e_gov_chunked
收藏Hugging Face2025-01-14 更新2025-01-16 收录
下载链接:
https://huggingface.co/datasets/nlp-waseda/e_gov_chunked
下载链接
链接失效反馈官方服务:
资源简介:
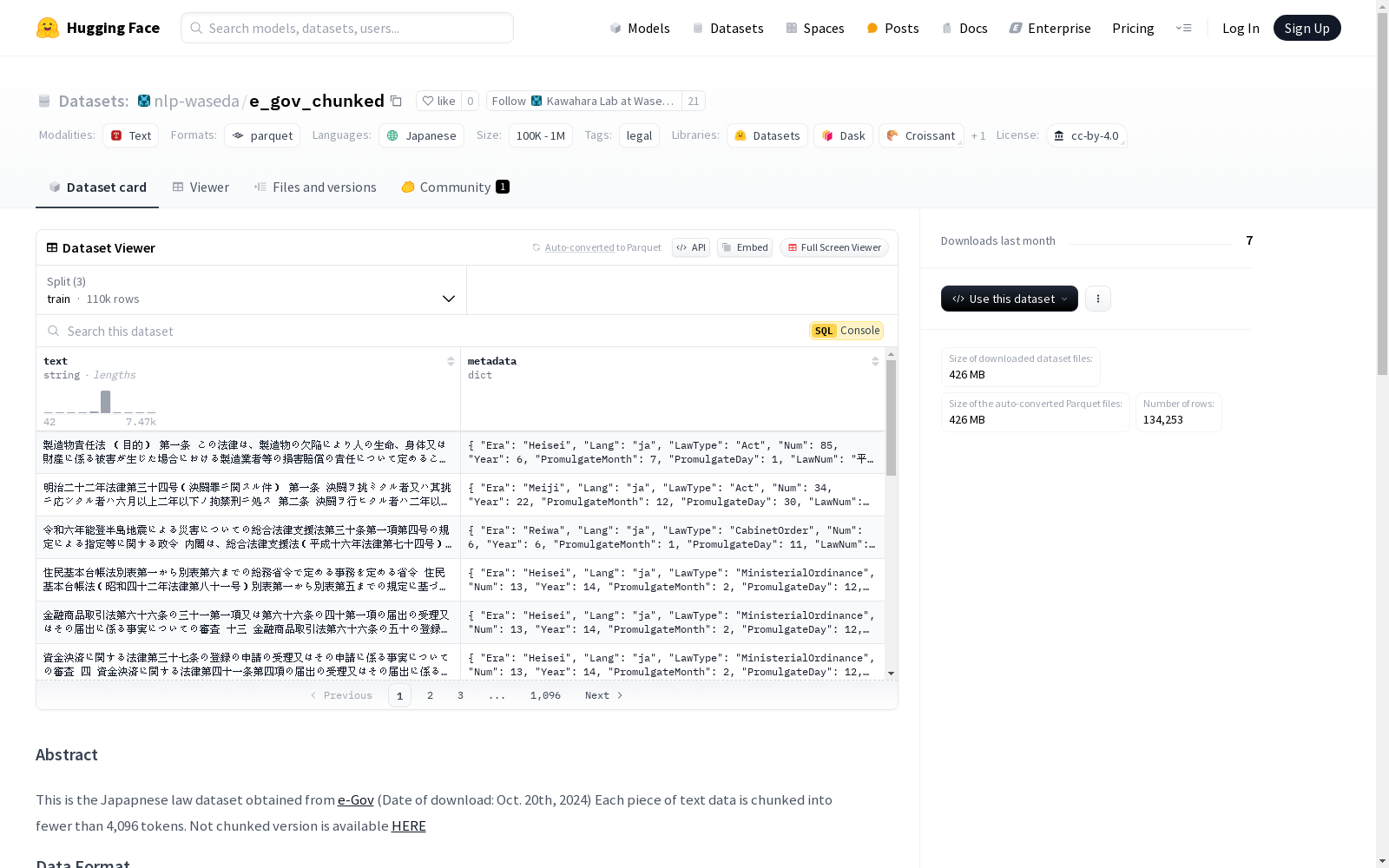
该数据集是一个日本法律数据集,数据来源于e-Gov网站(下载日期:2024年10月20日)。每条文本数据被分块处理,每块不超过4096个token。数据集包含两个主要字段:'text'和'metadata'。'text'字段包含法律文本,主要用于分析;'metadata'字段包含10个子字段,如'Era'(法律颁布的日本年号)、'Lang'(文本语言,均为日语)、'LawType'(法律类型,如宪法、法案等)、'Year'(颁布年份)、'PromulgateMonth/Day'(颁布月份/日期)、'LawNum'(法律编号)、'category_id'(类别ID)和'id_split'(分块编号)。数据集分为训练集、验证集和测试集,比例为8:1:1,且保留了类别的原始分布。数据分块使用了llm-jp/llm-jp-3-1.8b分词器,分块算法确保每块不超过4096个token。
This dataset is a Japanese legal corpus sourced from the e-Gov website (download date: October 20, 2024). Each text entry is chunked, with each chunk containing no more than 4096 tokens. The dataset includes two primary fields: 'text' and 'metadata'. The 'text' field holds legal texts primarily intended for analytical purposes; the 'metadata' field consists of 10 sub-fields, including 'Era' (Japanese era name at the time of the law's enactment), 'Lang' (text language, exclusively Japanese), 'LawType' (legal category such as constitution, bill, etc.), 'Year' (promulgation year), 'PromulgateMonth/Day' (promulgation month and day), 'LawNum' (legal number), 'category_id' (category ID), and 'id_split' (chunk serial number). The dataset is partitioned into training, validation, and test sets at a ratio of 8:1:1, while retaining the original class distribution. The text chunking procedure utilizes the llm-jp/llm-jp-3-1.8b tokenizer, and the chunking algorithm guarantees that each chunk does not exceed 4096 tokens.
