MEBench
收藏arXiv2025-05-26 更新2025-05-28 收录
下载链接:
http://arxiv.org/abs/2505.20122v1
下载链接
链接失效反馈官方服务:
资源简介:
MEBench是一个用于评估视觉语言模型中相互排斥(ME)偏差的新基准。这个数据集模拟了儿童在词汇爆发阶段学习新词汇时的认知现象。MEBench不仅包含了传统的ME任务,还进一步整合了空间推理,以创建更具挑战性和现实性的评估设置。该数据集的开发过程包括从3D数据集中生成真实场景,并使用Blender软件创建新的物体。数据集的目的是为了解决视觉语言模型在复杂视觉场景中的推理问题,并评估它们在空间推理和上下文线索方面的能力。
MEBench is a novel benchmark for evaluating mutual exclusion (ME) biases in vision-language models. This dataset simulates the cognitive phenomenon that occurs when children learn new words during the vocabulary burst stage. MEBench not only incorporates traditional ME tasks but also integrates spatial reasoning to create more challenging and realistic evaluation settings. The dataset’s development pipeline involves generating realistic scenes from 3D datasets and creating new objects using Blender software. This benchmark aims to address the reasoning challenges of vision-language models in complex visual scenes, and evaluate their capabilities in spatial reasoning and contextual cues.
提供机构:
乔治亚理工学院, 伊利诺伊大学厄巴纳-香槟分校
创建时间:
2025-05-26
原始信息汇总
数据集概述:MEBench: A Novel Benchmark for Understanding Mutual Exclusivity Bias in Vision-Language Models
基本信息
- 标题: MEBench: A Novel Benchmark for Understanding Mutual Exclusivity Bias in Vision-Language Models
- arXiv标识符: arXiv:2505.20122v1
- 提交日期: 2025年5月26日
- 学科分类: Computer Vision and Pattern Recognition (cs.CV)
- DOI: https://doi.org/10.48550/arXiv.2505.20122
作者
- Anh Thai
- Stefan Stojanov
- Zixuan Huang
- Bikram Boote
- James M. Rehg
摘要
MEBench是一个用于评估互斥性(ME)偏见的全新基准。互斥性偏见是儿童在词汇学习过程中观察到的一种认知现象。与传统ME任务不同,MEBench进一步结合了空间推理,以创建更具挑战性和现实性的评估环境。我们使用新的评估指标评估了最先进的视觉语言模型(VLM)在该基准上的表现,这些指标捕捉了基于ME推理的关键方面。为了便于控制实验,我们还提供了一个灵活且可扩展的数据生成流程,支持构建多样化的注释场景。
相关链接
- PDF文档: http://arxiv.org/pdf/2505.20122v1
- HTML版本: http://arxiv.org/html/2505.20122v1
- TeX源代码: http://arxiv.org/format/2505.20122v1
