TurkicTTS-Chuvash
收藏Hugging Face2025-04-28 更新2025-04-29 收录
下载链接:
https://huggingface.co/datasets/gaydmi/TurkicTTS-Chuvash
下载链接
链接失效反馈官方服务:
资源简介:
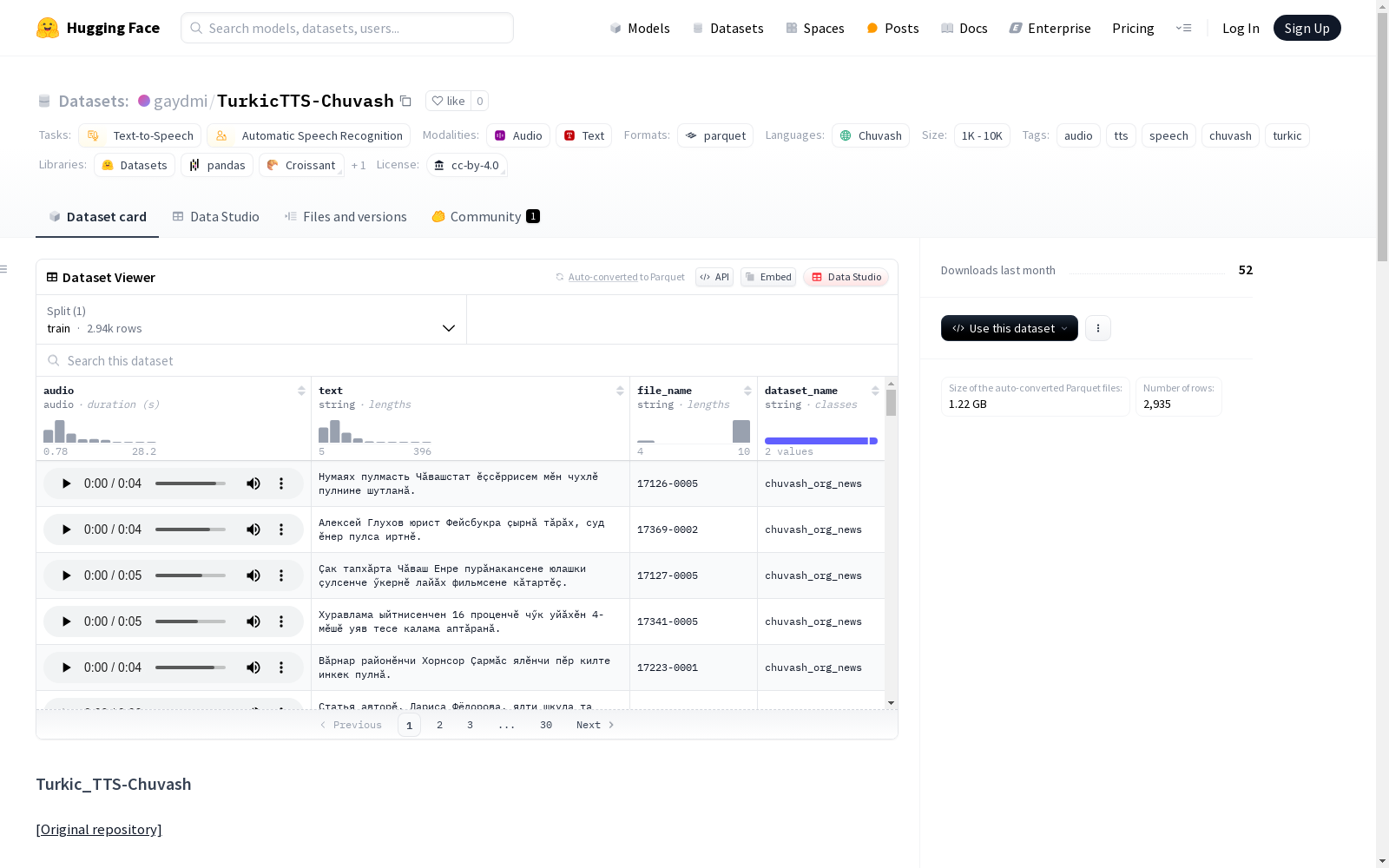
Turkic_TTS-Chuvash是一个Chuvash语言的语音数据集,包含了从chuvash.org网站新闻文章中提取的文本和数字列表的录音,由一位女性说话者在快速语速下朗读。该数据集旨在用于Chuvash语言文本到语音(TTS)的研究与开发。
Turkic_TTS-Chuvash is a speech dataset for the Chuvash language. It comprises recordings of text and numerical lists extracted from news articles on the chuvash.org website, which were read aloud by a female speaker at a fast speaking rate. This dataset is intended for research and development of Chuvash language text-to-speech (TTS) systems.
