AgentPublic/legi
收藏Hugging Face2026-05-09 更新2025-08-09 收录
下载链接:
https://hf-mirror.com/datasets/AgentPublic/legi
下载链接
链接失效反馈官方服务:
资源简介:
法国汇编法律数据集,包含了自1945年以来有效的法律、法规、命令等法律文件。数据集经过BAAI/bge-m3模型处理,每个文章内容块都被向量化,便于进行法律文件的语义搜索、增强生成等研究。数据集以Parquet格式提供,包含了文章的唯一标识符、来源标识符、文章序号、法律文件类型、负责部门、文章状态、标题、完整标题、子标题、文章编号、生效日期、失效日期、附加注释、文本内容块、格式化文本块以及嵌入向量等信息。
The French Consolidated Legislation Dataset (LEGI) contains the full consolidated text of national legislation and regulations since 1945, including various legal documents such as laws, regulations, decrees, etc. Processed with the BAAI/bge-m3 model, each article chunk is vectorized, facilitating semantic search and retrieval-augmented generation in legal research. The dataset is provided in Parquet format, including unique identifiers for articles, source identifiers, article numbers, types of legal documents, responsible departments, article statuses, titles, full titles, subtitles, article numbers, effective dates, expiration dates, additional notes, text chunks, formatted text chunks, and embedding vectors.
提供机构:
AgentPublic
原始信息汇总
数据集概述:French Consolidated Legislation Dataset (LEGI)
- 数据集名称:French Consolidated Legislation Dataset (LEGI)
- 所有者:AgentPublic
- 规模:1M - 10M 行(本预览显示约 2.16M 行)
- 模态:文本
- 语言:法语
- 许可证:etalab-2.0
- 标签:france, legislation, law, loi, codes, embeddings
- 数据集卡片摘要:该数据集包含法国国家立法与法规(源自官方 LEGI 数据库)的全量合并文本的语义就绪版本,并已嵌入向量。原始数据来自 DILA 开放数据仓库。
数据内容与元数据
该数据集包含了自 1945 年以来法国的各类法律文本,包括:
- 法律类型:所有法律(laws)、法典(codes)、法令(decrees)、通告(circulars)、审议(deliberations)、法令-法律(decree-laws)、条例(ordinances)等,以及选定的合并部颁令(ministerial orders)。包含所有现行与已废止的官方法典。
- 法律状态:包含全部状态,如现行(VIGUEUR)、已修改(MODIFIE)、延期废除(ABROGE_DIFF)、已废除(ABROGE)、已撤销(ANNULE)、已分离(DISJOINT)、修改胎死(MODIFIE_MORT_NE)、过时(PERIME)和已转移(TRANSFERE)。
