HuggingFaceM4/MMBench_dev
收藏Hugging Face2023-08-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/HuggingFaceM4/MMBench_dev
下载链接
链接失效反馈官方服务:
资源简介:
MMBench_dev数据集是一个用于评估视觉语言模型性能的基准数据集。近年来,视觉语言模型(如MiniGPT-4和LLaVA)的发展迅速,但如何有效评估这些模型的性能成为了一个主要挑战。传统基准如VQAv2和COCO Caption在评估模型时存在一些不足,例如无法全面捕捉模型的细粒度能力,且评估指标缺乏鲁棒性。为了解决这些问题,MMBench_dev数据集定义了一组细粒度的能力,并收集了相关问题,采用创新的评估策略来更可靠地评估模型预测。数据集包含约3000个问题,涵盖20个能力维度,每个问题都是单选格式,问题和选项均为英文。数据集分为dev和test两个部分,比例为4:6。
MMBench_dev数据集是一个用于评估视觉语言模型性能的基准数据集。近年来,视觉语言模型(如MiniGPT-4和LLaVA)的发展迅速,但如何有效评估这些模型的性能成为了一个主要挑战。传统基准如VQAv2和COCO Caption在评估模型时存在一些不足,例如无法全面捕捉模型的细粒度能力,且评估指标缺乏鲁棒性。为了解决这些问题,MMBench_dev数据集定义了一组细粒度的能力,并收集了相关问题,采用创新的评估策略来更可靠地评估模型预测。数据集包含约3000个问题,涵盖20个能力维度,每个问题都是单选格式,问题和选项均为英文。数据集分为dev和test两个部分,比例为4:6。
提供机构:
HuggingFaceM4
原始信息汇总
数据集概述
数据集名称
MMBench_dev
数据集特征
- 问题类型:单选题,选项数量2至4个。
- 语言:英语。
数据集结构
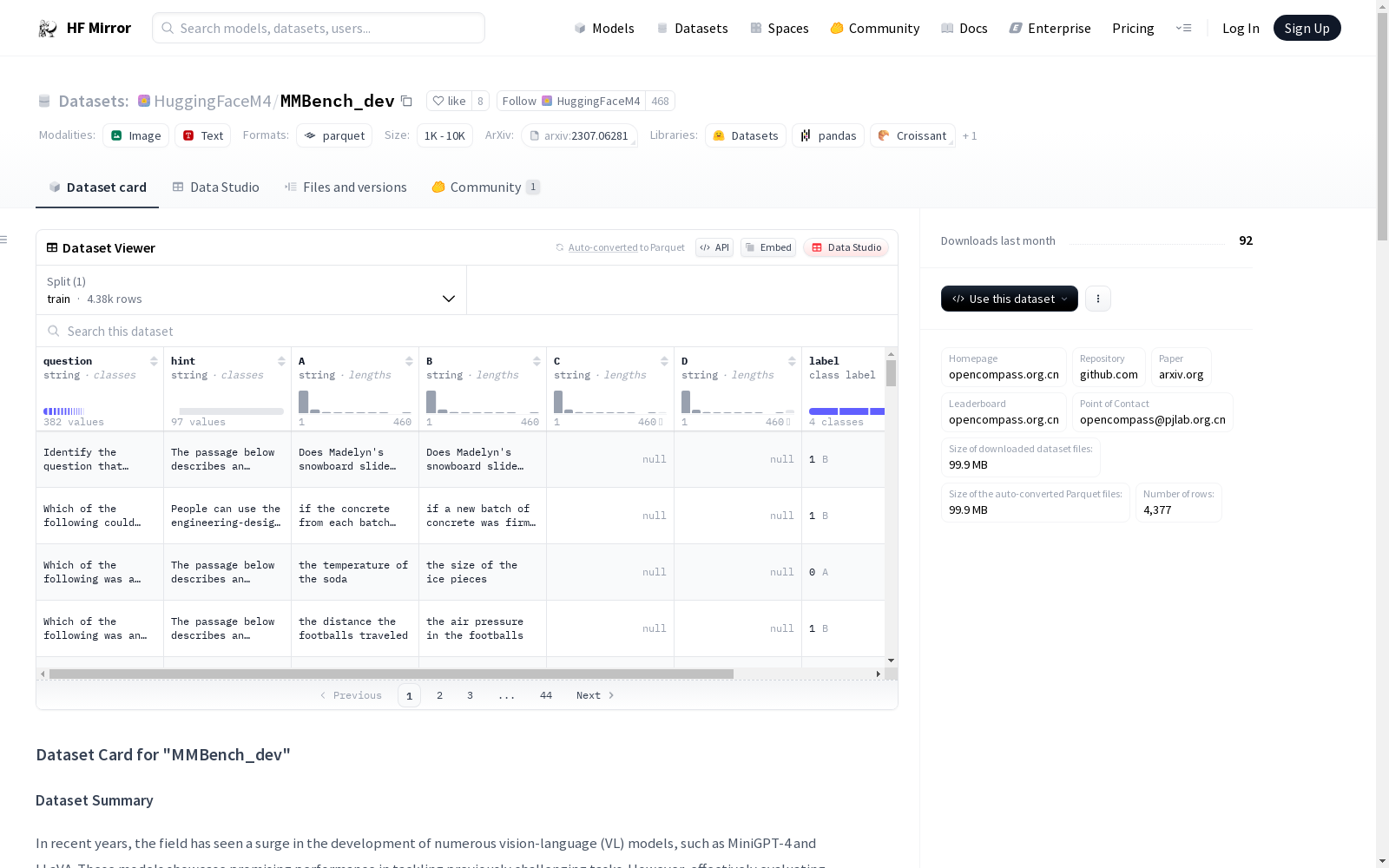
- 数据实例:每个实例包含以下字段:
index: 实例索引。question: 问题描述。hint(可选): 提示信息。A: 第一个选项。B: 第二个选项。C(可选): 第三个选项。D(可选): 第四个选项。image: 相关图像。category: 叶子类别。l2-category: L-2类别。split: 数据分割类型。source: 数据来源。
数据分割
- 总实例数:2974。
- 分割比例:dev和test按照4:6的比例分割。
评估方法
- 评估工具:使用ChatGPT匹配模型预测与问题选项,输出最终预测标签(A, B, C, D)。
数据集大小
- 训练集:
- 实例数:4377
- 数据大小:102942038.498字节
- 下载大小:99866501字节
标签定义
- 标签:
- 0: A
- 1: B
- 2: C
- 3: D
搜集汇总
数据集介绍
构建方式
