EULAI
收藏Hugging Face2026-01-27 更新2026-01-28 收录
下载链接:
https://huggingface.co/datasets/AxelDlv00/EULAI
下载链接
链接失效反馈官方服务:
资源简介:
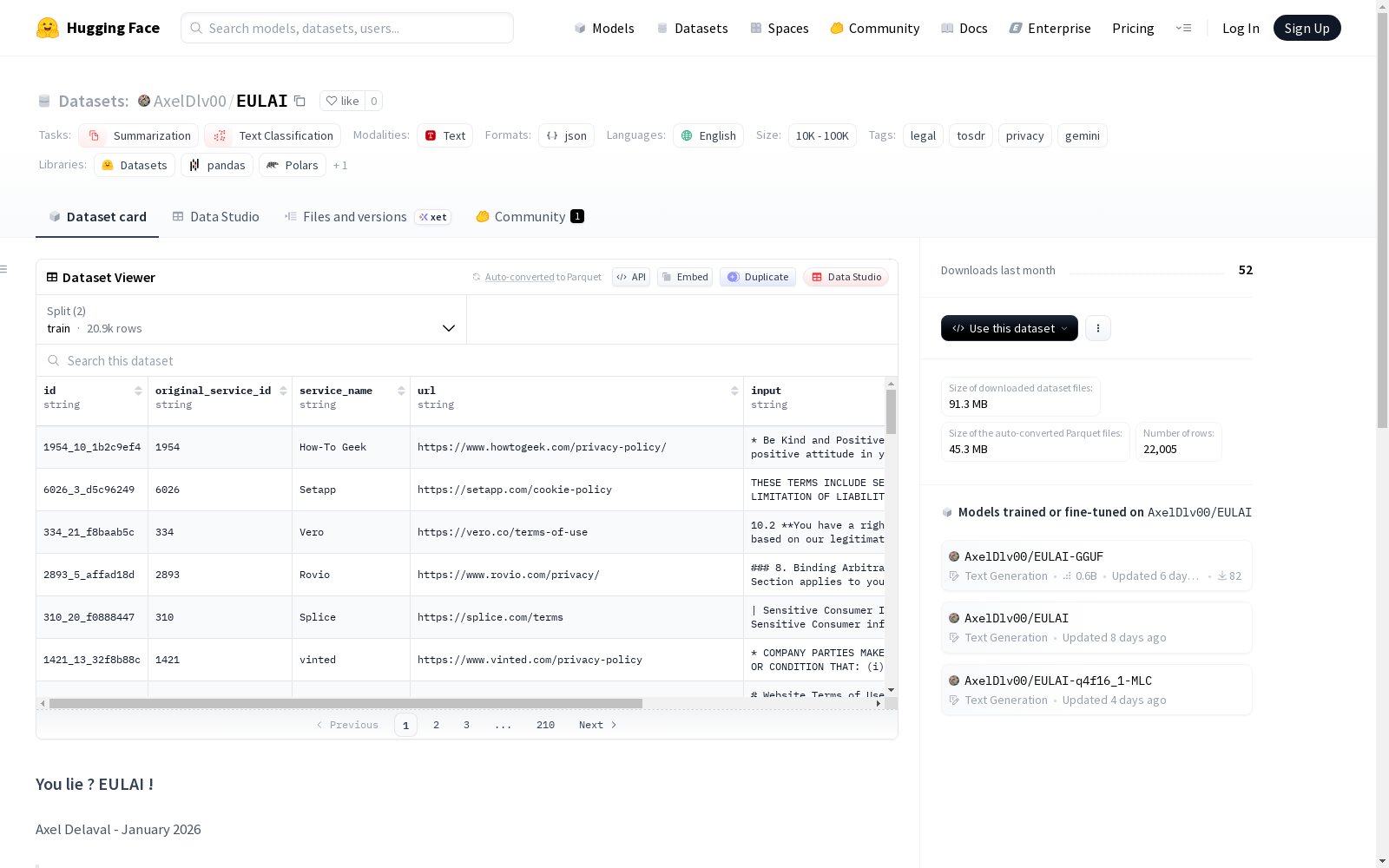
EULAI是一个专注于法律文本摘要和分类的数据集,主要用于处理服务条款(ToS)和隐私政策文档。该数据集旨在帮助用户快速理解复杂的法律协议内容。数据集包含以下字段:'id'(原始内容的MD5哈希值,确保唯一性)、'service_name'(服务提供商名称,如Google、TikTok等)、'url'(原始文档链接)、'policy'(从ToS/隐私页面提取的原始法律文本,作为输入)和'summary'(按照ToS;dr标准分类的要点摘要,作为目标输出)。数据集采用英文法律文本,适用于法律领域、隐私研究和ToSDR相关应用。数据已分为训练集(qwen_train.jsonl)和测试集(qwen_test.jsonl)两部分,以JSONL格式存储。该数据集最初是为EULAI浏览器扩展项目开发的,该扩展旨在通过自动摘要打破数字合同的不透明性,帮助用户在同意服务条款前快速了解关键内容。
EULAI is a dataset focused on legal text summarization and classification, primarily designed for processing Terms of Service (ToS) and privacy policy documents. This dataset aims to help users rapidly grasp the content of complex legal agreements. The dataset includes the following fields: 'id' (MD5 hash of the original content to ensure uniqueness), 'service_name' (name of the service provider, such as Google, TikTok, etc.), 'url' (link to the original document), 'policy' (original legal text extracted from ToS/privacy pages, used as input), and 'summary' (bullet-point summary classified according to the ToS;dr standard, used as target output). The dataset consists of English legal texts, and is applicable to legal research, privacy studies, and ToSDR-related applications. The dataset is