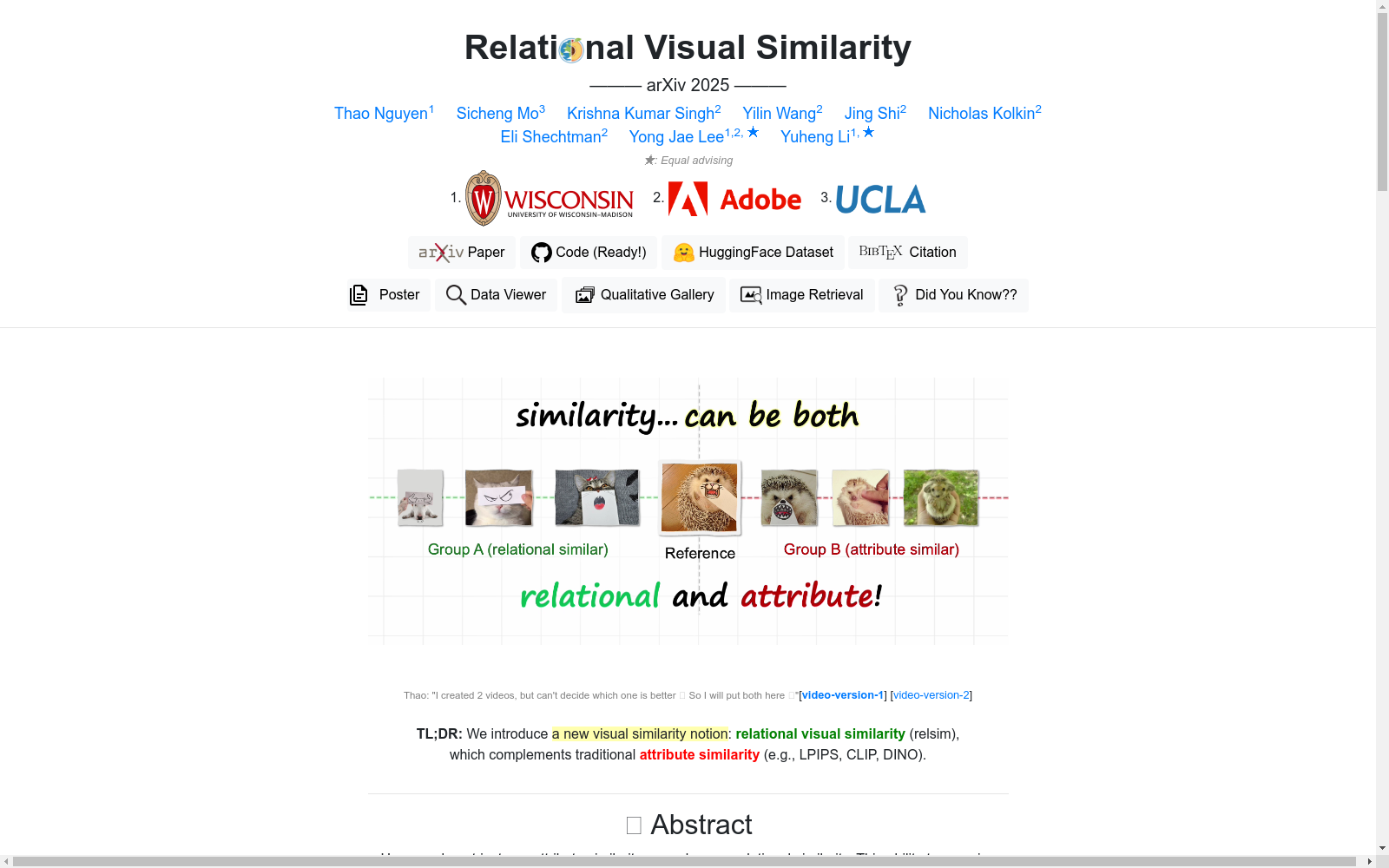
- 关系视觉相似性 (relational visual similarity, relsim):一种新的视觉相似性概念,关注图像内部视觉元素之间的关系或功能的对应性,即使视觉属性不同。
- 属性相似性 (attribute similarity):传统视觉相似性度量(如LPIPS, CLIP, DINO)关注的内容,侧重于感知属性相似性。
数据集内容
- 规模:包含114k+图像-描述对。
- 描述特点:描述是匿名的,描述场景的底层关系逻辑而非表面内容。
- 数据组成部分:
- 种子组 (Seed Groups):500+ {图像组,匿名描述}。
- 匿名描述 (Anonymous Captions):114k+ {图像,匿名描述}。
- 数据集链接:
- 种子组:datasets/seed-groups
- 匿名描述:datasets/anonymous-captions-114k
模型与工具
-
模型:基于该数据集微调的视觉语言模型,用于度量图像间的关系相似性。
-
Python包:
relsim -
安装:
pip install relsim -
预训练模型:
thaoshibe/relsim-qwenvl25-lora -
快速使用示例: python from relsim.relsim_score import relsim from PIL import Image
model, preprocess = relsim( pretrained=True, checkpoint_dir="thaoshibe/relsim-qwenvl25-lora")
img1 = preprocess(Image.open("image_path_1")) img2 = preprocess(Image.open("image_path_2")) similarity = model(img1, img2) print(f"relsim score: {similarity:.3f}")
应用与展示
- 定性展示库:展示了基于属性度量(如LPIPS, CLIP, DINO)和基于关系度量(relsim)的图像检索结果对比。
- 数据查看器:提供数据集中使用的数据集的查看界面。
引用信息
bibtex @misc{nguyen2025relationalvisualsimilarity, title={Relational Visual Similarity}, author={Thao Nguyen and Sicheng Mo and Krishna Kumar Singh and Yilin Wang and Jing Shi and Nicholas Kolkin and Eli Shechtman and Yong Jae Lee and Yuheng Li}, year={2025}, eprint={2512.07833}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2512.07833}, }
- 1Relational Visual Similarity威斯康星大学麦迪逊分校, 加州大学洛杉矶分校, Adobe研究院 · 2025年


