reddit_dataset_127
收藏Hugging Face2025-05-12 更新2025-05-13 收录
下载链接:
https://huggingface.co/datasets/James096/reddit_dataset_127
下载链接
链接失效反馈官方服务:
资源简介:
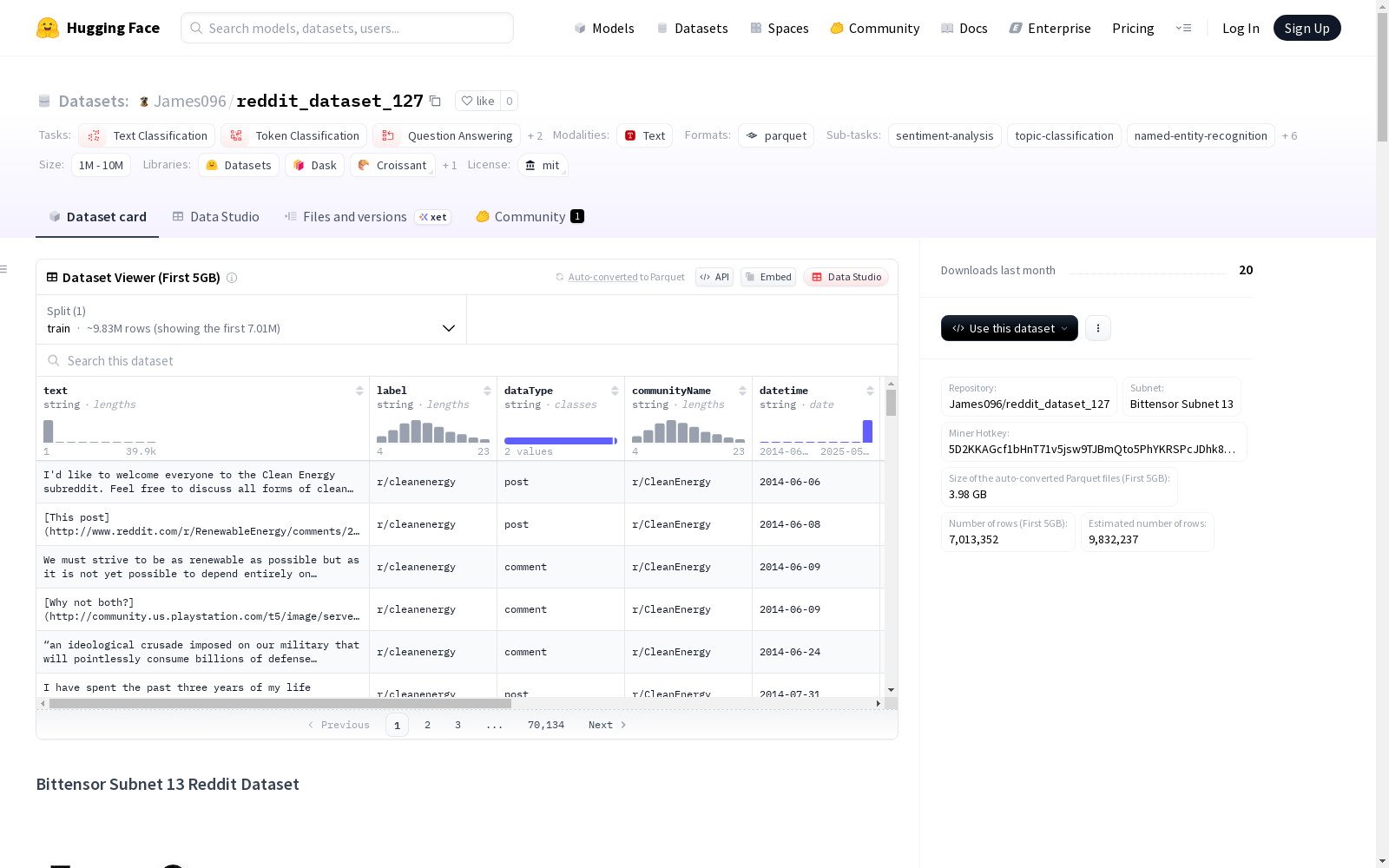
Bittensor Subnet 13 Reddit数据集是Bittensor Subnet 13去中心化网络的一部分,包含预处理后的Reddit公开帖子和评论数据。这个数据集支持多种自然语言处理任务,包括情感分析、主题建模、社区分析、内容分类等。数据集主要包含英文数据,但也可能是多语言的。每个数据实例包括文本内容、标签、数据类型、社区名称、日期时间、编码后的用户名和URL等字段。数据集持续更新,用户可以根据自己的需求和数据的时间戳来创建数据分割。数据来源于Reddit平台,遵守相关服务条款和API使用指南,并对个人信息进行编码处理以保护隐私。
The Bittensor Subnet 13 Reddit Dataset is part of the decentralized Bittensor Subnet 13 network, containing preprocessed public Reddit posts and comment data. This dataset supports a wide range of natural language processing tasks, including sentiment analysis, topic modeling, community analysis, content classification, and more. The dataset primarily consists of English-language data, but may also include multilingual content. Each data instance includes fields such as text content, labels, data type, community name, date and time, encoded usernames and URLs, and other relevant fields. The dataset is continuously updated, and users can create custom data splits based on their specific needs and the timestamps of the data. The dataset is sourced from the Reddit platform, complies with the platform's applicable terms of service and API usage guidelines, and encodes personal information to protect user privacy.
创建时间:
2025-05-08
原始信息汇总
数据集概述:Bittensor Subnet 13 Reddit Dataset
基本信息
- 仓库名称: James096/reddit_dataset_127
