pomak-speech-corpus
收藏Hugging Face2026-01-22 更新2026-01-23 收录
下载链接:
https://huggingface.co/datasets/ilsp/pomak-speech-corpus
下载链接
链接失效反馈官方服务:
资源简介:
Pomak是一种濒危的东南斯拉夫语言变体,主要分布在希腊北部。它属于南斯拉夫方言连续体,与保加利亚语关系密切,同时由于长期的语言接触,受到希腊语和土耳其语的显著影响。Pomak在语音和词汇上存在很大的社区间差异,且缺乏标准化的正字法。尽管具有语言学上的重要性,Pomak的文献记录非常有限,语言技术资源极为匮乏。
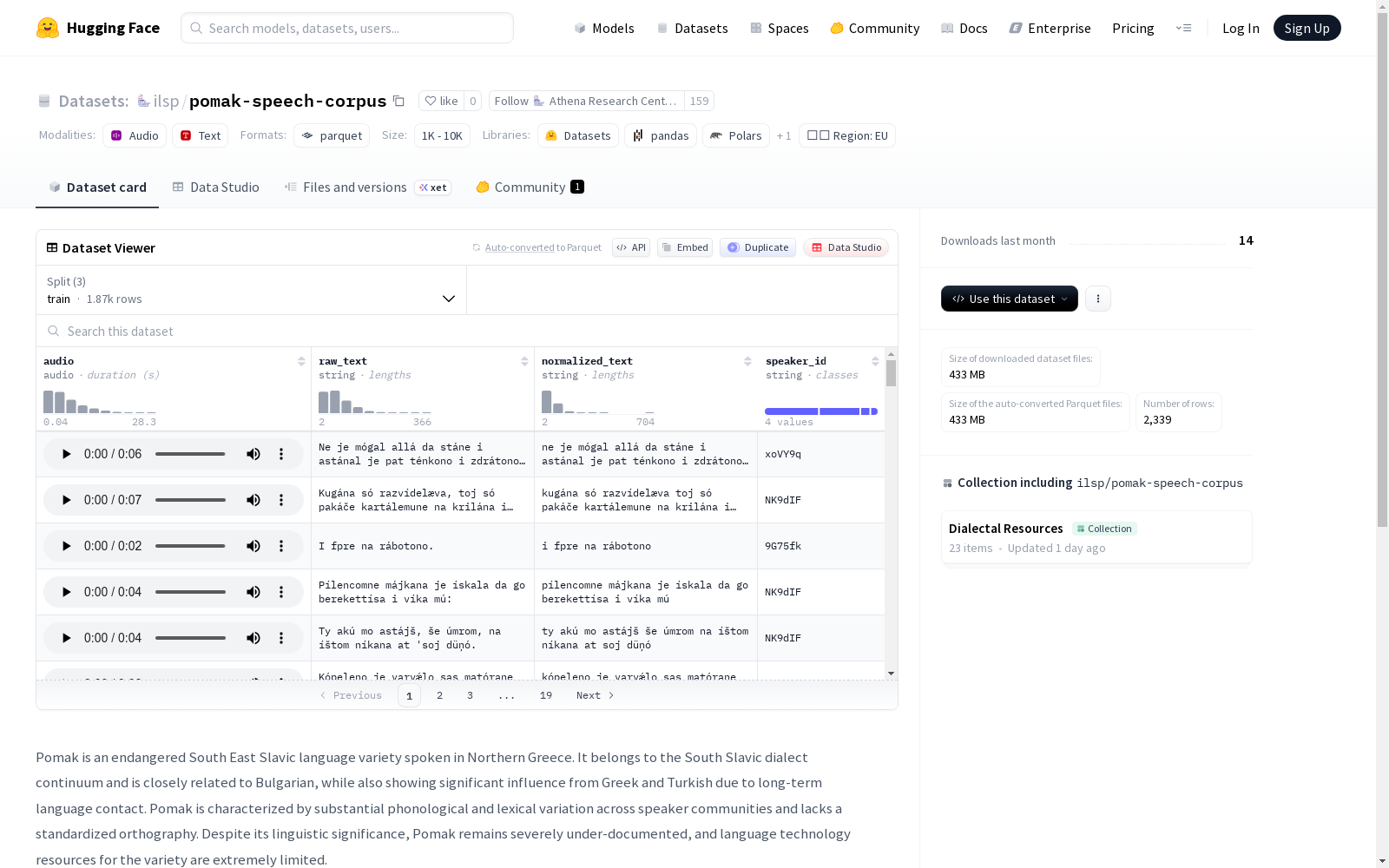
用于训练该模型的语音语料库是在希腊Xanthi的ILSP视听工作室的受控录音室环境中收集的。四位Pomak母语者(两男两女)朗读了Pomak文本,产生了约14小时的语音数据。所有录音均在参与者知情同意的情况下进行。为了用于ASR训练,长录音被分割成不超过25秒的短句,这一过程去除了大部分长停顿,最终生成了一个包含11小时8分钟分段语音的训练数据集。
该数据集用于微调一个预训练的斯拉夫wav2vec2模型(classla/wav2vec2-large-slavic-parlaspeech-hr),使用了Hugging Face Transformers库。最终的模型wav2vec2-xls-r-slavic-pomak是首个为Pomak开发的自动语音识别系统。在包含10%数据的保留测试集上的评估显示,与预训练基线相比,词错误率(WER)从31.47%降至3.12%,字符错误率(CER)从87.31%降至9.06%。
该模型及其训练流程在论文《ASR pipeline for low-resourced languages: A case study on Pomak》中进行了介绍。这项工作表明,即使在极低资源环境下,微调大型多语言和家族特定的ASR模型也能产生高质量的语音识别性能,旨在支持未来对Pomak的语言学研究、语料库创建和语言文档工作。
Pomak is an endangered Southeastern Slavic language variety primarily distributed in northern Greece. It belongs to the South Slavic dialect continuum, has a close relationship with Bulgarian, and has been significantly influenced by Greek and Turkish due to long-term language contact.
Pomak exhibits considerable inter-community differences in phonetics and vocabulary, and lacks a standardized orthography. Despite its linguistic importance, Pomak has extremely limited documentation and very scarce language technology resources.
The speech corpus used for training the model was collected in a controlled studio environment at the ILSP Audiovisual Studio in Xanthi, Greece. Four native Pomak speakers (two males and two females) read Pomak texts, generating approximately 14 hours of speech data. All recordings were conducted with informed consent from the participants. For ASR training, long recordings were split into short utterances no longer than 25 seconds, which removed most long pauses, ultimately resulting in a training dataset containing 11 hours and 8 minutes of segmented speech.