MMBench_dev数据集的构建基于对视觉语言模型能力的精细划分,旨在收集与每种能力相关的特定问题。该数据集的问题形式为单选题,涵盖20个能力维度,共计约3000个问题。每个问题均含有一个正确答案,并配以相应的提示信息与图像。数据集分为训练集和开发集,通过运用ChatGPT对模型预测结果进行匹配,输出最终预测标签,确保了评估的可靠性。
使用方法
使用MMBench_dev数据集时,用户可以根据数据集中的字段,如问题、提示、选项、图像和标签等,进行多模态模型的训练和评估。数据集提供的开发集和测试集分割,使得研究人员可以在模型开发阶段进行有效的性能评估,并通过 leaderboard 进行结果对比,以促进模型优化和改进。
背景与挑战
背景概述
随着视觉语言(VL)模型的快速发展,例如MiniGPT-4和LLaVA等,这些模型在处理先前具有挑战性的任务中表现出令人瞩目的性能。然而,如何有效评估这些模型的性能,成为阻碍大型VL模型进一步发展的重要挑战。传统的基准测试如VQAv2和COCO Caption虽然被广泛用于为VL模型提供定量评估,但存在诸多不足。为此,MMBench数据集应运而生,旨在定义一组细粒度的能力,并收集与每种能力相关的相关问题,同时引入创新的评估策略,以确保对模型预测的更稳健评估。MMBench数据集由刘媛、段浩东、张媛汉等研究人员于2023年提出,并由开放 compass 组织构建。
当前挑战
MMBench数据集在构建过程中遇到的挑战主要包括:一是如何全面而准确地定义和收集细粒度的能力和相关问题;二是如何设计出既可靠又易于扩展的评估策略。此外,数据集在解决领域问题,如图像描述和视觉问答任务时,面临的挑战包括传统任务无法完全捕捉模型的细粒度能力,以及现有评估指标缺乏稳健性,无法准确匹配模型的输出和问题的答案。
常用场景
经典使用场景
在当前计算机视觉与自然语言处理领域,多模态模型评价的准确性成为研究的关键。MMBench_dev数据集为此提供了精准的评估框架,其经典使用场景在于对多模态模型进行细粒度能力的测试,通过设定涵盖二十个能力维度的约三千个问题,以单选题形式对模型进行考核,从而全面评估模型在图像与文本联合理解方面的表现。
解决学术问题
MMBench_dev数据集解决了传统多模态评价标准中存在的不足,如评价任务单一、指标不稳健、主观评价难度大等问题。该数据集通过定义细粒度能力,并收集相关的问题,为学术研究提供了更为客观和全面的评价方式,有助于推动多模态模型研究的深入发展。
实际应用
在实际应用中,MMBench_dev数据集可用于评估多模态模型在真实世界任务中的表现,如智能问答系统、内容推荐系统等,它为这些系统的性能提升提供了可靠的评估工具,有助于提高系统对图像和文本信息的理解能力。
数据集最近研究
最新研究方向
MMBench_dev数据集近期研究集中于多模态模型在细粒度能力评估方面的应用。该数据集针对传统视觉问答和图像描述数据集的不足,提出了基于精细能力划分的问题集合,旨在更全面、准确地评估模型在图像与文本结合任务中的表现。研究聚焦于如何通过多模态交互提升模型在逻辑推理、属性推理等维度的性能,以及如何运用创新评估策略,如利用ChatGPT匹配模型预测与问题选项,以提高评估的可靠性和公正性。这些研究不仅推动了多模态模型评估技术的发展,也为模型优化提供了新的方向和思路。
以上内容由遇见数据集搜集并总结生成


