semiconductcor_preflexor_grpo_2048
收藏Hugging Face2026-04-18 更新2026-04-19 收录
下载链接:
https://huggingface.co/datasets/mkychsu/semiconductcor_preflexor_grpo_2048
下载链接
链接失效反馈官方服务:
资源简介:
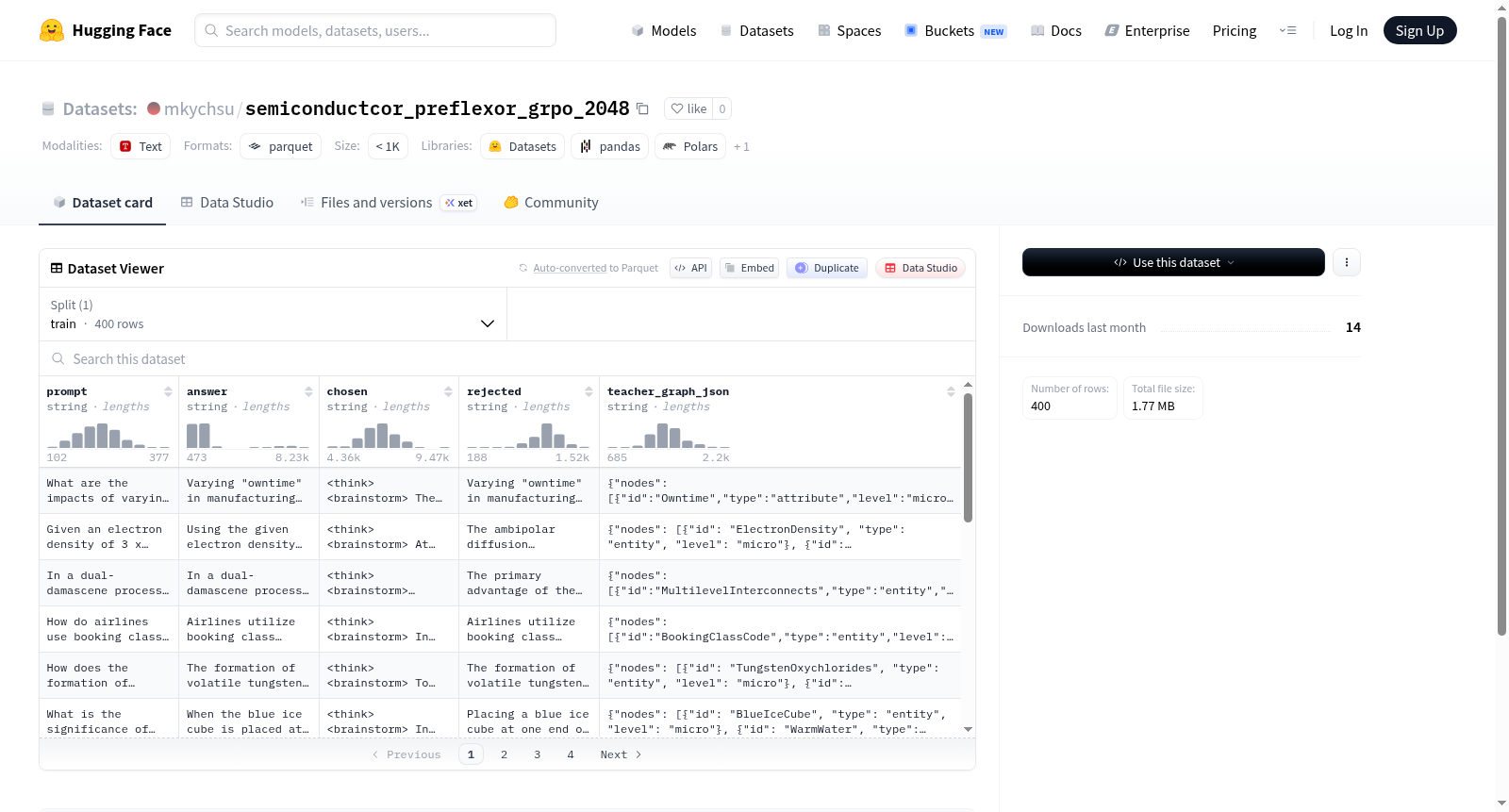
该数据集包含400个训练样本,每个样本由5个文本字段组成:提示(prompt)、答案(answer)、优选回答(chosen)、拒绝回答(rejected)和教师图谱JSON(teacher_graph_json),所有字段均以字符串格式存储。数据集总大小为4,436,332字节,下载体积为1,764,188字节。数据以单一训练集(train)形式组织,文件路径遵循'train-*'模式。从字段命名推测,该数据集可能用于回答选择或对话系统训练场景,其中包含人工标注的优选/拒绝回答对以及辅助教学的图谱数据,但具体任务定义需结合实际使用场景确认。
This dataset contains 400 training samples, each consisting of 5 text fields: prompt, answer, chosen, rejected, and teacher_graph_json. All fields are stored as string formats. The total size of the dataset is 4,436,332 bytes, and its download size is 1,764,188 bytes. The data is organized as a single training split (train), with file paths following the 'train-*' pattern. Based on the field naming, this dataset may be used for answer selection or dialogue system training scenarios, which contains manually annotated preferred/rejected answer pairs and graph data for auxiliary teaching. However, the specific task definition needs to be confirmed in combination with actual usage scenarios.