创建时间:
2025-04-27
原始信息汇总
Turkic_TTS-Chuvash 数据集概述
数据集摘要
- 来源:Turkic_TTS GitHub 仓库
- 内容:楚瓦什语新闻文章和数字列表的录音,由一位女性说话者以快速语速朗读
- 用途:楚瓦什语的文本到语音(TTS)研究和开发
- 许可:CC BY-SA 4.0
数据集结构
- 配置名称:news_plus_digits
- 特征:
- audio:音频文件
- text:楚瓦什语转录文本
- file_name:原始文件名(新闻部分为新闻页面ID)
- dataset_name:子集标识(chuvash_org_news 或 digits)
- 子集:
- chuvash_org_news:来自 chuvash.org 的新闻文章文本
- digits:数字录音
数据处理
- 文本处理:未进行规范化或预处理
- 音频处理:
- 在停顿处分割完整录音
- 每个文件开头和结尾修剪3秒
- 技术细节:
- 数据集类型:TTS语音语料库
- 语言:楚瓦什语(cv/chv)
- 语音风格:脚本独白
- 内容:新闻和数字列表
- 音频参数:44.1 kHz,32位,单声道
- 文件格式:WAV(PCM),TXT(UTF-8)
- 录音环境:安静的室内环境
- 总时长:
- 新闻:04:08:49
- 数字:01:01:39
使用注意事项
- 数据集未经过广泛预处理,建议用户根据需要进行额外预处理
- 存在缩写和特殊符号发音不一致的情况
引用
bib @misc{tyers2018speechsynthesis, title={{Speech synthesis on a shoe string}}, author={Tyers, F. M.}, year={2018}, howpublished={Presentation at Computational Methods for Endangered Language Documentation and Description}, address={Paris, France}, date={2018-02-01}, }
许可
- 许可证:CC BY-SA 4.0
搜集汇总
数据集介绍
构建方式
TurkicTTS-Chuvash数据集构建于楚瓦什语这一突厥语族语言的语音合成研究需求,其核心语料来源于chuvash.org新闻文本及数字列表的朗读录音。数据采集采用单一女性发音人以快速语速进行脚本化独白录制,音频文件经专业分割处理——在语句停顿处切分,并统一去除首尾各3秒空白段。原始文本保留未经标准化的自然形态,包括缩写、特殊符号等语言现象,真实反映实际发音特征。技术层面采用44.1kHz采样率、32位深度的单声道WAV格式存储,配套UTF-8编码的文本转录文件,形成结构化平行语料库。
特点
该数据集呈现鲜明的低资源语言研究特色,包含新闻(4小时8分)与数字(1小时1分)两大主题子集,通过dataset_name字段实现精细分类。音频特征方面,快速语速的发音风格为语音合成系统提供了特殊的韵律建模挑战,而未经处理的原始文本则完整保留了楚瓦什语特有的语言现象如'чӑв.'等缩写变体。每个样本均标注新闻网页ID溯源信息,兼具语言学研究的可追溯性与语音技术的实用性。作为目前稀有的楚瓦什语语音库,其安静室内环境录制的纯净音质为声学模型训练提供了理想条件。
使用方法
研究者可通过HuggingFace平台直接加载news_plus_digits配置,使用标准音频处理工具链解析parquet格式数据。建议应用前针对具体任务进行文本规范化处理,特别是应对缩写词与特殊符号的发音变体制定统一规则。该数据集适用于端到端语音合成系统训练,亦可服务于低资源语言ASR模型开发。使用中需注意不同子集的时长分布差异,新闻语料更适合连续语音建模,数字部分则适用于孤立词识别研究。根据许可证要求,任何衍生成果需遵循CC-BY-SA 4.0协议明确标注数据来源。
背景与挑战
背景概述
TurkicTTS-Chuvash数据集由研究者F. M. Tyers于2018年构建,旨在支持楚瓦什语的文本转语音(TTS)研究。该数据集主要来源于楚瓦什语新闻网站chuvash.org的新闻文本及数字列表,由一位女性说话人以较快语速录制完成。作为突厥语族中资源较少的语言,楚瓦什语在语音技术领域长期面临数据稀缺的困境,该数据集的发布为低资源语言的语音合成研究提供了重要素材,并在计算语言学与濒危语言保护领域产生了积极影响。
当前挑战
该数据集的核心挑战体现在两方面:其一,楚瓦什语作为黏着语具有复杂的形态结构,其语音合成需解决音素连接与韵律建模等语言学难题;其二,数据构建过程中存在发音不一致性(如缩写词处理)、音频分段依赖人工静默检测等技术局限。此外,单一说话人样本与有限领域文本(新闻/数字)的覆盖范围,可能制约模型在多样化场景中的泛化能力。
常用场景
经典使用场景
在语音合成技术的研究中,TurkicTTS-Chuvash数据集为楚瓦什语的文本到语音转换提供了宝贵的资源。该数据集包含了新闻文章和数字的录音,适用于训练和评估TTS模型。由于楚瓦什语属于突厥语系,资源相对稀缺,该数据集填补了这一领域的空白,为研究者提供了高质量的语音数据。
实际应用
在实际应用中,TurkicTTS-Chuvash数据集可用于开发楚瓦什语的语音助手、有声读物和语言学习工具。其新闻和数字的多样化内容使得生成的语音更加自然和实用,适用于教育、媒体和公共服务等多个领域。
衍生相关工作
基于TurkicTTS-Chuvash数据集,研究者们开发了多种针对低资源语言的TTS模型。这些工作不仅提升了楚瓦什语的语音合成质量,还为其他突厥语系语言的语音技术研究提供了参考。部分研究还探索了数据增强和迁移学习在该数据集上的应用,进一步拓展了其学术价值。
以上内容由遇见数据集搜集并总结生成