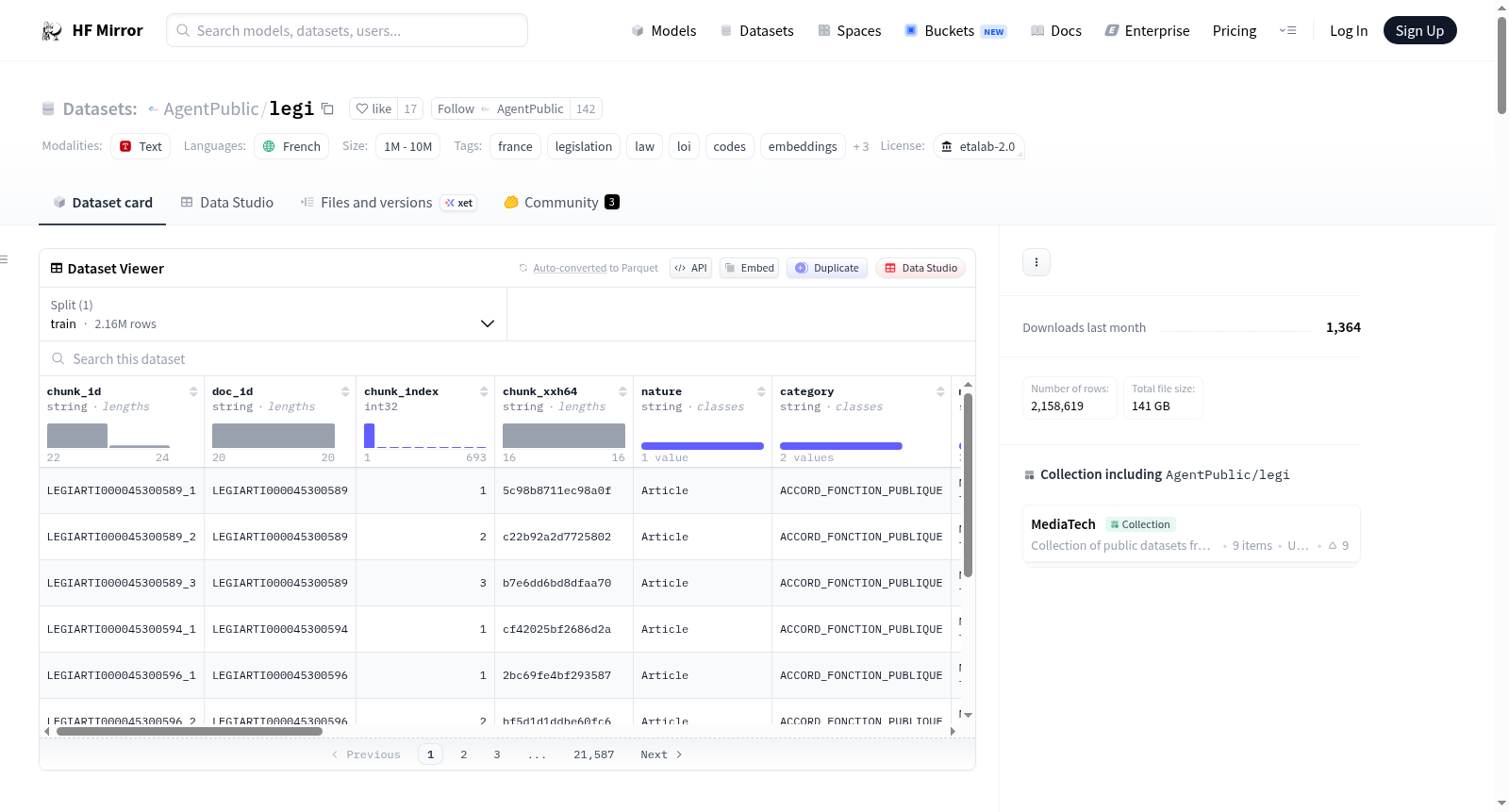
主要字段(依据预览数据):
| 字段名 | 描述(推断) | 示例/类型 |
|---|---|---|
chunk_id |
文本块唯一标识符 | LEGIARTI000045300589_1 |
doc_id |
原始文档标识符 | LEGIARTI000045300589 |
chunk_index |
块在文档内的序号 | 1 |
nature |
法律文本性质 | Article |
category |
法律文本类别 | ACCORD_FONCTION_PUBLIQUE |
ministry |
负责部委 | Ministère de la transformation et de la fonction publiques |
status |
法律状态 | VIGUEUR |
title |
标题 | Accord collectif |
full_title |
完整标题 | Accord interministériel relatif à la protection sociale ... |
number |
法律编号 | 8 bis |
start_date |
生效日期 | 2022-03-07 |
end_date |
失效日期 | 2999-01-01 |
links |
相关法律链接(JSON) | [{"nor": "", "title": "Loi n° 83-634 du 13 juillet 1983 ... |
text |
原始文本内容 | Entre :LEtat, représenté par la ministre ... |
chunk_text |
合并后的文本块 | Accord interministériel relatif à la protection sociale ... |
embeddings_bge-m3 |
BGE-M3 模型生成的向量嵌入 | [-0.0032138238,0.014584207,...] |
数据处理与方法论
根据页面底部的“Dataset Contents”部分,该数据集通过以下流水线生成:
- 字段提取 (Field Extraction):
- 从原始 LEGI 数据中提取结构化字段(如
nature,category,ministry,status等)。
- 从原始 LEGI 数据中提取结构化字段(如
- 生成文本块 (Generation of chunk_text):
- 将原始文本(
text)与full_title、subtitles等元数据合并,生成语义完整的文本块chunk_text。此过程可能涉及分块处理以适配嵌入模型。
- 将原始文本(
- 嵌入向量生成 (Embeddings Generation):
- 使用 BGE-M3 模型对
chunk_text进行向量化,生成embeddings_bge-m3字段,用于语义搜索与检索增强生成(RAG)任务。
- 使用 BGE-M3 模型对
使用与许可
- 许可证:
etalab-2.0 - 数据来源:法国 Légifrance 官方 LEGI 数据库(由 DILA 提供开放数据)。
- 数据分割:数据集包含一个 train 分割,共约 2.16M 行(为最新版本
latest)。
搜集汇总
数据集介绍
构建方式
该数据集源自法国官方LEGI数据库,由DILA开放数据平台发布,涵盖自1945年以来所有法律、法规、法令等立法文本。数据以Parquet格式存储,每个法律条文被作为独立文档处理,并利用Langchain的RecursiveCharacterTextSplitter进行智能分块,其中块大小设为1024个token且无重叠。每个文本块均通过BAAI/bge-m3嵌入模型生成语义向量,同时保留原始元数据字段,如条文状态、生效日期、链接关系等,形成语义就绪的向量化版本。
