reddit-ethics
收藏Hugging Face2025-04-24 更新2025-04-25 收录
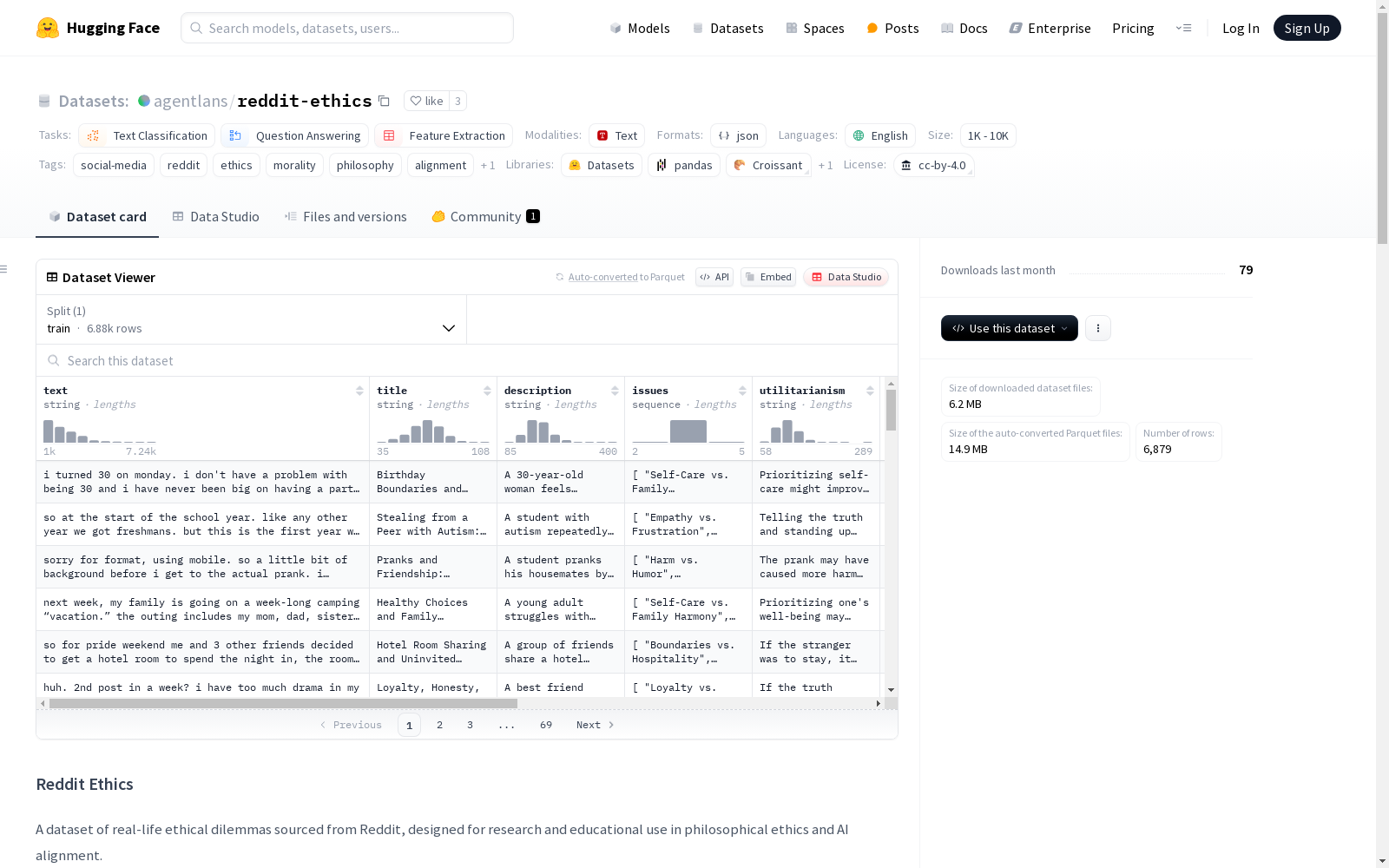
下载链接:
https://huggingface.co/datasets/agentlans/reddit-ethics
下载链接
链接失效反馈官方服务:
资源简介:
Reddit伦理数据集是一个收集自Reddit的关于个人道德困境的实际世界帖子数据集,每个条目都格式化为一个案例研究,包含讨论问题、样本答案和建议解决方案,旨在为分析日常情境中的道德推理、伦理框架和AI对齐提供资源。
The Reddit Ethics Dataset is a real-world post dataset focused on personal moral dilemmas collected from Reddit. Each entry is formatted as a case study, containing the discussed question, sample answers, and recommended solutions. It aims to serve as a resource for analyzing moral reasoning, ethical frameworks, and AI alignment in everyday scenarios.
