neural-bridge/rag-dataset-12000
收藏Hugging Face2024-02-05 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/neural-bridge/rag-dataset-12000
下载链接
链接失效反馈官方服务:
资源简介:
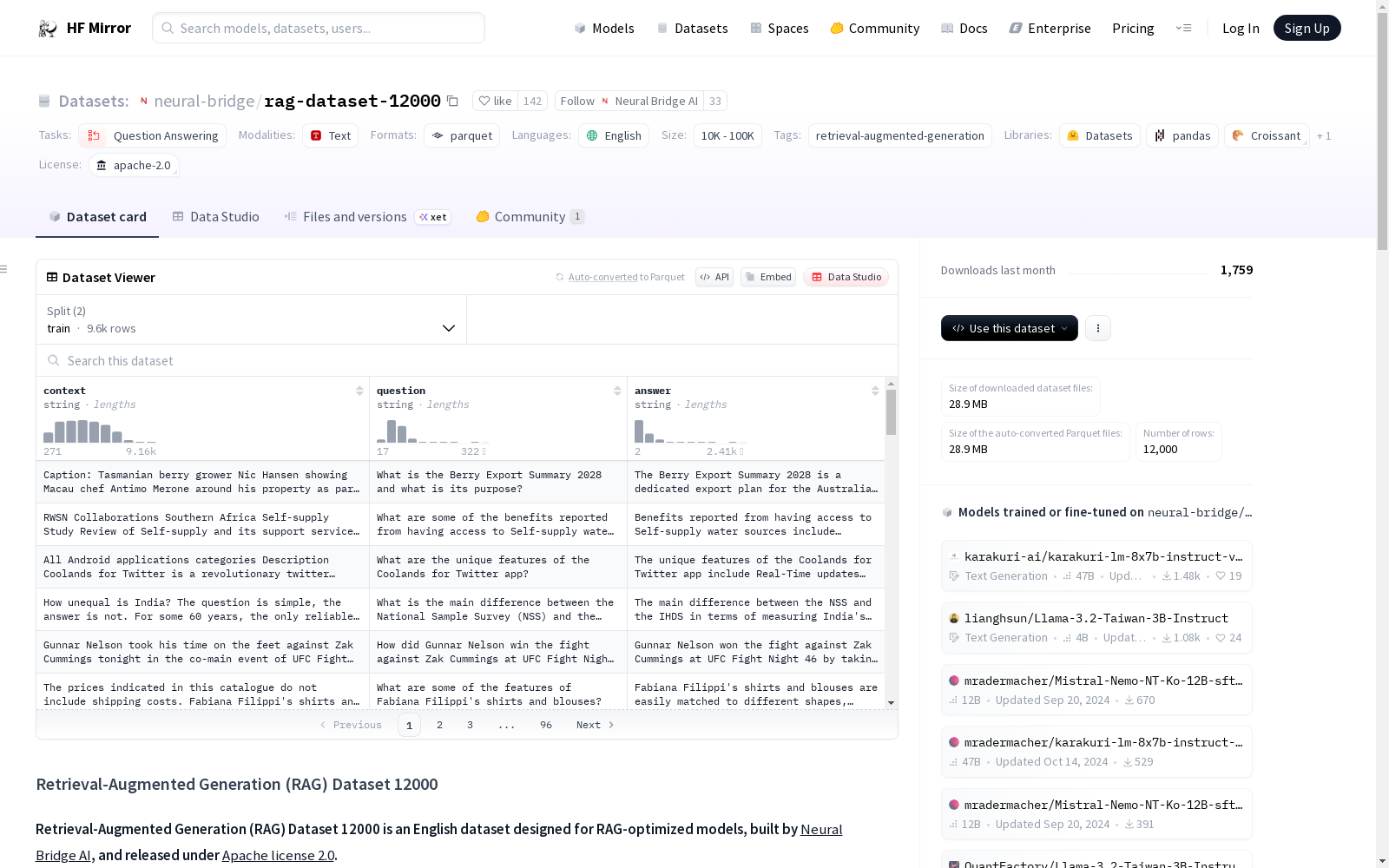
Retrieval-Augmented Generation (RAG) Dataset 12000是一个英语数据集,专为优化RAG模型而设计。该数据集由Neural Bridge AI构建,包含12000个条目,每个条目由context、question和answer三个字段组成。上下文数据来源于Falcon RefinedWeb,问题和答案由GPT-4生成。数据集分为训练集和测试集,分别包含9600和2400个样本。该数据集遵循Apache 2.0许可证。
Retrieval-Augmented Generation (RAG) Dataset 12000 is an English dataset specifically designed for optimizing RAG models. Constructed by Neural Bridge AI, this dataset comprises 12,000 entries, each containing three fields: context, question and answer. The context data is sourced from Falcon RefinedWeb, while the questions and answers are generated by GPT-4. The dataset is split into training and test sets, which contain 9,600 and 2,400 samples respectively. This dataset is licensed under the Apache 2.0 license.