split into two subsets: the training set (qwen_train.jsonl) and the test set (qwen_test.jsonl), stored in JSONL format. This dataset was initially developed for the EULAI browser extension project, which aims to break the opacity of digital contracts via automatic summarization, helping users quickly understand key content before agreeing to Terms of Service.
创建时间:
2026-01-18
原始信息汇总
EULAI 数据集概述
数据集基本信息
- 数据集名称:EULAI
- 创建者:Axel Delaval
- 发布日期:2026年1月
- 任务类别:摘要生成、文本分类
- 语言:英语
- 标签:法律、tosdr、隐私、gemini
数据集描述
EULAI是一个旨在打破数字合同不透明性的智能浏览器扩展。该数据集用于支持从复杂的法律术语到简洁、可操作摘要的转换。
数据文件与配置
- 配置名称:default
- 训练集文件:qwen_train.jsonl
- 测试集文件:qwen_test.jsonl
数据模式
数据包含以下列:
- id:原始Markdown文本的MD5哈希值(确保内容唯一性)。
- service_name:公司或服务名称(例如:Google, TikTok)。
- url:原始服务条款/隐私政策文档的URL。
- policy:输入:从服务条款/隐私政策页面提取的原始法律文本。
- summary:目标:按照ToS;dr标准分类的要点摘要。
使用方法
python from datasets import load_dataset
ds_train = load_dataset("AxelDlv00/EULAI", split="train") ds_test = load_dataset("AxelDlv00/EULAI", split="test")
搜集汇总
数据集介绍
构建方式
在数字法律文本处理领域,EULAI数据集的构建体现了对用户协议透明化的追求。该数据集通过自动化爬虫技术,从知名互联网公司的服务条款与隐私政策页面中提取原始法律文本,并采用MD5哈希算法为每份文档生成唯一标识符以确保内容独特性。随后,依据ToS;dr分类标准,由专业标注人员将复杂的法律条文转化为结构化的要点摘要,形成政策文本与摘要之间的精准映射,从而构建出适用于文本摘要与分类任务的平行语料库。
特点
EULAI数据集的核心特征在于其专注于数字法律文本的简化与解析。数据集收录了来自多家主流互联网平台的服务协议,涵盖了丰富的法律术语与句式结构,为自然语言处理模型提供了高质量的训练素材。其摘要部分采用清晰的要点列表形式,按照法律条款的重要性与用户权益影响程度进行分类,不仅提升了文本的可读性,也为法律文本的自动化理解与风险评估奠定了结构化基础。这种设计使得数据集在保持法律文本严谨性的同时,兼具了实际应用的便捷性。