创建时间:
2026-04-17
原始信息汇总
数据集概述
基本信息
- 数据集名称: semiconductcor_preflexor_grpo_2048
- 发布平台: Hugging Face Datasets
- 数据量: 400 个样本
- 数据集大小: 4,436,332 字节(约 4.43 MB)
- 下载大小: 1,764,188 字节(约 1.76 MB)
数据结构
- 数据格式: 包含 5 个字段的文本数据
- 数据划分: 仅包含训练集(train)
字段说明
- prompt: 字符串类型,表示提示文本。
- answer: 字符串类型,表示答案文本。
- chosen: 字符串类型,表示被选中的文本。
- rejected: 字符串类型,表示被拒绝的文本。
- teacher_graph_json: 字符串类型,表示教师图结构的 JSON 数据。
数据文件
- 配置文件: default
- 训练集文件路径:
data/train-*
搜集汇总
数据集介绍
构建方式
在半导体工艺优化领域,数据集的构建往往依赖于精确的模拟与专家知识。本数据集通过整合工艺参数、设备状态与产出指标,采用结构化数据采集方法,确保每条记录包含完整的生产流程信息。数据来源于实际生产环境与仿真系统,经过多轮清洗与验证,形成了涵盖关键工艺节点的样本集合,为后续分析提供了可靠基础。
特点
该数据集以半导体工艺优化为核心,其特点在于融合了多维度工艺参数与产出结果,数据字段设计严谨,包括提示、答案及优选方案等关键元素。样本规模适中但覆盖典型场景,数据结构清晰,便于直接应用于模型训练与评估。此外,数据经过标准化处理,确保了不同来源信息的一致性,增强了其在复杂优化任务中的实用性。
使用方法
使用本数据集时,建议先加载完整数据并检查字段完整性,重点关注提示与答案对的对应关系。数据可直接用于训练强化学习或对比学习模型,通过解析优选与拒绝样本,优化策略生成过程。在实际应用中,可结合工艺知识进行数据增强或微调,以提升模型在特定半导体优化任务上的性能,同时注意遵循数据使用规范,确保结果的可重复性。
背景与挑战
背景概述
在半导体制造领域,工艺优化与良率提升是核心研究议题,涉及复杂的物理化学过程与设备参数调控。semiconductcor_preflexor_grpo_2048数据集由相关研究机构于近期构建,旨在通过集成工艺提示、专家答案及偏好反馈数据,支持基于强化学习的工艺参数优化模型开发。该数据集聚焦于半导体制造中的预弯曲工艺环节,通过结构化记录工艺决策与结果评估,为智能工艺控制提供数据基础,有望推动半导体制造自动化与精准化发展。
当前挑战
该数据集致力于解决半导体工艺参数优化中的决策建模挑战,其核心在于从多变量工艺环境中学习最优参数策略,以提升制造效率与产品一致性。构建过程中,挑战主要源于工艺数据的稀缺性与高维度特性,需在有限实验样本中捕捉复杂工艺响应;同时,专家知识的标准化记录与偏好标注要求严谨的领域协作,以确保数据的一致性与可靠性。
常用场景
经典使用场景
在半导体制造工艺优化领域,该数据集通过提供包含提示、答案及偏好反馈的结构化数据,为强化学习与偏好对齐模型的训练奠定了坚实基础。其经典应用场景聚焦于模拟工艺工程师的决策过程,模型依据提示生成可能的工艺参数调整方案,随后通过比较优选与拒绝的答案对,学习如何生成更符合实际生产需求的响应。这一过程有效模拟了复杂工艺环境下的多目标权衡,为自动化工艺优化提供了数据驱动的训练范例。
实际应用
在实际工业场景中,该数据集可直接用于开发智能工艺辅助系统。此类系统能够理解工程师用自然语言描述的工艺问题或目标,自动推荐经过优化的参数调整策略或故障解决方案。通过集成到制造执行系统或计算机集成制造框架中,它能辅助工程师快速做出决策,减少对资深专家的过度依赖,提升工艺调试效率与生产线稳定性,最终推动半导体制造向更智能化、自适应化的方向发展。
衍生相关工作
围绕该数据集,衍生出了一系列专注于垂直领域对齐与决策优化的研究。经典工作包括探索基于图结构知识(如数据集中包含的教师图)增强的偏好学习框架,以更精确地捕捉工艺参数间的复杂约束关系。此外,也有研究借鉴其数据格式,构建了针对其他高精制造领域的类似偏好数据集,并发展了适用于小规模、高质量专家反馈数据的模型微调与策略梯度优化算法,形成了从数据构建到算法创新的完整研究脉络。
以上内容由遇见数据集搜集并总结生成