提供机构:
Kawahara Lab at Waseda University
创建时间:
2025-01-14
搜集汇总
数据集介绍
构建方式
e_gov_chunked数据集是从日本政府电子政务门户网站e-Gov获取的法律文本数据,经过分块处理后构建而成。数据获取日期为2024年10月20日,每条文本数据被分块为不超过4096个token的片段。分块算法基于llm-jp/llm-jp-3-1.8b分词器,若文件长度小于4096个token,则视为单个块;若超过,则在4096个token内最后一个换行符处进行分割,并递归处理剩余部分。
使用方法
e_gov_chunked数据集适用于法律文本分析、自然语言处理任务以及法律信息检索等领域。用户可通过HuggingFace平台加载数据集,并利用其分块特性进行模型训练与评估。数据集的metadata字段提供了丰富的上下文信息,可用于增强模型的语义理解能力。此外,未分块版本的数据集也可通过指定链接获取,以满足不同研究需求。
背景与挑战
背景概述
e_gov_chunked数据集是一个专注于日本法律文本的语料库,源自日本政府官方门户网站e-Gov,数据下载于2024年10月20日。该数据集由Waseda大学的研究团队构建,旨在为自然语言处理领域提供高质量的日本法律文本资源。数据集的核心研究问题在于如何高效处理和分析大规模法律文本,特别是针对日语法律文本的分块与分类。通过提供详细的元数据信息,如法律颁布年代、法律类型、颁布日期等,该数据集为法律文本分析、法律信息检索以及法律文本生成等任务提供了重要支持。其影响力不仅限于法律领域,还为跨语言、跨文化的文本处理研究提供了宝贵的数据基础。
当前挑战
e_gov_chunked数据集在构建和应用过程中面临多重挑战。首先,法律文本的复杂性和专业性使得其分块与分类任务极具挑战性,尤其是日语法律文本中特有的语法结构和术语体系。其次,数据集的构建过程中需要处理大规模文本的分块问题,确保每个分块不超过4096个token,同时保持文本的语义完整性。此外,法律文本的多样性和历史跨度(如不同年代的法律文本)也对数据的一致性提出了更高要求。最后,如何在分块过程中保留元数据的完整性,并确保数据分布的均衡性,也是构建过程中需要解决的关键问题。这些挑战不仅影响了数据集的构建效率,也对后续的法律文本分析任务提出了更高的技术要求。
常用场景
经典使用场景
e_gov_chunked数据集在自然语言处理领域中被广泛应用于法律文本的分析与理解。由于其文本数据经过分块处理,每块不超过4096个token,这使得该数据集特别适合用于训练和评估长文本处理模型,如法律文本分类、信息提取和语义分析等任务。研究人员可以利用该数据集来探索法律文本的结构化信息,如法律类型、颁布日期等,从而深入理解法律文本的语义和上下文关系。
解决学术问题
e_gov_chunked数据集解决了法律文本处理中的多个关键学术问题。首先,它提供了丰富的法律文本数据,涵盖了多种法律类型,如宪法、法案、内阁命令等,为法律文本的分类和语义分析提供了坚实的基础。其次,通过分块处理,该数据集有效解决了长文本处理中的计算资源限制问题,使得研究人员能够在有限的硬件条件下进行大规模的法律文本分析。此外,数据集的元数据信息为法律文本的时间序列分析和历史演变研究提供了重要支持。
实际应用
在实际应用中,e_gov_chunked数据集被广泛用于法律信息系统的开发与优化。例如,法律搜索引擎可以利用该数据集进行法律文本的语义匹配和检索,提高搜索结果的准确性和相关性。此外,法律咨询平台可以通过分析该数据集中的法律文本,自动生成法律建议或解答用户的法律问题。政府部门也可以利用该数据集进行法律文本的自动化归档和分类,提高法律文件的管理效率。
数据集最近研究
最新研究方向
近年来,随着自然语言处理技术的迅猛发展,e_gov_chunked数据集在法律文本分析领域引起了广泛关注。该数据集包含了日本法律文本的分块数据,涵盖了宪法、法案、内阁令等多种法律类型,为研究者提供了丰富的法律语言资源。当前的研究方向主要集中在利用深度学习模型进行法律文本的自动分类、信息抽取和语义理解。特别是在法律文本的跨语言翻译和智能法律咨询系统中,该数据集的应用潜力巨大。此外,结合大语言模型(LLM)的预训练和微调技术,研究者们正在探索如何更高效地处理长文本分块,以提升模型在法律文本处理中的表现。这些研究不仅推动了法律智能化的发展,也为法律文本的自动化处理提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


