Mille-Pensees-Dataset
收藏Hugging Face2025-12-08 更新2025-12-09 收录
下载链接:
https://huggingface.co/datasets/GLauzza/Mille-Pensees-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
Mille-Pensées-Dataset是一个数学推理数据集,由50%法语和50%英语组成,用于训练法语推理模型Mille-Pensées。数据来源于多个英语数学推理数据集,法语数据是通过使用Qwen3-32B-FP8-dynamic模型翻译英语数据得到的(包括思维链)。数据集包含77k样本,总计约0.5B tokens。数据集结构包括answer(问题的真实答案)、model(生成思维链的模型)、question(问题)、solution(包括思维链的生成解决方案)和source(来源数据集和子集)。每个样本可能有不同的许可证,需根据source字段对应数据集的许可证进行遵守。
The Mille-Pensées-Dataset is a mathematical reasoning dataset composed of 50% French and 50% English, designed for training the French-language reasoning model Mille-Pensées. It is derived from multiple English mathematical reasoning datasets, with the French portion translated from the English data using the Qwen3-32B-FP8-dynamic model, including chain-of-thought content. The dataset contains 77k samples, totaling approximately 0.5B tokens. Its structure includes the following fields: answer (the ground-truth answer to the question), model (the model that generated the chain-of-thought), question (the problem question), solution (the generated solution including the chain-of-thought), and source (the source dataset and its subset). Each sample may have a different license, which must be complied with according to the license of the dataset corresponding to the source field.
创建时间:
2025-12-05
原始信息汇总
Mille-Pensées-Dataset 数据集概述
数据集基本信息
- 数据集名称:Mille-Pensées-Dataset
- 任务类别:文本生成
- 支持语言:法语、英语
- 数据规模:10K<n<100K(具体包含约77,000个样本,总计约0.5B个词元)
- 主要标签:数学、推理
- 数据格式:包含5个字段的结构化数据
数据集简介
Mille-Pensées-Dataset是一个数学推理数据集,其构成比例为50%法语和50%英语。该数据集用于训练法语推理模型Mille-Pensées。
