gutenberg2-dpo
收藏Hugging Face2024-09-21 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/nbeerbower/gutenberg2-dpo
下载链接
链接失效反馈官方服务:
资源简介:
Gutenberg2 DPO数据集是一个用于增强LLMs写作能力的DPO数据集,基于Project Gutenberg的公共领域书籍构建。数据集包括经典文学作品的章节和相应的提示,旨在通过对比'chosen'和'rejected'值来优化LLMs的写作表现。
The Gutenberg2 DPO Dataset is a DPO dataset tailored to enhance the writing capabilities of Large Language Models (LLMs). It is constructed using public-domain books sourced from Project Gutenberg, and comprises chapters of classic literary works along with their corresponding prompts. The core objective of this dataset is to optimize the writing performance of LLMs by comparing the "chosen" and "rejected" values.
创建时间:
2024-09-21
原始信息汇总
Gutenberg2 DPO
概述
Gutenberg2 DPO 数据集旨在通过使用来自 Project Gutenberg 的公共领域书籍来增强大型语言模型(LLMs)的写作能力。
数据处理
- 从 Project Gutenberg 中选择多本书籍,根据个人偏好和 Claude 3.5 Sonnet 的推荐。
- 使用 chapterize 工具按章节解析书籍。未能成功解析或结果混乱的书籍被排除。
- 手动编辑章节,删除插图标签、注释等,并使用正则表达式去除多余的换行符。
- 使用 LLM 生成每个章节的摘要,结合前一章节的摘要和当前章节的文本生成提示,用于 LLM 生成该章节的文本。
- 使用生成的提示生成“拒绝”值,原始章节文本作为“选择”值。
模型使用
- 使用 nbeerbower/mistral-nemo-bophades-12B 生成摘要、提示和拒绝值。
代码
- 所有使用的代码将发布到 GitHub,并采用 MIT 许可证。
致谢
- Jon Durbin:原始想法和流程的贡献者。
- Jonathan Reeve:chapterize 库的开发者。
- Mistral AI:提供先进的、开源许可的 LLMs。
- Project Gutenberg 及其志愿者:保存文学历史并使其对所有人开放。
- koboldcpp:提供快速且易于使用的 LLM 推理工具。
- llama.cpp 和 Georgi Gerganov:GGUF 的开发者。
- Michael Radermacher:量化模型,特别是用于生成此数据集的模型。
选定作品
- Alices Adventures in Wonderland - Lewis Carroll
- Around the World in Eighty Days - Jules Verne
- The Awakening - Kate Chopin
- The Canterville Ghost - Oscar Wilde
- The Invisible Man - H.G. Wells
- The Island of Dr. Moreau - H.G. Wells
- The Metamorphosis - Franz Kafka
- Peter Pan - J.M. Barrie
- The Picture of Dorian Gray - Oscar Wilde
- The Red Badge of Courage - Stephen Crane
- The Secret Agent - Joseph Conrad
- The Adventures of Tom Sawyer - Mark Twain
- The Wonderful Wizard of Oz - L. Frank Baum