创建时间:
2025-04-23
搜集汇总
数据集介绍
构建方式
在数字人文与计算伦理学的研究背景下,reddit-ethics数据集通过多阶段构建流程实现了真实伦理困境的系统化采集。该数据集以Reddit平台中长度超过1000字符的10000篇帖子为原始素材,采用分层抽样策略确保案例多样性。初始阶段通过人工筛选5个种子案例进行结构化标注,随后基于Llama3.1-LexiHermes-SuperStorm模型进行少样本提示生成,完整保留了原始社区讨论的语境特征,同时系统整合了三大伦理学流派的规范性分析框架。
特点
作为社交媒体伦理研究的代表性语料库,该数据集最显著的特征在于其多维度的注释体系。每个案例不仅包含原始文本和摘要性标题,更创新性地植入了功利主义、义务论与德性伦理的三维分析视角,配合讨论问题与参考答案形成闭环研究单元。数据条目中明确标注的伦理冲突标签,如'共担责任与个人投入'等,为道德推理的量化研究提供了可操作的分类维度,而建议解决方案字段则体现了不同伦理理论在实践中的调和可能。
使用方法
该数据集在人工智能伦理对齐研究中具有多重应用价值。研究者可直接调用结构化字段进行道德立场分类实验,或通过对比三大伦理学流派的注释差异构建道德推理模型。教育领域可采用案例库中的讨论问题开展伦理学研讨,而答案字段可作为监督学习的基准参考。需注意使用时应结合文化背景分析潜在偏差,对于模型生成的注释内容建议通过交叉验证确保可靠性,同时充分利用分辨率字段进行伦理决策的可解释性研究。
背景与挑战
背景概述
Reddit Ethics数据集于近年由OsamaBsher等研究者构建,旨在为哲学伦理学和人工智能对齐研究提供真实世界的伦理困境案例。该数据集源自Reddit平台上的用户讨论,通过系统化整理日常生活中的道德两难情境,为分析道德推理、伦理框架及AI对齐问题提供了丰富素材。其核心研究问题聚焦于如何将传统哲学伦理学的理论范式应用于现代社会的复杂道德场景,尤其在跨文化语境和群体决策中的适用性。数据集采用功利主义、义务论和德性伦理学三大经典理论体系进行标注,为伦理学研究提供了结构化分析工具,对推动计算伦理学发展具有显著影响。
当前挑战
该数据集面临的挑战主要体现在领域问题和构建过程两个维度。在领域问题方面,网络语境下的伦理讨论常掺杂非理性因素,如何区分真实道德困境与社交沟通问题成为关键挑战;同时,西方个体主义视角的局限性难以覆盖多元文化背景下的伦理判断差异。构建过程中,数据来源局限于单一子论坛导致样本代表性不足,语言模型标注可能引入隐性偏见,且短文本形式制约了哲学分析的深度。此外,案例中社会文化因素与纯粹伦理问题的交织,以及专业领域伦理(如生物伦理)的缺失,都对该数据集的应用边界形成挑战。
常用场景
经典使用场景
在伦理哲学与人工智能对齐研究领域,reddit-ethics数据集通过真实场景的伦理困境案例,为学者提供了丰富的分析素材。该数据集最经典的使用场景是作为教学工具,在高校哲学课程中引导学生运用功利主义、义务论和德性伦理三大理论框架进行案例分析,培养系统性伦理推理能力。其结构化的问题设计和高频次讨论话题,特别适合用于比较不同伦理学派在现实矛盾中的解释力差异。
实际应用
在应用层面,该数据集已被用于开发道德决策支持系统,特别是在社区调解和家庭咨询场景中。心理咨询师借助案例库中的多视角分析模板,帮助冲突双方理解彼此立场的伦理依据。科技公司则利用这些标注数据训练AI识别在线讨论中的道德争议点,为内容审核系统提供伦理维度评估参考。部分法律诊所也开始采用类似案例进行调解员培训。
衍生相关工作
基于该数据集衍生的经典工作包括《基于多伦理框架的冲突调解模式评估》等实证研究,这些研究建立了网络道德讨论与理论伦理学之间的桥梁。在技术领域,MIT媒体实验室开发的EthicsNet基准测试直接采用了该数据集的标注体系。近期发布的MoralBERT模型也以其作为微调数据,实现了对复杂道德语境的理解能力突破。
以上内容由遇见数据集搜集并总结生成


