covid_qa
收藏Hugging Face2025-01-30 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/manu/covid_qa
下载链接
链接失效反馈官方服务:
资源简介:
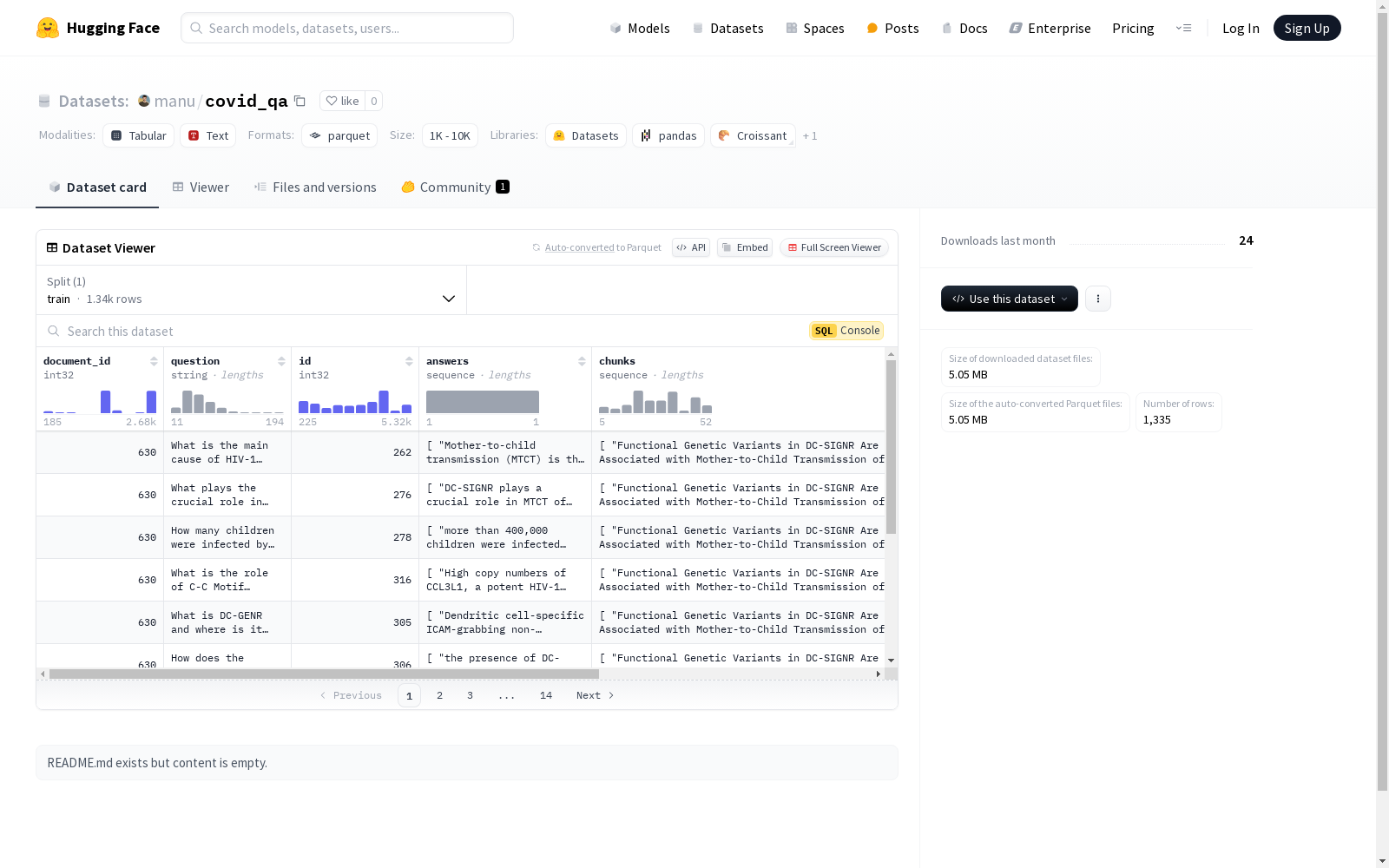
该数据集包含多个特征,包括文档ID、问题、ID、答案、文本块、正确文本块、单词数量和标记数量。数据集分为一个训练集,包含1335个样本,总大小为43249481.2332838字节。数据集的下载大小为5047983字节。
This dataset includes multiple features, including document ID, question, ID, answer, text chunk, correct text chunk, word count, and token count. The dataset is split into a training set containing 1335 samples, with a total size of 43249481.2332838 bytes. The download size of this dataset is 5047983 bytes.
创建时间:
2025-01-30
搜集汇总
数据集介绍
构建方式
在构建covid_qa数据集的过程中,开发者精心选取了与COVID-19相关的问答对,其中每个样本包含问题、答案、文档片段及其在文档中的正确位置等字段。该数据集通过整合互联网资源及专业知识库,经过严格的清洗、去重和标注流程,最终形成了包含1335个训练样本的集合,旨在为机器阅读理解任务提供针对性的训练资源。
特点
covid_qa数据集以其针对性和实用性为显著特点,专门针对COVID-19疫情相关的问答设计,覆盖了疫情知识的多个方面。数据集不仅提供了问题与答案的对齐,还包含了答案在文档中的具体位置信息,这对于训练和评估模型在特定领域内的信息提取能力具有重要价值。此外,数据集的构建注重质量,避免了重复和错误信息的干扰。
使用方法
用户在使用covid_qa数据集时,可以首先通过HuggingFace提供的接口轻松下载数据。之后,用户可以按照数据集的划分,将数据用于模型的训练、验证和测试。数据集中的字段设计使得其易于与其他NLP工具和模型集成,从而方便研究者在不同的应用场景中进行定制化和扩展性的研究。
背景与挑战
背景概述
covid_qa数据集是在新冠疫情背景下应运而生的研究资源,旨在为自然语言处理领域提供一份针对新冠疫情相关问题的问答数据集。该数据集由多个研究人员和机构共同创建于2020年,核心研究问题是如何利用自然语言处理技术高效准确地解答公众关于新冠病毒的疑问。covid_qa数据集的构建,不仅为研究人员提供了实验平台,而且对提升公共卫生信息传播效率和精准度具有重要意义,对相关领域产生了显著的影响力。
当前挑战
covid_qa数据集面临的挑战主要体现在两个方面:一是领域问题的挑战,即如何确保自然语言处理模型能够准确理解和回应复杂多变的疫情相关问题;二是构建过程中的挑战,包括如何快速收集和整合大量疫情相关信息,以及如何客观准确地标注正确答案,保障数据集的质量和可用性。
常用场景
经典使用场景
在信息检索领域,'covid_qa'数据集被广泛用于构建和评估针对COVID-19相关问题的问答系统。该数据集提供了问题与答案的配对,以及支持答案的文本片段,便于研究者训练模型理解和回应用户关于COVID-19的疑问。
实际应用
在实际应用中,基于'covid_qa'数据集开发的问答系统可以部署在医疗健康咨询平台、政府官方网站等,为公众提供自动化的COVID-19信息咨询服务,减轻专业人士的工作负担,提高信息传播的效率。
衍生相关工作
'covid_qa'数据集的问世催生了众多关于疫情信息检索、自然语言处理和机器学习的研究成果。研究者们基于此数据集,发表了关于问答系统性能优化、知识图谱构建等领域的学术论文,为相关领域的发展提供了重要的研究基础。
以上内容由遇见数据集搜集并总结生成


