Eastern Min corpus / 閩東語語料庫
收藏github2023-12-04 更新2024-05-31 收录
下载链接:
https://github.com/Guanchishan/cdo-corpus
下载链接
链接失效反馈官方服务:
资源简介:
閩東語語料庫包含多种类型的语料,如纯文本、有声语料等,涵盖了语句、诗歌、文章、书籍等内容,用于研究和分析閩東語。
The Min Dong language corpus encompasses a variety of corpus types, including plain text and audio materials, covering sentences, poetry, articles, books, and more, utilized for the research and analysis of the Min Dong language.
创建时间:
2023-12-04
原始信息汇总
数据集概述
数据集名称
Eastern Min corpus / 閩東語語料庫
数据集内容
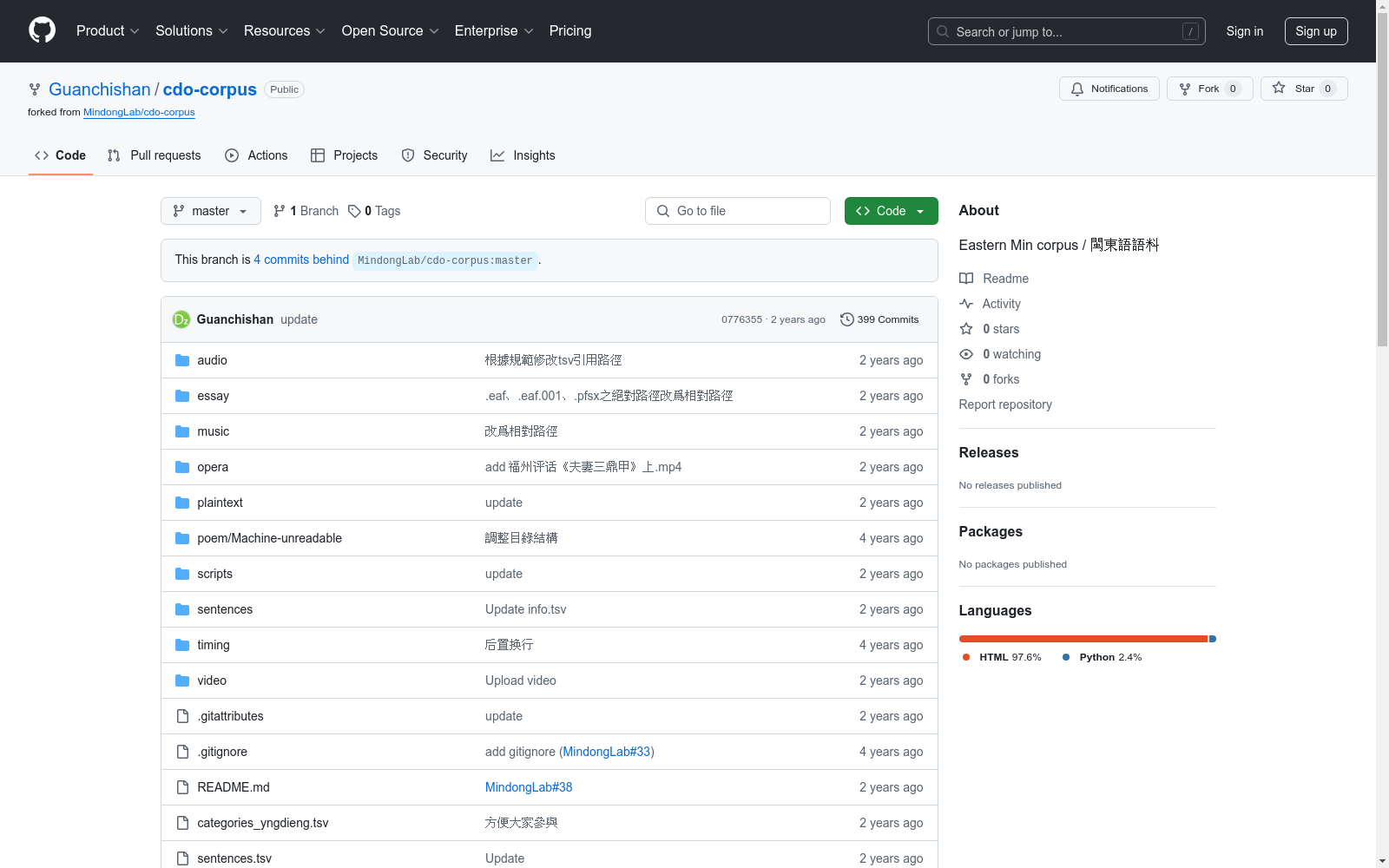
1. 纯文本语料
- 目录:
/plaintext- 包含语句、诗歌、文章、书籍等类。
- 子目录:
/.../word-alignment,包含以XML格式标注、精度为词的纯文本语料。
2. 有声语料
- 目录:
/essay:朗读文章。/music:歌曲。/opera:戏曲,包括闽剧选段。/poem:诗歌、谣谶。/video:影片。/sentences:语句。info.tsv:语料信息表。template.etf:ELAN模板。
3. 其他材料
- 目录:
/audio- 包含用于榕典的音频文件。
audio contrib:用户贡献词汇的音频文件。audio contrib sentences:用户贡献词汇的例句音频文件。audio feng:冯爱珍版《福州方言词典》词汇音频。audio li:李如龙版《福州方言词典》词汇音频。
- 包含用于榕典的音频文件。
- 目录:
/timing- 记录志愿者的标记工作时长。
语料状态分类
- Machine-unreadable
- Working on sentence alignment (cdo)
- Sentence-aligned (cdo)
- Sentence-aligned (cdo, cmn)
- Sentence-aligned (cmn, cdo)
搜集汇总
数据集介绍
构建方式
閩東語語料庫的构建采用了多源数据整合的方式,涵盖了纯文本和有声语料两大类。纯文本语料包括语句、诗歌、文章和书籍等,以XML格式进行词对齐标注。有声语料则包括朗读文章、歌曲、戏曲、诗歌、影片等多种形式,部分语料还进行了句对齐处理,涵盖了闽东语与官话之间的互译。此外,语料库还包含了用户贡献的音频文件及相关的音频信息表,确保了数据的多样性和完整性。
特点
