assignment3-self-align-curated-lima150
收藏Hugging Face2026-04-14 更新2026-04-15 收录
下载链接:
https://huggingface.co/datasets/kkkyle/assignment3-self-align-curated-lima150
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含26个训练样本,主要用于指令跟随任务评估。数据特征包含生成指令(generated_instruction)、LIMA模型响应(lima_response)、原始指令(lima_instruction)、数据来源(source)、评分(score)、评分文本(rating_text)和选择规则(selection_rule)共7个字段。其中评分字段为整型,其余均为字符串类型。数据集总大小约95.8KB,下载大小58.3KB。数据组织形式为单一训练集,存储路径为data/train-*。字段命名表明该数据集可能用于评估AI模型对指令的理解和执行能力,并包含人工质量评分信息。
This dataset contains 26 training samples, primarily intended for instruction-following task evaluation. It includes seven data fields: generated_instruction, lima_response, original instruction (lima_instruction), data source (source), score, rating_text, and selection_rule. The score field is of integer type, while all other fields are string types. The total size of the dataset is approximately 95.8 KB, with a download size of 58.3 KB. The data is organized as a single training set and stored at the path data/train-*. The field naming suggests that this dataset can be used to evaluate AI models' capabilities in understanding and executing instructions, and it contains manual quality rating information.
创建时间:
2026-04-13
原始信息汇总
数据集概述
数据集基本信息
- 数据集名称: assignment3-self-align-curated-lima150
- 托管平台: Hugging Face Datasets
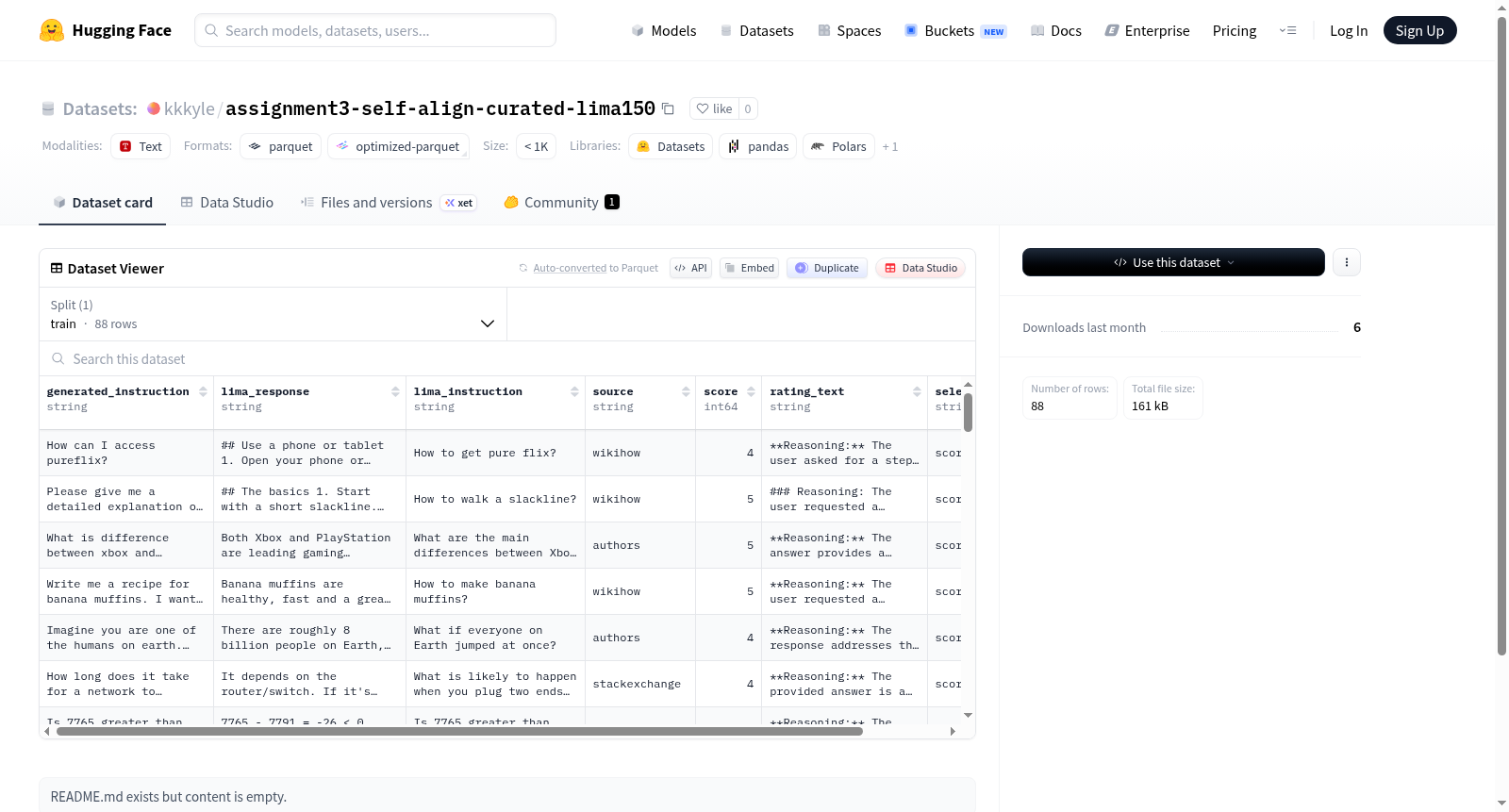
- 数据量: 88 个示例
- 数据集大小: 258,094 字节
- 下载大小: 158,404 字节
- 默认配置名称: default
数据结构与特征
数据集包含一个训练集(train),包含以下字段:
- generated_instruction (string): 生成的指令。
- lima_response (string): LIMA 响应。
- lima_instruction (string): LIMA 指令。
- source (string): 数据来源。
- score (int64): 评分。
- rating_text (string): 评分文本。
- selection_rule (string): 选择规则。
数据文件
- 训练集路径:
data/train-*