提交历史
- 版本1: 2025年5月26日提交,文件大小3,835 KB
搜集汇总
数据集介绍
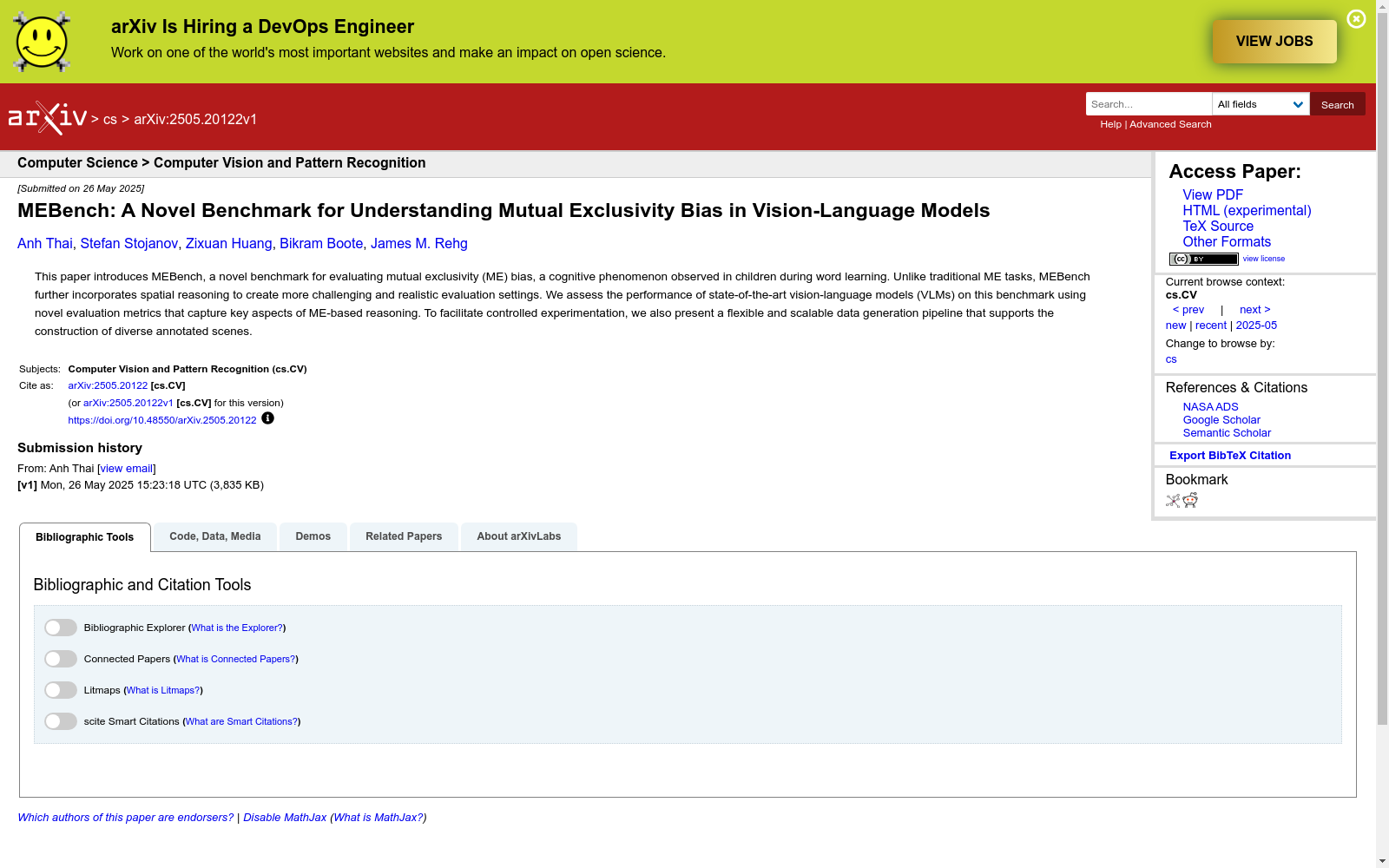
构建方式
MEBench数据集的构建采用了一种灵活且可扩展的合成数据生成流程,旨在评估视觉语言模型中的互斥性偏见。该流程首先从Toys4K数据集中选取已知对象类别,并通过Blender的几何节点程序化生成64种新颖对象,以防止数据泄露。随后,利用Infinigen生成多样化的室内场景作为背景,并通过刚体模拟实现自然物体摆放。每个场景从多个视角渲染,确保对象可见性,并生成包含空间关系的场景描述文本。这一方法不仅支持对互斥性偏见的经典测试,还通过引入空间推理任务扩展了评估维度。
特点
MEBench数据集的核心特点在于其系统性地模拟了儿童词汇习得中的互斥性认知偏见,并创新性地融入了空间推理要素。数据集包含三种渐进式难度的任务变体:基础对象定位(1K-0U)、经典互斥性测试(1K-1U/2K-1U)以及多新颖对象空间消歧(1K-2U)。通过精心设计的非英语伪词汇标签(如'dax')和程序化生成的新颖几何物体,有效避免了预训练模型的数据泄漏问题。场景描述中精确编码的物体空间关系(如'狗在blicket右侧')为评估模型的高阶推理能力提供了结构化基准。
使用方法
使用MEBench进行评估时,研究者需将视觉语言模型置于三类递进式任务中:首先检测并定位场景中的已知对象,随后应用互斥性假设将新标签与未知对象关联,最终在存在多个未知对象时结合空间描述进行消歧。评估指标包括对象检测的平均精度(AP@t)、标准化互斥性分数(ME)以及空间推理增益分数。基准测试要求模型处理224×224分辨率的渲染图像,并接受包含对象名称和空间关系的文本提示。为减少视角偏差,建议对每个场景进行三次不同视角的推理,并综合统计性能表现。
背景与挑战
背景概述
MEBench是由乔治亚理工学院和伊利诺伊大学厄巴纳-香槟分校的研究团队于2025年提出的新型基准测试,旨在评估视觉语言模型(VLMs)中的互斥性偏差(ME bias)。该数据集受到发展心理学中儿童词汇习得研究的启发,重点关注对象-标签映射问题,通过引入空间推理任务扩展了传统互斥性研究的范畴。MEBench通过可控的合成数据生成流程,构建了包含已知日常物品和程序生成新物体的复杂场景,为研究人工智能系统如何模拟人类认知偏差提供了标准化评估平台。该基准的建立标志着计算认知科学与多模态学习的交叉研究迈出了重要一步,为零样本泛化能力的提升奠定了理论基础。
当前挑战
MEBench面临的核心挑战体现在两个方面:在领域问题层面,传统视觉语言模型难以准确模拟人类互斥性认知偏差,特别是在多新物体场景中无法有效利用空间关系消除指代歧义;在构建技术层面,需解决合成数据真实性(如光照、材质渲染)与评估严谨性(如防止数据泄漏)之间的平衡问题,同时要设计能准确反映互斥性推理能力的评估指标。具体挑战包括:程序生成的新物体需确保在预训练词汇中完全不存在,复杂场景中物体空间关系的自然描述生成,以及开发能区分基础检测能力与高级推理能力的评估体系。
常用场景
经典使用场景
MEBench作为评估视觉语言模型(VLMs)互斥性偏见的基准,其经典使用场景主要集中在模拟儿童语言学习中的词汇映射过程。通过构建包含已知和未知物体的复杂场景,并引入新颖标签,该数据集能够系统地测试模型在零样本条件下识别未知物体并正确关联标签的能力。这一场景不仅复现了发展心理学中的经典实验范式,还通过引入空间推理任务,为模型评估增添了现实挑战性。
实际应用
在实际应用中,MEBench的评估范式可直接迁移至家庭机器人、人机交互等需要实时环境理解的领域。例如,服务机器人可通过互斥性偏见快速学习用户自定义的新物体名称,而无需重复训练。数据集生成管线支持的合成场景构建技术,也为教育科技领域开发语言学习工具提供了可扩展的解决方案,特别是在多模态认知训练系统的设计中。
衍生相关工作
该数据集已衍生出三类经典研究方向:一是基于CogVLM等模型的互斥性偏见增强方法,通过改进标签分配机制提升零样本学习能力;二是结合Gemini的空间推理优化研究,探索文本描述对物体关系理解的促进作用;三是针对合成数据泛化的后续工作,如Infinigen场景生成器的改进版本被广泛应用于其他需要可控实验的认知计算任务中。
以上内容由遇见数据集搜集并总结生成