该数据集的特点在于其丰富的语料类型和精细的标注体系。纯文本语料通过XML格式实现了词级别的对齐,而有声语料则涵盖了多种语言表现形式,如歌曲、戏曲等,部分语料还进行了句对齐处理,支持闽东语与官话之间的互译。数据集还提供了详细的语料信息表和音频文件,便于用户进行深入分析和研究。此外,语料库的目录结构清晰,语料状态明确,便于用户快速定位所需资源。
使用方法
用户可以通过访问GitHub上的Wiki页面获取详细的使用指南。纯文本语料可直接从`/plaintext`目录中获取,而有声语料则分布在`/essay`、`/music`、`/opera`等子目录中。用户可根据语料状态文件夹(如`Machine-unreadable`、`Sentence-aligned`等)选择适合的语料进行下载和使用。此外,数据集还提供了音频文件和相关的信息表,用户可通过`/audio`目录获取音频资源,并通过`/timing`目录了解志愿者的标记工作时长,以便更好地安排任务。
背景与挑战
背景概述
閩東語語料庫(Eastern Min corpus)是一個專注於閩東語(福州話)的語言資源,旨在為語言學研究、自然語言處理及文化保存提供豐富的語料支持。該語料庫由MindongLab團隊創建,涵蓋了純文本、有聲語料等多種形式的數據,包括詩歌、文章、戲曲、歌曲等。閩東語作為漢語方言的一支,具有獨特的語音、詞彙和語法特徵,其研究對於理解漢語方言的多樣性及語言演變具有重要意義。該語料庫的建立不僅填補了閩東語數字化資源的空白,也為方言保護和語言技術開發提供了重要基礎。
当前挑战
閩東語語料庫的構建面臨多重挑戰。首先,閩東語作為一種方言,其語音和詞彙的標準化程度較低,語料的收集和標註需要依賴專業語言學知識,這增加了數據整理的複雜性。其次,有聲語料的處理涉及音頻的質量控制、語音轉文本的準確性以及多模態數據的對齊問題,這些技術難點對語料庫的構建提出了較高要求。此外,閩東語的語言資源相對稀缺,語料的來源多樣且分散,如何高效整合和規範化這些資源也是一大挑戰。這些問題的解決需要跨學科合作和技術創新,以確保語料庫的質量和可用性。
常用场景
经典使用场景
閩東語語料庫廣泛應用於語言學研究,特別是在方言保護和語言變異分析領域。研究者利用該語料庫中的純文本和有聲語料,進行語音、語法和詞彙的深入分析,從而揭示閩東語的語言結構和演變規律。此外,該語料庫還支持跨語言對齊研究,為閩東語與官話之間的翻譯和對比提供了豐富的數據支持。
实际应用
在實際應用中,閩東語語料庫被廣泛用於方言教學、語言技術開發和文化遺產保護。教育機構可以利用該語料庫中的有聲語料進行方言教學,幫助學生更好地掌握閩東語的發音和語法。此外,語料庫中的數據還可用於開發語音識別、機器翻譯等語言技術,進一步推動閩東語在數字時代的應用和傳播。
衍生相关工作
閩東語語料庫的發布促進了多項相關研究的開展,特別是在方言語音識別和機器翻譯領域。基於該語料庫,研究者開發了多種方言語音識別模型,並探索了閩東語與官話之間的機器翻譯技術。此外,語料庫中的句對齊數據還被用於跨語言信息檢索和語料庫語言學研究,為方言保護和語言技術的發展提供了重要支持。
以上内容由遇见数据集搜集并总结生成


