IberBench
收藏arXiv2025-04-24 更新2025-04-25 收录
下载链接:
https://huggingface.co/spaces/iberbench/leaderboard
下载链接
链接失效反馈官方服务:
资源简介:
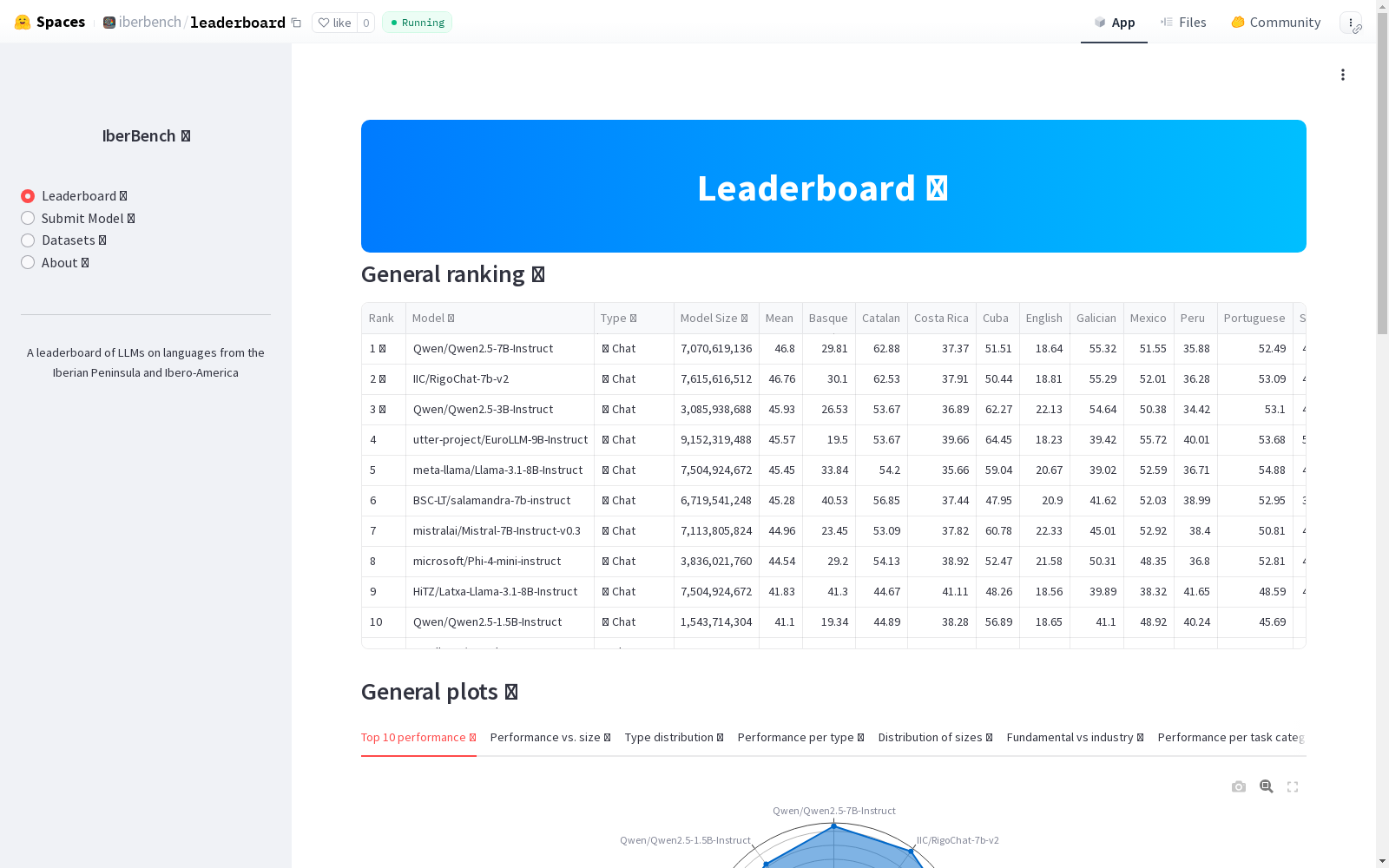
IberBench是一个全面且可扩展的基准测试,旨在评估大型语言模型在伊比利亚半岛和伊比美洲语言的基本和行业相关自然语言处理任务上的性能。该数据集由101个数据集组成,涵盖22个任务类别,如情感和情绪分析、毒性检测和摘要等。IberBench解决了现有评估实践中的关键局限性,如缺乏语言多样性和静态评估设置,通过允许持续更新和社区驱动的模型和数据集提交,由专家委员会进行审核。
IberBench is a comprehensive and scalable benchmark designed to evaluate the performance of Large Language Models (LLMs) on both fundamental and industry-relevant natural language processing tasks for languages of the Iberian Peninsula and Ibero-American regions. This benchmark comprises 101 datasets spanning 22 task categories, including sentiment and emotion analysis, toxicity detection, summarization, and more. IberBench addresses critical limitations of existing evaluation practices, such as insufficient linguistic diversity and static evaluation setups, by allowing continuous updates and community-driven submissions of models and datasets, which are reviewed by an expert committee.