免责声明
- 该数据集免费提供,无任何保证。数据可能包含错误,并可能定期修改。
- 用户可以自由修改和重新分发数据集。
搜集汇总
数据集介绍
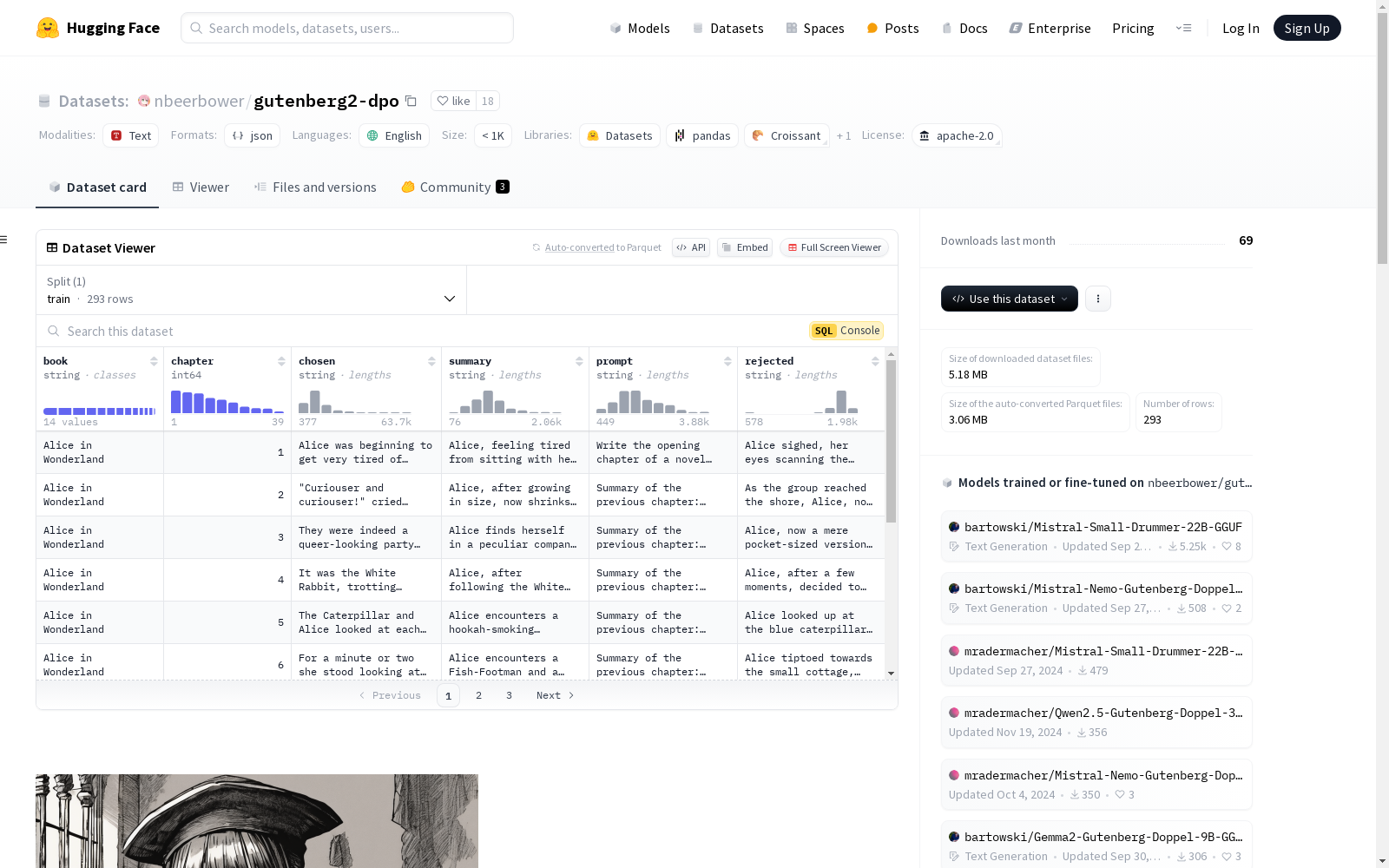
构建方式
Gutenberg2 DPO数据集的构建过程始于从Project Gutenberg中精选多部经典文学作品,这些作品的选择基于个人偏好及Claude 3.5 Sonnet的推荐。随后,使用chapterize工具对书籍进行章节划分,剔除解析失败或结果混乱的书籍。每章节经过手动编辑,去除插图标签、注释等无关内容,并通过正则表达式清理多余换行符。接着,利用大型语言模型生成章节摘要,结合前一章节的摘要和当前章节的文本生成提示,进而生成被拒绝的文本值,而原始章节文本则作为优选文本。
特点
Gutenberg2 DPO数据集的特点在于其专注于提升大型语言模型的写作能力,通过精选的公共领域文学作品进行训练。数据集中的每一章节都经过精心处理,确保文本的纯净性和连贯性。此外,数据集还包含了由大型语言模型生成的章节摘要和提示,这些内容不仅丰富了数据集的信息量,也为模型的训练提供了多样化的输入。
使用方法
Gutenberg2 DPO数据集的使用方法主要包括将其用于训练和评估大型语言模型的写作能力。用户可以通过加载数据集,利用其中的优选文本和被拒绝文本进行对比学习,从而提升模型在生成文本时的准确性和流畅性。此外,数据集中的章节摘要和提示也可用于生成新的文本内容,进一步扩展模型的应用场景。
背景与挑战
背景概述
Gutenberg2 DPO数据集旨在通过利用来自Project Gutenberg的公共领域书籍,提升大型语言模型(LLMs)的写作能力。该数据集由nbeerbower等人于近期创建,灵感来源于Jon Durbin的Gutenberg DPO数据集。通过从Project Gutenberg中精选书籍,并借助Claude 3.5 Sonnet的推荐,研究人员对这些书籍进行了章节化处理,并生成了章节摘要与提示词。该数据集的核心研究问题在于如何通过对比原始文本与模型生成的文本,优化LLMs的写作表现。Gutenberg2 DPO的发布为自然语言生成领域提供了新的研究资源,推动了基于经典文学作品的模型训练与评估。
当前挑战
Gutenberg2 DPO数据集在构建过程中面临多重挑战。首先,书籍的章节化处理依赖于自动化工具,部分书籍因格式问题无法正确解析,导致数据丢失。其次,手动编辑章节内容以去除插图标签、注释等冗余信息,增加了数据清洗的复杂性。此外,生成章节摘要和提示词的过程依赖于LLMs,模型输出的质量直接影响数据集的最终效果。在解决领域问题上,该数据集旨在提升LLMs的写作能力,但如何确保生成的文本在风格、逻辑和内容上与原始文本保持一致,仍是一个亟待解决的难题。这些挑战不仅影响了数据集的构建效率,也对后续模型训练的效果提出了更高的要求。
常用场景
经典使用场景
Gutenberg2 DPO数据集主要用于增强大型语言模型(LLMs)的写作能力,特别是在生成连贯且富有文学性的文本方面。通过使用来自Project Gutenberg的公共领域书籍,该数据集为模型提供了丰富的文学素材,使其能够更好地理解和模仿经典文学作品的风格和结构。
衍生相关工作
Gutenberg2 DPO数据集的发布激发了大量相关研究,特别是在基于文学数据的文本生成和风格迁移领域。许多研究团队基于该数据集开发了新的模型和算法,进一步提升了语言模型在文学创作中的应用效果。此外,该数据集还为开源社区提供了宝贵的资源,推动了自然语言处理技术的普及和发展。
数据集最近研究
最新研究方向
近年来,随着大语言模型(LLMs)在自然语言处理领域的广泛应用,如何提升其生成文本的质量和多样性成为研究热点。Gutenberg2 DPO数据集通过利用公共领域的经典文学作品,如《爱丽丝梦游仙境》和《八十天环游地球》,为大语言模型的写作能力提供了丰富的训练素材。该数据集通过章节化的处理方式,结合LLM生成的摘要和提示,生成了“选择”和“拒绝”文本对,进一步优化了模型的生成效果。这一方法不仅为大语言模型的写作能力提供了新的训练范式,也为文学作品的数字化处理与再利用开辟了新的研究方向。Gutenberg2 DPO数据集的发布,标志着文学资源与人工智能技术的深度融合,为未来的文本生成研究提供了重要的数据支持。
以上内容由遇见数据集搜集并总结生成