数据来源与构建
- 英语数据来源:数据集整合了来自8个公开英语数学推理数据集的内容,具体包括:
- s1K-1.1
- OpenThoughts3-1.2M
- OpenR1-Math-220k
- OpenMathReasoning
- Nemotron-Post-Training-Dataset-v1
- LIMO-v2
- DeepMath-103K
- AM-DeepSeek-R1-0528-Distilled
- 法语数据生成:通过使用Qwen3-32B-FP8-dynamic模型(包含思维链)对英语推理数据进行翻译获得。
数据集结构
数据集包含以下字段:
answer:问题的标准答案model:用于生成思维链的模型名称question:问题描述solution:包含思维链的生成解决方案source:源数据集及子集信息
使用方式
可通过以下代码加载数据集: python from datasets import load_dataset ds = load_dataset("GLauzza/Mille-Pensees-Dataset")
许可证信息
数据集样本来自不同的源数据集,因此必须遵守相应source字段所指数据的许可证:
- s1K-1.1:MIT许可证
- OpenThoughts3-1.2M:Apache 2.0许可证
- OpenR1-Math-220k:Apache 2.0许可证
- OpenMathReasoning:CC-BY-4.0许可证
- Nemotron-Post-Training-Dataset-v1:CC-BY-4.0许可证
- LIMO-v2:Apache 2.0许可证
- DeepMath-103K:MIT许可证
- AM-DeepSeek-R1-0528-Distilled:严格限于研究用途,禁止商业使用和任何可能造成危害的应用
引用信息
- 计算资源支持:由GENCI在IDRIS提供,基于超级计算机Jean Zay的A100和H100分区(授权号2025-AD011011668R5)
- 作者机构:法国洛林大学研究实验室(LORIA, CNRS, Nancy, France)
- 引用格式: bibtex @misc{Mille-Pensees-Dataset, title={Mille-Pensees-Dataset}, url={https://huggingface.co/datasets/GLauzza/Mille-Pensees-Dataset}, author={Gabriel Lauzzana, Imane Ouada, Christophe Cerisara}, month={December}, year={2025} }
搜集汇总
数据集介绍
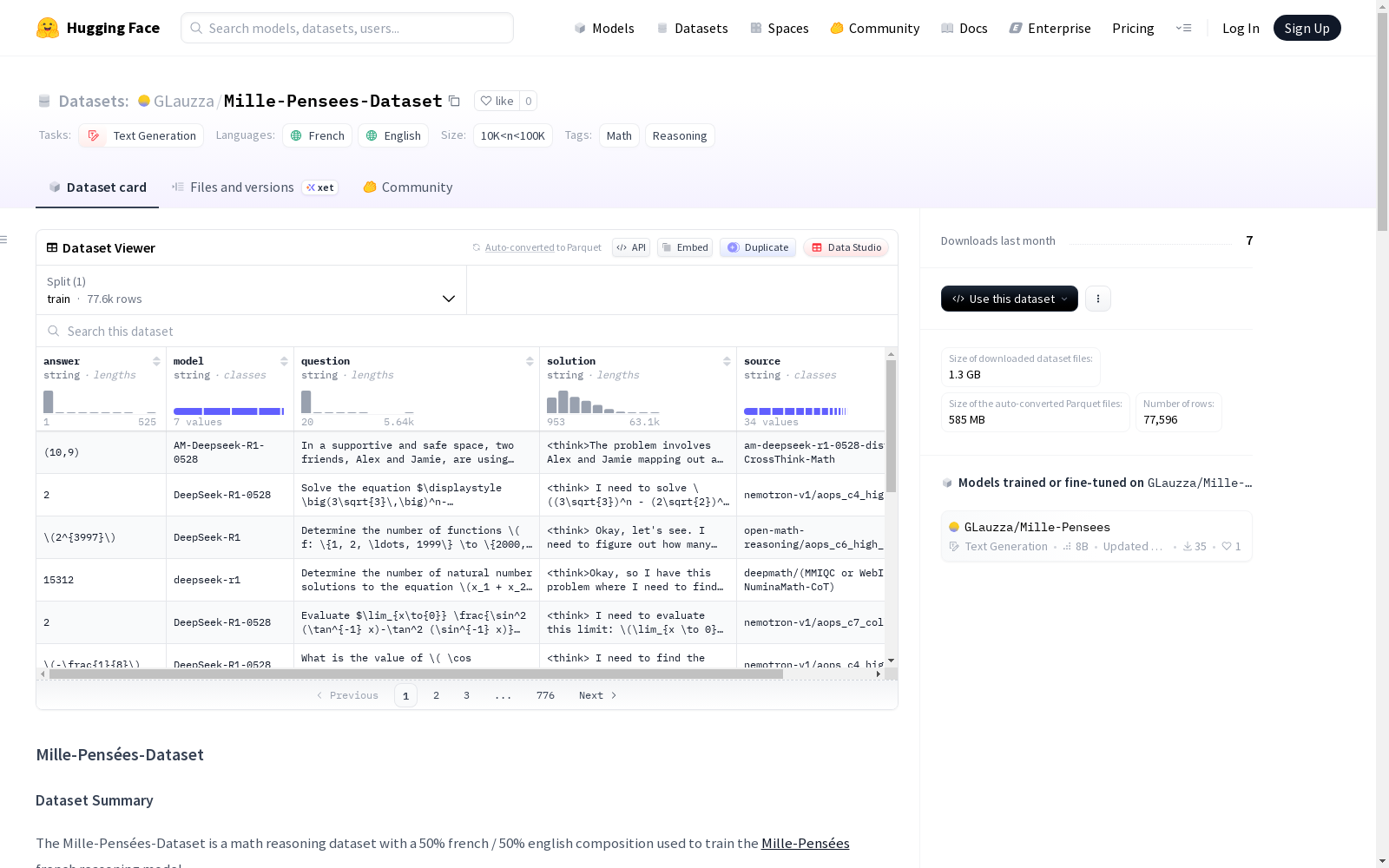
构建方式
在数学推理领域,构建高质量双语数据集对提升模型跨语言能力至关重要。Mille-Pensées-Dataset的构建采用集成与翻译相结合的策略,从八个权威英文数学推理数据源中精选内容,涵盖OpenMathReasoning、DeepMath-103K等多样化资源。通过Qwen3-32B-FP8-dynamic模型对原始英文数据进行法文翻译,完整保留了思维链推理过程,最终形成包含七万七千个样本、约五亿词汇规模的双语数据集,实现了英法语言内容的均衡分布。
使用方法
研究人员可通过Hugging Face标准接口便捷加载该数据集,利用其双语特性开展多语言数学推理模型的训练与评估。使用时应特别注意样本的许可证差异,严格遵循各源数据集对应的使用条款,尤其关注商业用途限制。数据集的结构化设计支持直接应用于思维链生成、答案验证、跨语言迁移学习等研究场景,其丰富的元数据信息为数据溯源和实验分析提供了坚实基础。
