HPAI-BSC/medmcqa-cot
收藏Hugging Face2024-05-13 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/HPAI-BSC/medmcqa-cot
下载链接
链接失效反馈资源简介:
为了提升MedMCQA数据集训练分割的答案质量,我们利用Mixtral-8x7B模型生成Chain of Thought(CoT)答案。我们为该数据集创建了一个自定义提示,并手工制作了一些示例。对于多选题,我们要求模型重新表述并解释问题,然后解释每个选项与问题的关系,最后总结这些解释以得出最终答案。在生成合成数据的过程中,模型还会被提供解决方案和参考答案。如果模型未能生成正确的响应,我们会重新生成解决方案,直到生成正确的响应为止。更多细节可在相关论文中找到。
为了提升MedMCQA数据集训练分割的答案质量,我们利用Mixtral-8x7B模型生成Chain of Thought(CoT)答案。我们为该数据集创建了一个自定义提示,并手工制作了一些示例。对于多选题,我们要求模型重新表述并解释问题,然后解释每个选项与问题的关系,最后总结这些解释以得出最终答案。在生成合成数据的过程中,模型还会被提供解决方案和参考答案。如果模型未能生成正确的响应,我们会重新生成解决方案,直到生成正确的响应为止。更多细节可在相关论文中找到。
提供机构:
HPAI-BSC
原始信息汇总
数据集概述
基本信息
- 名称: medmcqa-cot
- 许可证: Apache 2.0
- 任务类别:
- 问答
- 多选题
- 语言: 英语
- 标签:
- 医学
- 生物学
- 大小范围: 100K<n<1M
数据集描述
该数据集通过使用Mixtral-8x7B生成思维链(CoT)答案,增强了MedMCQA数据集的训练分割答案质量。数据集创建过程中,模型会重新表述和解释问题,并对每个选项进行解释,最终总结得出最终答案。对于模型未能正确生成答案的情况,会重新生成解决方案直至得到正确答案。
数据集来源
数据集创建
- 目的: 提供一个基于medmcqa的高质量、易于使用的指令调优数据集。
引用信息
-
BibTeX:
@misc{gururajan2024aloe, title={Aloe: A Family of Fine-tuned Open Healthcare LLMs}, author={Ashwin Kumar Gururajan and others}, year={2024}, eprint={2405.01886}, archivePrefix={arXiv}, primaryClass={cs.CL} } @InProceedings{pmlr-v174-pal22a, title = {MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering}, author = {Pal, Ankit and others}, booktitle = {Proceedings of the Conference on Health, Inference, and Learning}, year = {2022}, publisher = {PMLR} }
AI搜集汇总
数据集介绍
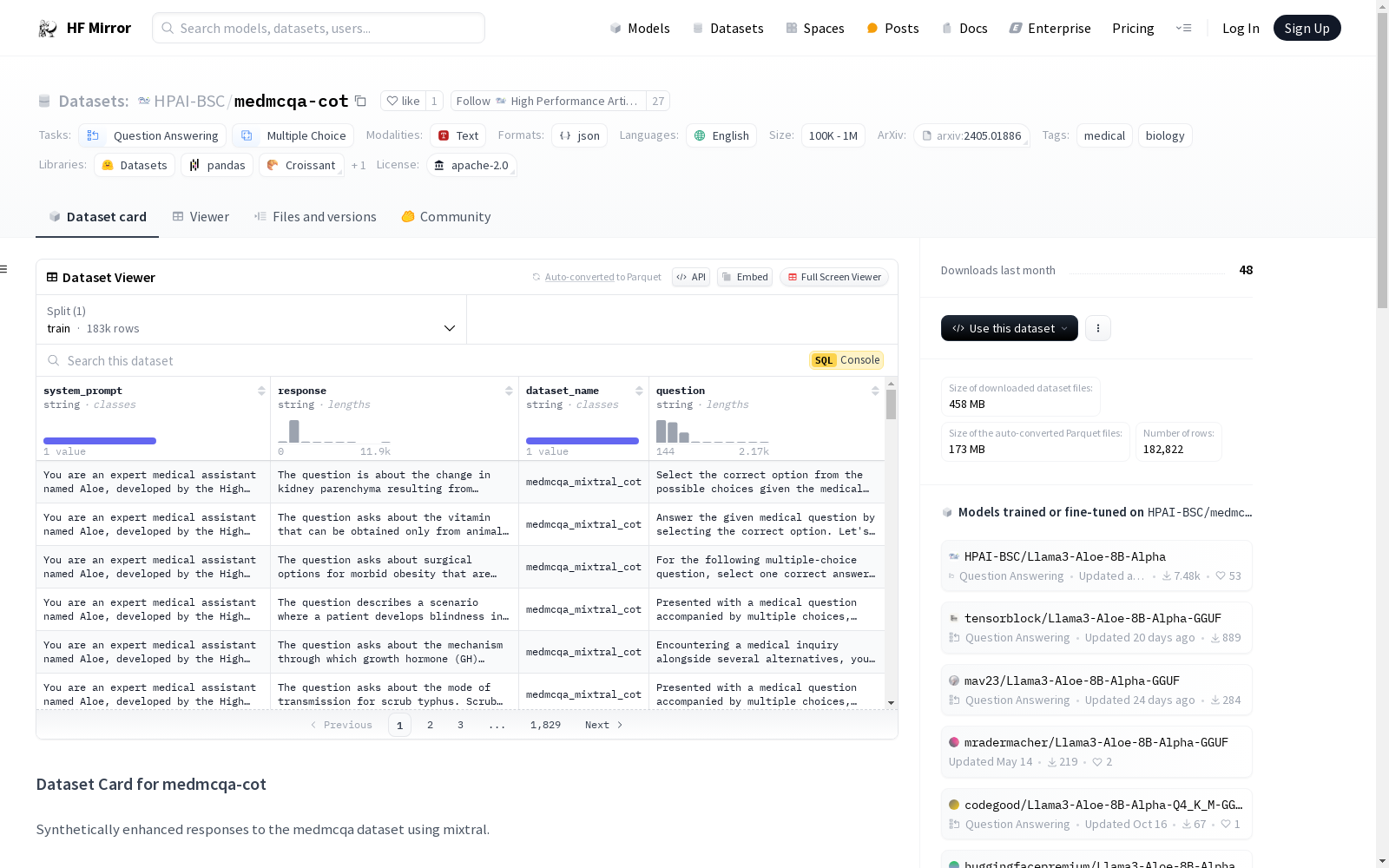
构建方式