使用方法
针对法律文本的自动化处理需求,EULAI数据集为研究人员提供了便捷的使用途径。通过Hugging Face的datasets库,用户可直接加载训练集与测试集,快速接入现有的自然语言处理流程。该数据集适用于微调预训练模型以执行法律文本摘要生成或关键条款分类任务,例如,将原始政策文本输入模型,训练其输出结构化的要点摘要。在实际应用中,开发者可基于此数据集构建浏览器扩展或辅助工具,帮助用户即时解析数字服务协议中的核心内容,从而促进数字契约的透明化与用户知情权的保障。
背景与挑战
背景概述
在数字时代,用户与服务提供商之间的法律关系主要由服务条款和隐私政策等冗长复杂的法律文本所界定。这些文本通常充斥着专业术语,导致普通用户难以理解其内容与潜在风险,形成了显著的信息不对称。为应对这一挑战,EULAI数据集应运而生,由Axel Delaval等人于2026年创建,其核心研究问题聚焦于利用自然语言处理技术,将晦涩的法律协议自动转化为简洁明了的摘要,从而提升数字契约的透明度与用户知情权。该数据集整合了来自多家知名企业的服务条款与隐私政策,旨在推动法律文本摘要与分类领域的研究,对促进数字权利保护与人工智能在法律科技中的应用具有重要影响力。
当前挑战
EULAI数据集致力于解决法律文本自动摘要与分类领域的核心挑战,即如何从结构松散、语义复杂的服务条款与隐私政策中,准确提取关键信息并生成用户友好的摘要。这要求模型不仅需理解法律术语的特定含义,还需捕捉文本中的隐含义务与权利条款。在构建过程中,研究人员面临多重挑战:原始法律文本的获取与清洗涉及大量异构格式与动态网页内容,确保数据的一致性与完整性成为首要难题;同时,为生成高质量摘要,需要法律专家进行精细标注,以建立可靠的评估标准,这一过程成本高昂且耗时。此外,平衡摘要的简洁性与法律严谨性,避免信息失真或误导,亦是数据集构建中的关键考量。
常用场景
经典使用场景
在数字法律文本分析领域,EULAI数据集为自动摘要任务提供了关键资源。该数据集聚焦于服务条款和隐私政策等冗长复杂的法律文档,通过将原始政策文本映射至简洁的要点摘要,支持模型学习从专业法律术语中提取核心信息。这一过程典型应用于训练序列到序列模型或大型语言模型,以实现对用户协议的高效自动化解析,帮助用户快速把握合同要点。
实际应用
在实际应用中,EULAI数据集支撑了智能浏览器扩展和合同审查工具的开发。这些工具能够实时分析网站的服务条款,生成易于理解的摘要,帮助消费者在点击“同意”前了解关键条款,如数据收集、隐私权责等内容。此类应用显著提升了数字服务的透明度,赋能用户做出知情决策,并在消费者保护、合规科技等领域展现出广泛价值。
衍生相关工作
围绕EULAI数据集,衍生了一系列专注于法律文本处理的经典研究工作。这些工作包括基于Transformer架构的摘要模型优化、针对隐私政策的细粒度分类方法,以及结合领域知识的预训练语言模型微调策略。此外,该数据集也常被用于评估模型在专业领域中的泛化能力和鲁棒性,推动了法律自然语言处理技术向实用化、精细化方向发展。
以上内容由遇见数据集搜集并总结生成