背景与挑战
背景概述
在数学推理领域,高质量的多语言数据集对于推动语言模型在复杂问题解决能力上的发展至关重要。Mille-Pensées-Dataset由法国洛林大学计算机科学及其应用实验室的研究团队于2025年创建,旨在为法语数学推理模型Mille-Pensées提供训练基础。该数据集精心整合了八个知名的英文数学推理开源数据集,并通过先进的Qwen3-32B模型进行翻译与思维链生成,最终构建了一个包含约7.7万样本、总计约5亿标记的英法双语资源。其核心研究问题聚焦于弥补法语数学推理数据的稀缺性,通过跨语言知识迁移,提升模型在法语语境下的逻辑推理与分步解题性能,对促进非英语自然语言处理研究具有显著的学术价值。
当前挑战
该数据集致力于解决数学推理这一核心领域问题,其挑战在于模型需准确理解复杂的数学表述,并生成连贯、正确的推理步骤与最终答案,这对模型的逻辑严谨性与语言理解深度提出了极高要求。在构建过程中,团队面临多重挑战:首要挑战在于确保从多样化的英文源数据到法语的翻译准确性,尤其是在保留数学符号、专业术语及思维链的逻辑完整性方面;其次,整合多个来源不同、许可协议各异的数据集,需严格遵守各自的版权规定,并在数据清洗、格式统一与质量验证上投入大量精力,以保障最终数据集的可靠性与合规性。
常用场景
经典使用场景
在数学推理与自然语言处理交叉领域,Mille-Pensées-Dataset 作为双语数学推理数据集,其经典使用场景集中于训练和评估法语数学推理模型。该数据集通过整合多个高质量英文数学推理源数据,并借助先进的大语言模型进行法语翻译与思维链生成,为研究者提供了丰富的双语数学问题及其逐步推理过程。这一设计使得数据集能够有效支撑模型在跨语言数学问题求解、逻辑推理能力提升以及思维链生成质量优化等方面的实验与验证,成为推动法语数学推理模型发展的重要资源。
解决学术问题
该数据集主要解决了数学推理领域内跨语言数据稀缺、高质量思维链标注不足以及模型泛化能力评估困难等学术研究问题。通过构建均衡的法语与英语数学问题对,并附带详细的推理步骤,它为研究跨语言知识迁移、思维链对模型推理能力的促进作用以及多语言数学问题求解的统一框架提供了实证基础。其意义在于弥合法语数学推理数据与前沿英文资源之间的差距,促进了语言无关的数学推理能力研究,并为评估模型在多样化语言和文化背景下的稳健性设立了新的基准。
实际应用
在实际应用层面,Mille-Pensées-Dataset 为开发面向法语用户的教育技术工具、智能辅导系统以及多语言数学问题解答引擎提供了关键数据支持。基于该数据集训练的模型能够理解并解答复杂的法语数学问题,展示出清晰的推理路径,从而辅助学生自主学习、帮助教师设计个性化练习,甚至为科研人员提供跨语言数学内容分析与生成的工具。其应用潜力延伸至在线教育平台、学术研究辅助以及多语言信息处理系统,推动了人工智能在 STEM 教育领域的实用化与普及。
数据集最近研究
最新研究方向
在数学推理领域,多语言模型的性能提升已成为前沿探索的核心议题。Mille-Pensées-Dataset作为法语与英语各占半数的数学推理数据集,其构建策略体现了跨语言知识迁移的最新趋势。该数据集通过先进的大语言模型对英文数学推理数据进行高质量翻译,并保留思维链细节,为法语推理模型的训练提供了关键资源。当前研究热点聚焦于如何利用此类双语数据集增强模型在低资源语言上的推理能力,以及探索思维链数据在多语言环境下的泛化效果。这一工作不仅推动了法语自然语言处理技术的发展,也为其他非英语语种的数学教育智能化应用奠定了数据基础,具有显著的学术与实践价值。
以上内容由遇见数据集搜集并总结生成