This dataset was used to fine-tune a pre-trained Slavic wav2vec2 model (classla/wav2vec2-large-slavic-parlaspeech-hr) using the Hugging Face Transformers library. The final model, wav2vec2-xls-r-slavic-pomak, is the first automatic speech recognition system developed for Pomak. Evaluations on a held-out test set containing 10% of the data showed that compared with the pre-trained baseline, the Word Error Rate (WER) decreased from 31.47% to 3.12%, and the Character Error Rate (CER) decreased from 87.31% to 9.06%.
This model and its training pipeline are introduced in the paper *ASR pipeline for low-resourced languages: A case study on Pomak*. This work demonstrates that even in extremely low-resource environments, fine-tuning large multilingual and family-specific ASR models can achieve high-quality speech recognition performance, aiming to support future linguistic research, corpus creation and language documentation work for Pomak.
创建时间:
2026-01-21
原始信息汇总
Pomak Speech Corpus 数据集概述
数据集基本信息
- 数据集名称: Pomak Speech Corpus
- 发布者/机构: ILSP
- 语言: Pomak(一种濒危的东南斯拉夫语言变体,使用于希腊北部)
- 数据收集地点: 希腊克桑西的ILSP视听工作室
- 数据收集环境: 受控的录音室环境
数据集内容与结构
数据特征
- audio: 音频数据,采样率为16000 Hz
- raw_text: 原始文本
- normalized_text: 规范化文本
- speaker_id: 说话人ID
数据划分与规模
- train (训练集):
- 样本数量: 1871
- 数据大小: 351404040.93300426 字节
- validation (验证集):
- 样本数量: 234
- 数据大小: 43780575.29499786 字节
- test (测试集):
- 样本数量: 234
- 数据大小: 41879386.29499786 字节
- 总下载大小: 432556009 字节
- 总数据集大小: 437064002.523 字节
数据来源与描述
- 说话人: 4名母语为Pomak的说话人(2名女性,2名男性)
- 录音内容: 朗读Pomak文本
- 原始录音时长: 约14小时
- 处理后的训练数据时长: 11小时8分钟(经分段处理,每段最长25秒,移除了大部分长停顿)
语言背景
- 语言分类: Pomak属于南斯拉夫方言连续体,与保加利亚语密切相关。
- 语言特点: 由于长期的语言接触,受到希腊语和土耳其语的显著影响。在不同说话人社区中存在显著的音系和词汇变异,且缺乏标准化的正字法。
- 现状: 严重缺乏记录,语言技术资源极其有限。