- 许可证: MIT
- 多语言支持: 多语言(主要为英语)
- 子网: Bittensor Subnet 13
- 矿工Hotkey: 5D2KKAGcf1bHnT71v5jsw9TJBmQto5PhYKRSPcJDhk8gqSXj
数据集描述
- 来源: 原始数据(Reddit公开帖子和评论)
- 更新频率: 实时更新
- 用途: 文本分类、标记分类、问答、摘要、文本生成等
数据结构
数据字段
text: 帖子或评论的主要内容label: 内容的情感或主题类别dataType: 帖子或评论的类型communityName: 发布内容的子版块名称datetime: 发布时间username_encoded: 编码后的用户名url_encoded: 编码后的URL
数据实例
- 总实例数: 2,198,949
- 时间范围: 2014-06-06至2025-05-13
- 最后更新时间: 2025-05-13
数据分布
- 帖子占比: 3.46%
- 评论占比: 96.54%
热门子版块(Top 10)
| 排名 | 子版块 | 数量 | 占比 |
|---|---|---|---|
| 1 | r/AskReddit | 82,259 | 3.74% |
| 2 | r/AITAH | 54,183 | 2.46% |
| 3 | r/politics | 53,782 | 2.45% |
| 4 | r/AmIOverreacting | 52,891 | 2.41% |
| 5 | r/wallstreetbets | 46,396 | 2.11% |
| 6 | r/mildlyinfuriating | 44,835 | 2.04% |
| 7 | r/nba | 43,154 | 1.96% |
| 8 | r/NoStupidQuestions | 43,075 | 1.96% |
| 9 | r/teenagers | 42,419 | 1.93% |
| 10 | r/GOONED | 41,960 | 1.91% |
更新历史
| 日期 | 新增实例 | 总实例 |
|---|---|---|
| 2025-05-08 | 36,948 | 36,948 |
| 2025-05-10 | 34,434 | 71,382 |
| 2025-05-10 | 86,590 | 157,972 |
| 2025-05-11 | 547,082 | 705,054 |
| 2025-05-12 | 667,301 | 1,372,355 |
| 2025-05-13 | 826,594 | 2,198,949 |
注意事项
- 隐私保护: 用户名和URL已编码处理
- 潜在偏见: 数据可能存在人口统计和内容偏见
- 局限性: 数据质量不一,可能包含噪声或无关内容
引用信息
bibtex @misc{James0962025datauniversereddit_dataset_127, title={The Data Universe Datasets: The finest collection of social media data the web has to offer}, author={James096}, year={2025}, url={https://huggingface.co/datasets/James096/reddit_dataset_127}, }