特点
该数据集的核心特点在于其全面性与语义化处理。它囊括了法律条文的所有法律状态,包括现行、修改、废止、延期生效等十余种类别,覆盖法国全境立法全貌。每个条文被分块并嵌入高维向量,支持语义检索与检索增强生成应用。数据集按立法类别和法典进行子文件夹组织,便于按需选取。此外,chunk_text字段整合了标题、编号与正文,嵌入向量以JSON字符串形式存储,兼顾实用性与兼容性。
使用方法
用户可通过Hugging Face的datasets库加载数据集,并利用json.loads解析嵌入向量为浮点列表,进而插入向量数据库或直接用于RAG流程。若需重新分块或重构原始完整文本,可参考官方提供的GitHub教程笔记本。为简化筛选特定状态的条文,建议查阅专用教程以排除不需要的状态。数据以Parquet格式存储,支持Pandas的read_parquet方法读取,适配下游分析与检索系统搭建。
背景与挑战
背景概述
法国 consolidated 立法数据集(LEGI)由法国数字事务部下属的 MediaTech 团队于近期创建,旨在将法国官方 LEGI 数据库中的国家法律法规全文进行语义化处理与向量化嵌入。该数据集源于 DILA 开放数据仓库,涵盖了自 1945 年以来所有法律、法规、法令、通告等立法文本,并整合了包括现行、已修改、已废止等多种法律状态。其核心研究问题在于为语义搜索、检索增强生成(RAG)及法律研究系统提供结构化、可语义检索的立法数据资源。通过嵌入 BAAI/bge-m3 模型生成的向量,LEGI 数据集在自然语言处理与法律信息检索领域具有重要影响力,为自动化法律咨询、法规一致性分析及跨文本关联发现开辟了新路径。
当前挑战
LEGI 数据集面临的挑战一方面源于领域问题的复杂性:法国立法体系庞大且状态多样,不同法律状态(如“废止中”、“转移”、“过期”)的精准区分与语义表示对模型理解能力提出高要求,需在保持法律准确性的同时实现高效检索。另一方面,数据构建过程需应对多源异构元数据的整合难题,包括从原始 LEGI 元数据中提取字段、处理超长文本的自然切分(采用 RecursiveCharacterTextSplitter 并保证无重叠),以及确保各法律状态的分类一致性。此外,嵌入向量的存储与解析(如字符串形式需手动还原为浮点数列表)也增加了下游使用的技术门槛。
常用场景
经典使用场景
在法国法律信息学研究中,该数据集最经典的使用场景是基于语义检索的法律条文定位。依托BAAI/bge-m3模型对法律文本进行向量化嵌入,研究者能够在庞杂的法典、法律、法令和行政命令中快速找到与查询语义高度相关的条款。其分块策略保证了即使是超长条款也能被合理切割,同时保留完整的元数据信息,使得检索结果可以精确到具体段落与时效状态。这一能力大幅提升了传统关键词检索的召回率和精准度,为法律文本的智能分析奠定了数据基础。
解决学术问题
该数据集解决了法律人工智能领域中长期存在的结构化数据稀缺与时效性标注困难的问题。传统法律数据集往往只涵盖法规的原始文本,缺少对法律状态(如生效、废止、修改)的精确编码。LEGI数据集通过引入八种不同的时效状态标签,并记录每条内容的起止日期,使得研究者能够构建时间敏感型的法律推理模型、裁判预测系统以及法规演化分析工具。它促进了法律文本的时序建模与状态分类研究,为法律计算学贡献了宝贵的标准化资源。
衍生相关工作
基于LEGI数据集,学界与工业界已衍生出一系列经典工作。在工具链层面,MediaTech项目提供了完整的重建管道与RAG教程,允许研究者将分块后的数据回连为原始文档或直接对接向量数据库。在学术方向上,有工作利用其时间戳和状态标签进行法律的演化轨迹分析,也有研究以该数据集为基准测试司法语境下的语义相似度模型。此外,French Law Embeddings项目以LEGI为核心语料训练专用法律嵌入器,推动了法语法律NLP范式的标准化进程。这些衍生工作共同构成了一个围绕法国立法数据的活跃研究生态。
以上内容由遇见数据集搜集并总结生成