提供机构:
neural-bridge
原始信息汇总
数据集概述
数据集名称
Retrieval-Augmented Generation (RAG) Dataset 12000
数据集描述
- 目的: 用于构建RAG优化模型,增强大型语言模型(LLMs)的能力,通过访问外部权威知识库来生成响应。
- 特点: 通过扩展模型到特定领域或组织内部数据,无需重新训练,提高输出的相关性、准确性和上下文特定性。
数据集结构
- 特征:
context: 字符串类型,包含一系列令牌。question: 字符串类型,与上下文相关的问题。answer: 字符串类型,问题的答案。
- 数据分割:
train: 9600个样本。test: 2400个样本。
语言
- 语言: 英语 (
en)
许可证
- 许可证: Apache License 2.0
数据来源
数据示例
json { "context": "...", "question": "...", "answer": "..." }
搜集汇总
数据集介绍
构建方式
该数据集由Neural Bridge AI构建,名为Retrieval-Augmented Generation (RAG) Dataset 12000,专为优化RAG模型而设计。数据集采集自Falcon RefinedWeb,包含12000条数据,每条数据由上下文(context)、问题(question)和答案(answer)构成,其中问题与答案由GPT-4生成,旨在助力RAG模型的构建。
使用方法
使用该数据集时,用户需遵循Apache 2.0许可及Falcon RefinedWeb的使用条款。数据集分为训练集和测试集,可通过Hugging Face的load_dataset函数轻松加载,便于模型训练与评估。
背景与挑战
背景概述
在人工智能领域,尤其是在自然语言处理(NLP)的应用研究中,Retrieval-Augmented Generation (RAG) 技术的兴起为大型语言模型(LLM)赋予了新的生命力。RAG Dataset 12000,由 Neural Bridge AI 构建并于某年某月发布,是在这一技术背景下诞生的数据集。该数据集遵循 Apache 2.0 许可,包含12000条数据,旨在优化 RAG 模型的训练。数据集由上下文、问题和答案三个字段构成,其内容源自 Falcon RefinedWeb 数据集,问题的答案由 GPT-4 生成,为研究 RAG 技术提供了丰富的实验材料。
当前挑战
RAG Dataset 12000 在构建和应用过程中面临的挑战主要包括:如何确保模型在引用外部知识库时能够生成准确且相关的回答,以及如何在保持模型响应的时效性和准确性的同时,避免传播错误或非权威信息。此外,数据集的构建还需克服如何在庞大的数据集中维持高质量的数据一致性,以及如何在遵循 Apache 2.0 许可和 Falcon RefinedWeb 使用条款的同时,保护数据的使用和隐私权益。这些挑战对于提升 RAG 技术在实际应用中的可靠性至关重要。
常用场景
经典使用场景
在人工智能领域,特别是在自然语言处理任务中,Retrieval-Augmented Generation (RAG) Dataset 12000 被广泛用于优化模型以实现检索增强生成。该数据集通过提供包含上下文、问题及答案的三元组,使模型能够在生成回答前咨询外部权威知识库,从而显著提升其生成相关、准确且具针对性的输出的能力。
解决学术问题
该数据集解决了传统大型语言模型(LLMs)在回应中存在的不确定性、依赖静态且可能过时的训练数据,以及传播错误或非权威信息的风险等问题。RAG Dataset 12000 的应用,提高了AI系统在处理问题回答等任务时的准确性和可靠性,增强了用户对AI应用的信任。
实际应用
实际应用中,RAG Dataset 12000 可用于构建能够即时更新信息、提供精确信息源归因的AI系统,这些系统在医疗诊断辅助、金融风险评估、法律咨询等领域具有重要的实用价值,能够有效提升服务的质量和效率。
数据集最近研究
最新研究方向
在自然语言处理领域,检索增强生成(Retrieval-Augmented Generation, RAG)技术正日益受到关注。该技术通过允许大型语言模型(LLM)在生成响应前咨询外部权威知识库,显著提升了模型产生相关、准确、且具体于上下文的输出能力。neural-bridge/rag-dataset-12000数据集为此研究提供了重要资源,其包含了9600个训练样本和2400个测试样本,每个样本由上下文、问题和答案构成。该数据集的发布,不仅推动了模型在问答等任务中的性能优化,也为成本效益的实现和维护、实时信息的获取、用户信任度的提升及开发者对信息检索流程的更大控制权提供了可能。当前研究正聚焦于如何更有效地结合LLM与外部知识库,以解决LLM在响应不可预测性、依赖静态训练数据及传播非权威信息方面的固有挑战。
以上内容由遇见数据集搜集并总结生成


