clean-wikipedia
收藏Hugging Face2025-03-20 更新2025-03-21 收录
下载链接:
https://huggingface.co/datasets/HuggingFaceFW/clean-wikipedia
下载链接
链接失效反馈官方服务:
资源简介:
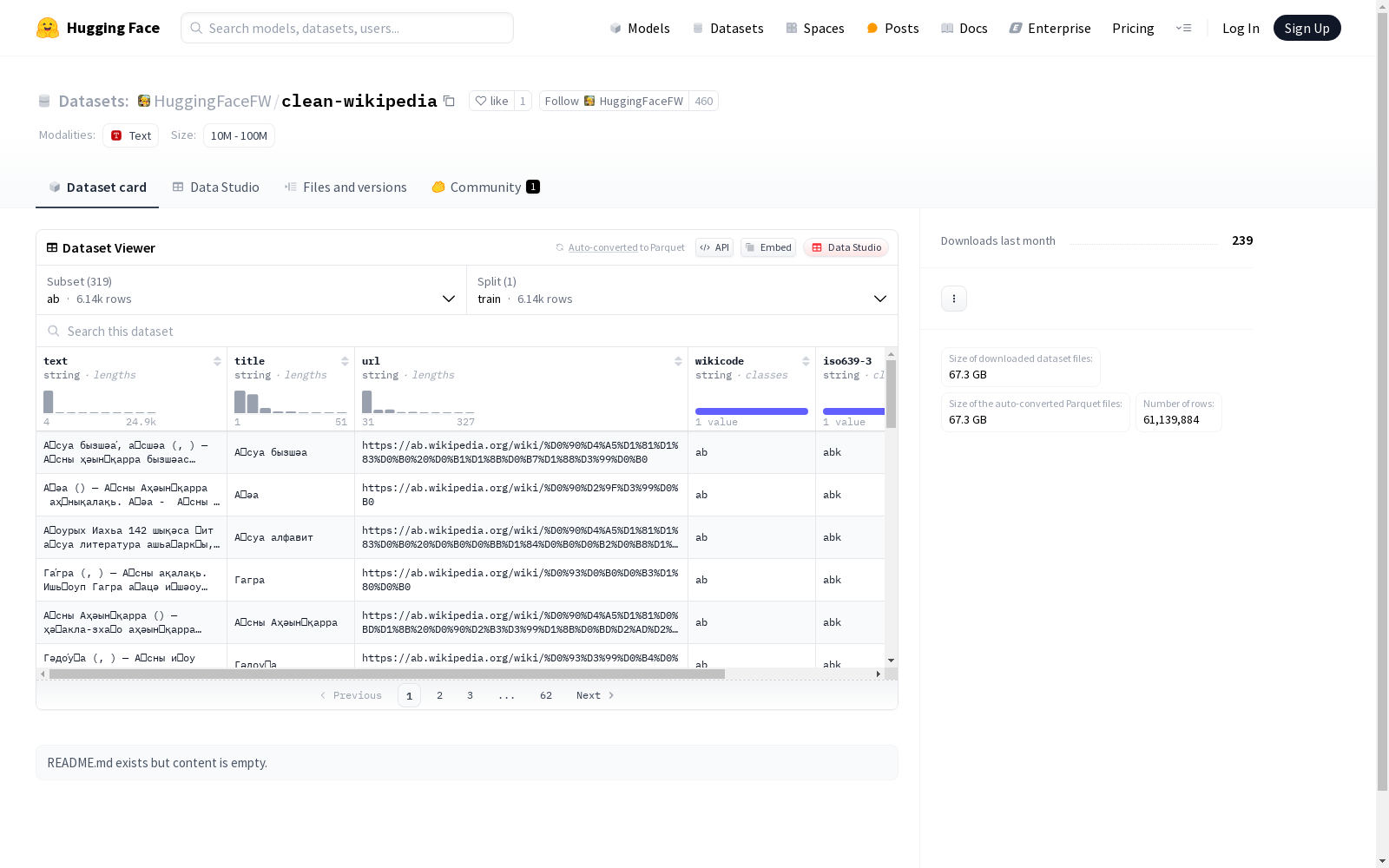
该数据集包含了不同语言配置的文本数据,每个配置包含文本、标题、URL、维基代码、ISO 639-3代码和脚本等特征。数据集还提供了训练分割中的示例数量和整个数据集的大小(以字节为单位)。数据集支持多种语言,如config_name字段所示。
This dataset contains text data with various language configurations. Each configuration includes features such as text, title, URL, Wikipedia code, ISO 639-3 code, and script. The dataset also provides the number of examples in the training split and the total size of the dataset in bytes. The dataset supports multiple languages, as indicated by the config_name field.