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量指令遵循数据的稀缺性促使研究者探索创新的数据构建途径。assignment3-self-align-curated-lima150数据集通过精心设计的自我对齐流程构建而成,其核心方法是从LIMA数据集中筛选出150个高质量的指令-响应对作为种子。在此基础上,利用先进的生成模型自动产生多样化的新指令,并通过多轮人工或自动化评估,依据明确的评分规则对生成内容进行严格筛选与排序,最终形成包含88个样本的精选集合。这一构建过程融合了种子数据的高质量特性与模型生成的可扩展性,旨在提升指令数据的多样性与实用性。
特点
该数据集在指令微调与对齐研究领域展现出鲜明的特征。其结构设计精细,每条数据不仅包含原始LIMA指令与响应,还提供了模型生成的指令、来源标识、人工评分及选择规则等丰富元数据,为深入分析模型行为提供了多维视角。数据规模虽小,但经过严格筛选,确保了每个样本在指令清晰度、响应质量及任务多样性上的高标准。这种高密度、高信息量的特点使其特别适合于探究指令遵循模型的泛化能力、评估不同对齐策略的效果,或作为高质量数据增强的参考基准。
使用方法
对于致力于语言模型对齐与微调的研究者而言,该数据集可直接应用于模型训练或评估环节。用户可通过HuggingFace数据集库加载‘train’分割,获取包含‘generated_instruction’、‘lima_response’等关键字段的数据。在实际应用中,可将生成指令与对应响应作为训练对,用于监督式微调,以提升模型遵循复杂指令的能力。同时,丰富的元数据如‘score’和‘selection_rule’可用于构建评估指标,分析模型输出与人工偏好的一致性。数据集的小规模与高质量特性也使其适合作为验证集或测试集,用于快速原型开发和算法对比。
背景与挑战
背景概述
随着大型语言模型在自然语言处理领域的广泛应用,如何提升其指令遵循与对齐能力成为研究焦点。assignment3-self-align-curiced-lima150数据集应运而生,它基于LIMA(Less Is More for Alignment)框架构建,旨在通过精选的高质量示例优化模型输出。该数据集由研究团队在2023年左右创建,核心目标在于探索如何以有限但精良的数据实现模型行为的有效对齐,从而减少对大规模标注数据的依赖,推动高效对齐方法的发展。
当前挑战
该数据集致力于解决指令对齐中数据质量与泛化性之间的平衡难题,挑战在于如何从海量候选响应中筛选出既符合人类偏好又具备多样性的示例,以避免模型过拟合或产生偏差。在构建过程中,研究人员面临标注一致性与评分标准化的困难,需设计严谨的选择规则来确保示例的可靠性与代表性,同时应对数据来源异构性带来的整合挑战。
常用场景
经典使用场景
在自然语言处理领域,特别是大语言模型对齐研究中,assignment3-self-align-curated-lima150数据集被广泛用于指令微调和响应质量评估。该数据集通过精心筛选的指令-响应对,为模型提供了高质量的人类偏好对齐样本,常用于训练模型生成更符合人类价值观和意图的文本。研究人员利用其结构化的生成指令与评分机制,系统性地优化模型在开放域对话中的表现,提升其安全性和有用性。
解决学术问题
该数据集有效解决了大语言模型对齐中的核心学术问题,即如何减少模型生成有害、偏见或不相关的内容。通过提供经过人工评分的指令-响应对,它帮助研究者量化模型输出与人类偏好的一致性,为对齐算法如强化学习从人类反馈中学习提供了关键数据支撑。其意义在于推动了可解释对齐方法的发展,降低了模型部署中的伦理风险,对构建可信赖的人工智能系统具有深远影响。
衍生相关工作
基于该数据集,衍生了一系列经典研究工作,包括对齐算法的优化如基于人类反馈的强化学习变体,以及指令微调技术的改进。这些工作扩展了数据集在少样本学习、多任务泛化中的应用,推动了开源社区中安全对齐模型的开发。相关成果进一步丰富了对齐理论,为后续数据集如LIMA和Anthropic的HHH提供了方法论借鉴,加速了AI伦理与对齐研究领域的进展。
以上内容由遇见数据集搜集并总结生成