相关模型与应用
- 用途: 该数据集用于微调一个预训练的斯拉夫语wav2vec2模型(classla/wav2vec2-large-slavic-parlaspeech-hr)。
- 产出模型: wav2vec2-xls-r-slavic-pomak,这是为Pomak开发的第一个自动语音识别系统。
- 模型性能: 在包含10%数据的保留测试集上评估,词错误率从31.47%降至3.12%,字符错误率从87.31%降至9.06%。
学术参考
- 相关论文: “ASR pipeline for low-resourced languages: A case study on Pomak”
- 研究意义: 证明了即使在资源极度匮乏的情况下,微调大型多语言和语族特定的ASR模型也能产生高质量的语音识别性能,旨在支持未来对Pomak的语言学研究、语料库创建和语言记录工作。
搜集汇总
数据集介绍
构建方式
在濒危语言资源稀缺的背景下,Pomak语音语料库的构建采用了严谨的录音采集方法。数据收集在希腊克桑西的ILSP视听工作室这一受控环境中完成,四位母语者(两男两女)通过朗读Pomak文本贡献了约14小时的原始录音。为确保数据质量,长录音被进一步切分为不超过25秒的短语音段,移除了多数长停顿,最终形成了11小时8分钟的训练数据集,整个过程均获得了参与者的知情同意。
特点
该数据集作为首个针对Pomak语言的语音识别资源,具有显著的低资源与多样性特征。其音频采样率为16kHz,每条数据均包含原始文本、标准化文本及说话人ID,涵盖了训练、验证与测试三个标准划分。数据源自四个不同说话人,反映了Pomak语言因社区差异而产生的音系与词汇变异,同时缺乏标准正字法的语言特点也蕴含于文本标注之中,为研究语言接触与变异提供了珍贵样本。
使用方法
该数据集主要用于低资源语言的自动语音识别模型训练与评估。典型使用流程是加载Hugging Face平台上的数据集,直接访问‘audio’、‘normalized_text’等字段。研究者可基于预训练模型(如斯拉夫语系的wav2vec2)进行微调,利用其标准的数据划分进行模型训练与性能验证。该数据集支撑的管道已成功将词错误率从基线31.47%降至3.12%,展示了其在推动濒危语言技术化与文档化方面的应用潜力。
背景与挑战
背景概述
Pomak语作为东南斯拉夫语系的一种濒危语言变体,主要分布于希腊北部地区,隶属于南斯拉夫方言连续体,与保加利亚语关系密切,并因长期语言接触而深受希腊语和土耳其语影响。该语言在语音和词汇层面呈现显著的社区间变异,且缺乏标准化书写系统,导致其语言技术资源极度匮乏。为应对这一困境,希腊Xanthi的ILSP音视频工作室于近期构建了Pomak语音语料库,由四位母语者在受控环境下录制约14小时朗读语音,经分段处理后形成11小时8分钟的训练数据。该数据集旨在支持自动语音识别系统的开发,为濒危语言的文档化与计算语言学应用提供关键资源。
当前挑战
在构建Pomak语音语料库过程中,首要挑战源于语言本身的复杂性:作为濒危语言,Pomak缺乏统一的正字法规范,且存在显著的方言变异,这为语音文本对齐与标注带来极大困难。其次,数据采集面临资源限制,仅能依靠少量母语者参与,导致语料规模有限且可能无法全面覆盖语言变体。在技术层面,如何基于极低资源条件有效训练自动语音识别模型成为核心问题,需解决多语言预训练模型适应特定语言特征、以及数据稀疏导致的模型泛化能力不足等难题。这些挑战共同凸显了濒危语言计算文档化工作中资源获取与模型优化的双重困境。
常用场景
实际应用
在实际层面,Pomak语音语料库赋能于语言文档化与教育工具的开发,例如辅助创建数字化语言档案或构建交互式学习应用。其衍生的ASR系统可用于自动转写口语材料,支持语言学家进行语音变异分析和词汇收集,同时为社区驱动的语言复兴项目提供技术支撑,促进濒危语言在数字时代的可持续传承。
衍生相关工作
基于该数据集,经典研究《ASR pipeline for low-resourced languages: A case study on Pomak》系统阐述了低资源语言ASR流水线的构建方法。这项工作启发了后续对类似濒危语种的技术探索,推动了家族特异性预训练模型在语言技术中的应用,并为多语言语音处理领域提供了可复制的微调框架,促进了相关学术社群的协作发展。
以上内容由遇见数据集搜集并总结生成