在提升MedMCQA数据集训练分割答案质量的过程中,研究团队采用Mixtral-8x7B模型生成思维链(Chain of Thought, CoT)答案。通过设计自定义提示和手工编制的少量示例列表,模型被要求重新表述并解释问题,随后对每个选项进行详细分析,最终总结出最终解决方案。在合成数据生成过程中,模型不仅被提供正确答案,还对错误响应进行了重新生成,直至获得正确答案。这一过程确保了数据集的高质量和高可靠性。
使用方法
medmcqa-cot数据集适用于多种自然语言处理任务,特别是医学领域的问答系统和多选题解答模型。用户可以通过加载数据集,利用其丰富的答案解释和推理过程,进行模型训练和微调。此外,数据集的高质量答案和详细解释也为医学教育和研究提供了宝贵的资源,支持深度学习和理解医学知识。
背景与挑战
背景概述
在医疗领域,高质量的多选题问答数据集对于提升医学教育和临床决策支持系统的智能化水平至关重要。medmcqa-cot数据集由Ashwin Kumar Gururajan等人于2024年创建,旨在通过利用Mixtral-8x7B模型生成思维链(Chain of Thought, CoT)答案,增强MedMCQA数据集的训练分割答案质量。该数据集的核心研究问题是如何通过合成数据生成技术提升医学问答系统的准确性和解释性,从而推动医疗领域自然语言处理技术的发展。其对相关领域的影响力在于为医学教育和技术应用提供了丰富的、高质量的问答数据资源。
当前挑战
medmcqa-cot数据集在构建过程中面临的主要挑战包括:1) 如何设计有效的提示和少样本示例,以引导模型生成高质量的思维链答案;2) 如何处理模型在生成过程中出现的错误响应,确保最终答案的正确性。此外,该数据集还需解决医学问答领域特有的复杂性和多样性问题,如多选题的深度语言理解和多样的医学主题覆盖。这些挑战不仅影响了数据集的质量,也对后续研究提出了更高的要求。
常用场景
经典使用场景
在医学领域,HPAI-BSC/medmcqa-cot数据集被广泛应用于多选题问答系统的训练与评估。该数据集通过Mixtral-8x7B模型生成的思维链(Chain of Thought, CoT)答案,显著提升了医学问答系统的回答质量。其经典使用场景包括医学考试辅助系统、在线医学教育平台以及临床决策支持系统,这些系统依赖于高质量的问答数据来提供准确和详尽的医学知识解答。
解决学术问题
HPAI-BSC/medmcqa-cot数据集解决了医学领域中多选题问答系统面临的准确性和解释性问题。传统医学问答数据集往往缺乏详细的推理过程,导致模型在复杂问题上的表现不佳。该数据集通过引入思维链答案,不仅提供了正确答案,还详细解释了推理过程,从而帮助研究人员开发出更具解释性和可靠性的医学问答模型。
实际应用
在实际应用中,HPAI-BSC/medmcqa-cot数据集被用于构建和优化医学教育工具、临床决策支持系统以及医学考试准备软件。例如,医学教育平台可以利用该数据集提供的详细解答,帮助学生更好地理解复杂的医学概念;临床决策支持系统则可以通过分析思维链答案,为医生提供更为精准和全面的诊断建议。
数据集最近研究
最新研究方向
在医学领域,medmcqa-cot数据集的最新研究方向主要集中在利用Mixtral-8x7B模型生成高质量的Chain of Thought(CoT)答案,以提升医学问答系统的准确性和解释性。通过定制化的提示和少样本示例,该数据集旨在增强多选题答案的生成过程,使模型能够重新表述和解释问题,并对每个选项进行详细分析,最终得出总结性的解决方案。这一研究不仅有助于提高医学问答系统的性能,还为医学教育提供了新的工具,推动了人工智能在医疗领域的应用和发展。
以上内容由AI搜集并总结生成