提供机构:
Symanto Research, Keepler Data Tech, Universitat Politècnica de València, United Nations International Computing Centre (UNICC)
创建时间:
2025-04-24
搜集汇总
数据集介绍
构建方式
IberBench是一个专为评估大型语言模型(LLM)在伊比利亚语言上的表现而设计的综合性基准测试。该数据集整合了101个来自评估活动和近期基准测试的数据集,涵盖了22个任务类别,包括情感分析、毒性检测和文本摘要等。数据集的构建主要依赖于两个来源:一是来自IberLEF、IberEval、TASS和PAN等研讨会的共享任务数据集,二是专门为评估LLM在基础语言任务上的表现而设计的近期通用基准测试。所有数据集经过标准化处理,确保格式统一,并通过私有HuggingFace存储库进行托管,以防止数据泄露和污染。
使用方法
IberBench的使用方法包括通过其公开的HuggingFace空间访问排行榜界面,用户可以查看模型排名、图表和详细报告,并提交新模型进行评估。评估过程采用零样本设置,确保评估的一致性和现实性。对于序列标注任务,采用少量样本提示以指导模型正确格式化输出。评估框架基于lm-evaluation-harness,并进行了定制化扩展以支持序列标注任务和增量评估。用户还可以通过讨论区提议新增数据集,经委员会审核后,新数据集将被纳入基准测试。所有评估结果均通过私有服务器进行计算,确保评估的可靠性和安全性。
背景与挑战
背景概述
IberBench是由José Ángel González等研究人员于2025年推出的多语言大语言模型评估基准,专注于伊比利亚半岛及拉丁美洲地区语言,包括西班牙语、葡萄牙语、加泰罗尼亚语、巴斯克语、加利西亚语等语言及其方言变体。该数据集由Symanto Research、Keepler Data Tech等机构联合开发,旨在解决当前大语言模型评估中存在的英语中心主义问题,填补非英语语言评估的空白。IberBench整合了来自IberLEF、IberEval等22个任务类别的101个数据集,涵盖情感分析、毒性检测等工业相关任务以及阅读理解等基础能力测试,其动态更新机制和专家委员会审核制度为相关领域的模型评估设立了新标准。
当前挑战
IberBench面临的核心挑战体现在两个方面:领域问题方面,需解决工业相关任务(如意图分类、机器生成文本检测)性能显著低于基础语言任务的现象,以及巴斯克语等低资源语言的模型表现滞后问题;构建过程方面,需处理语言变体标注不一致(如墨西哥与乌拉圭西班牙语)、序列标注任务适配(仅1%数据集支持)、以及从分散的研讨会资源中整合58个历史数据集时面临的标准化难题。此外,持续维护社区驱动的动态评估框架与静态学术评估需求间的平衡,也是该基准长期发展的关键挑战。
常用场景
经典使用场景
IberBench数据集在自然语言处理(NLP)领域中被广泛用于评估大型语言模型(LLMs)在伊比利亚语言(如西班牙语、葡萄牙语、加泰罗尼亚语、巴斯克语和加利西亚语)上的性能。其经典使用场景包括情感分析、毒性检测、文本摘要和命名实体识别(NER)等任务。通过整合101个数据集,IberBench为研究人员提供了一个全面的评估框架,特别适用于多语言和多任务环境下的模型性能测试。
解决学术问题
IberBench解决了当前LLM评估中存在的几个关键学术问题。首先,它填补了现有基准测试在非英语语言(尤其是伊比利亚语言)上的空白。其次,它通过整合基础NLP任务和工业相关任务,提供了更全面的模型评估。此外,IberBench的动态特性允许持续更新和扩展,避免了静态基准测试的局限性。该数据集还解决了语言多样性不足的问题,涵盖了多种语言变体,如墨西哥西班牙语和乌拉圭西班牙语。
实际应用
在实际应用中,IberBench为企业和研究机构提供了一个可靠的评估工具,用于测试LLMs在真实场景中的表现。例如,在客户服务中,企业可以利用该数据集评估模型在多语言情感分析上的准确性。在内容审核领域,毒性检测任务的结果可以帮助优化自动审核系统。此外,IberBench的公开排行榜和开源实现使得模型比较和选择更加透明和高效。
数据集最近研究
最新研究方向
近年来,IberBench数据集在自然语言处理(NLP)领域引起了广泛关注,特别是在大语言模型(LLMs)评估方面。该数据集专注于伊比利亚半岛和伊比利亚-美洲地区的语言多样性,包括西班牙语、葡萄牙语、加泰罗尼亚语、巴斯克语、加利西亚语和英语,以及墨西哥、乌拉圭、秘鲁、哥斯达黎加和古巴等地区的西班牙语变体。IberBench的独特之处在于其综合性和可扩展性,涵盖了101个数据集,涉及22个任务类别,如情感和情绪分析、毒性检测和文本摘要等。
IberBench的前沿研究方向主要集中在以下几个方面:首先,该数据集通过整合来自评估活动和近期基准测试的数据集,解决了当前评估实践中语言多样性不足和静态评估设置的关键限制。其次,IberBench支持持续更新和社区驱动的模型及数据集提交,由专家委员会进行审核,确保了其长期相关性和实用性。此外,该数据集还特别关注工业相关任务,如意图分类和毒性检测,这些任务在现有基准测试中往往被忽视。
IberBench的影响和意义在于它为多语言和多任务环境下的LLM评估提供了一个标准化和透明的平台。通过公开源代码和评估流程,IberBench不仅促进了可重复研究,还推动了伊比利亚语言技术的负责任发展。未来,随着更多针对伊比利亚语言的数据集和评估活动的出现,IberBench有望进一步扩展其在NLP社区中的应用和影响力。
相关研究论文
- 1IberBench: LLM Evaluation on Iberian LanguagesSymanto Research, Keepler Data Tech, Universitat Politècnica de València, United Nations International Computing Centre (UNICC) · 2025年
以上内容由遇见数据集搜集并总结生成