搜集汇总
数据集介绍
构建方式
在社交媒体分析领域,该数据集通过去中心化网络架构实现动态构建,依托Bittensor子网13的矿工节点持续采集Reddit平台的公开帖文与评论。数据源严格遵循平台服务条款与API规范,采用实时流式处理机制,确保内容涵盖2012年至2025年间逾千万条数据实例。所有用户标识与链接均经过编码处理,既保障隐私合规性又维持数据可用性,形成具有时序连续性的社交语料库。
特点
该数据集呈现多维度特征,其文本内容覆盖情感分析、主题分类等自然语言处理任务,内含1.09亿条实例中评论占比达96.55%。数据结构包含文本内容、社区分类、时间戳等七个字段,支持对社交动态的细粒度解析。值得注意的是,数据分布呈现典型的长尾效应,前十大社区如r/AskReddit仅占1.4%,这种稀疏性为研究社区演化规律提供了独特视角,同时多语言混杂特性反映了去中心化采集的天然属性。
使用方法
研究者可基于该数据集构建动态学习框架,利用其持续更新特性开发实时分析模型。由于未预设固定划分,建议按时间戳构建自定义训练验证集,结合社区名称字段实现垂直领域研究。在具体应用中,可通过文本字段进行语义建模,借助标签字段监督分类任务,利用时间字段分析舆论演化趋势。需特别注意数据固有的社交平台偏差,建议采用去偏技术提升模型泛化能力,同时遵循MIT许可与Reddit使用条款进行合规部署。
背景与挑战
背景概述
社交媒体的兴起催生了大规模文本分析的需求,reddit_dataset_127作为Bittensor Subnet 13去中心化网络的重要组成部分,由James096等研究人员于2025年构建。该数据集聚焦于Reddit平台的公开内容,旨在通过实时更新的社交数据支持情感分析、主题建模等自然语言处理任务,其覆盖2012至2025年的时间跨度与千万级数据规模,为研究在线社区动态提供了重要基础。
当前挑战
该数据集需应对社交媒体内容固有的语义噪声与主题漂移问题,例如俚语表达与多义性文本对分类准确性的干扰。构建过程中面临数据质量控制的挑战,包括去中心化采集导致的格式不一致性、用户隐私保护与信息编码的平衡,以及实时流数据中垃圾内容过滤的技术难题。
常用场景
经典使用场景
在社交媒体分析领域,该数据集作为Reddit平台内容的系统化集合,为自然语言处理研究提供了丰富的实验材料。其最经典的应用场景在于情感分析与主题建模,研究人员通过分析用户发帖与评论的文本特征,能够深入理解网络社区中的情绪分布与话题演变规律。该数据集支持对特定子版块进行细粒度分析,例如通过r/AskReddit和r/politics等热门版块的数据追踪社会议题的舆论走向。
实际应用
商业场景中,该数据集为品牌舆情监控提供了实时数据支撑。企业可通过分析产品相关子版块的情感倾向,及时调整市场策略。在公共服务领域,政府机构能借助政治类版块的数据洞察民意动向,例如通过r/politics的讨论热点预测政策反响。教育机构则利用其构建对话系统训练数据,提升人工智能对网络用语的理解能力。
衍生相关工作
基于该数据集的特性,已催生多项创新研究。在去中心化数据采集领域,Bittensor子网络的架构为分布式数据治理提供了新范式。自然语言处理方面,结合时序特征的动态主题模型通过该数据集实现了对网络迷因传播路径的可视化。此外,跨社区对比分析工作通过r/AITAH与r/AmItheAsshole等道德讨论版块,建立了网络道德决策的计算分析框架。
以上内容由遇见数据集搜集并总结生成