提供机构:
HuggingFaceFW创建时间:
2025-03-19
搜集汇总
数据集介绍
构建方式
clean-wikipedia数据集是通过从维基百科中提取多语言文本内容构建而成。该数据集涵盖了多种语言,每种语言的数据均包含文本、标题、URL、维基代码、ISO 639-3语言代码以及脚本信息。数据集的构建过程涉及对维基百科页面的结构化解析,确保每条记录包含完整的元数据信息,以便于后续的多语言文本处理和分析。
特点
clean-wikipedia数据集的一个显著特点是其多语言覆盖范围广泛,涵盖了从常见语言到少数语言的多样化文本内容。每条记录不仅包含文本内容,还提供了丰富的元数据,如标题、URL、维基代码等,便于用户进行多维度的分析和处理。此外,数据集的规模较大,部分语言的文本量达到了数百万条记录,适合用于大规模自然语言处理任务。
使用方法
clean-wikipedia数据集适用于多种自然语言处理任务,如机器翻译、文本分类、语言模型训练等。用户可以通过HuggingFace平台直接下载数据集,并根据需要选择特定语言或全部数据进行处理。数据集的结构化格式使得用户可以轻松提取所需字段,并结合其他工具进行进一步的分析或模型训练。
背景与挑战
背景概述
clean-wikipedia数据集是一个多语言维基百科文本数据集,涵盖了多种语言的维基百科条目。该数据集的创建旨在为自然语言处理(NLP)领域的研究人员提供一个干净、结构化的多语言文本资源,以支持跨语言文本分析、机器翻译、文本生成等任务。数据集的核心研究问题在于如何从维基百科的原始数据中提取并清理出高质量的文本内容,同时保留其语言多样性和文化背景。该数据集对NLP领域的影响力显著,尤其是在低资源语言的处理和跨语言模型的研究中,提供了宝贵的资源。
当前挑战
clean-wikipedia数据集面临的挑战主要包括两个方面。首先,维基百科的原始数据包含大量非结构化信息,如模板、引用、表格等,如何有效地清理这些噪声并提取出纯净的文本内容是一个技术难题。其次,数据集中涵盖的语言种类繁多,不同语言的文本质量和结构差异较大,如何确保每种语言的文本质量一致且适用于NLP任务,是构建过程中的另一大挑战。此外,数据集的规模庞大,处理和管理这些数据需要高效的计算资源和存储方案。
常用场景
经典使用场景
clean-wikipedia数据集广泛应用于自然语言处理领域,特别是在多语言文本处理任务中。该数据集包含了多种语言的维基百科文章,涵盖了丰富的主题和领域,适用于文本分类、机器翻译、信息检索等任务。由于其多语言特性,研究者可以利用该数据集进行跨语言模型的训练和评估,探索不同语言之间的语义关联和知识迁移。
衍生相关工作
clean-wikipedia数据集催生了许多经典的多语言自然语言处理工作。例如,基于该数据集的多语言BERT模型(mBERT)在跨语言任务中表现出色,推动了多语言预训练模型的发展。此外,该数据集还被用于开发多语言知识图谱,帮助研究者构建跨语言的知识表示和推理系统,进一步推动了多语言人工智能的研究和应用。
数据集最近研究
最新研究方向
在自然语言处理领域,clean-wikipedia数据集因其多语言特性而备受关注。该数据集涵盖了从阿布哈兹语到克里米亚鞑靼语等多种语言,为跨语言模型的研究提供了丰富的语料资源。近年来,随着多语言预训练模型的兴起,clean-wikipedia数据集被广泛应用于跨语言文本生成、机器翻译以及低资源语言的模型训练。特别是在低资源语言的模型优化中,该数据集通过提供高质量的文本数据,显著提升了模型的泛化能力和翻译精度。此外,随着全球多语言互联网内容的快速增长,clean-wikipedia数据集在推动语言技术民主化方面也发挥了重要作用,为全球范围内的语言平等和技术普及提供了有力支持。
以上内容由遇见数据集搜集并总结生成


