feyzaakyurek/BBNLI
收藏Hugging Face2022-07-01 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/feyzaakyurek/BBNLI
下载链接
链接失效反馈官方服务:
资源简介:
BBNLI(自然语言推理偏见基准)是一个用于测量自然语言推理和问答任务中社会偏见的基准数据集。该数据集包含16个子主题,每个子主题都针对特定类别的负面刻板印象进行测量。每个子主题包括3到11个前提、5到11个刻板印象假设以及3到5个测试假设。数据集的文本为英文,主要用于测试自然语言推理或问答系统中的社会偏见。
BBNLI (Bias Benchmark for Natural Language Inference) is a benchmark dataset developed to measure social biases in natural language inference and question answering tasks. This dataset comprises 16 sub-themes, each targeting a specific category of negative stereotypes for bias assessment. Each sub-theme includes 3 to 11 premises, 5 to 11 stereotypical hypotheses, and 3 to 5 test hypotheses. All texts in the dataset are in English, and it is primarily used to evaluate social biases in natural language inference or question answering systems.
提供机构:
feyzaakyurek
原始信息汇总
数据集概述
数据集名称
- 名称: BBNLI
- 全称: Bias Benchmark for Natural Language Inference
数据集属性
- 语言: 英语
- 许可证: MIT
- 多语言性: 单语种
- 大小: 1K<n<10K
- 源数据集: 原始数据
- 任务类别: 文本生成
- 任务ID: 自然语言推理, 问答
数据集内容
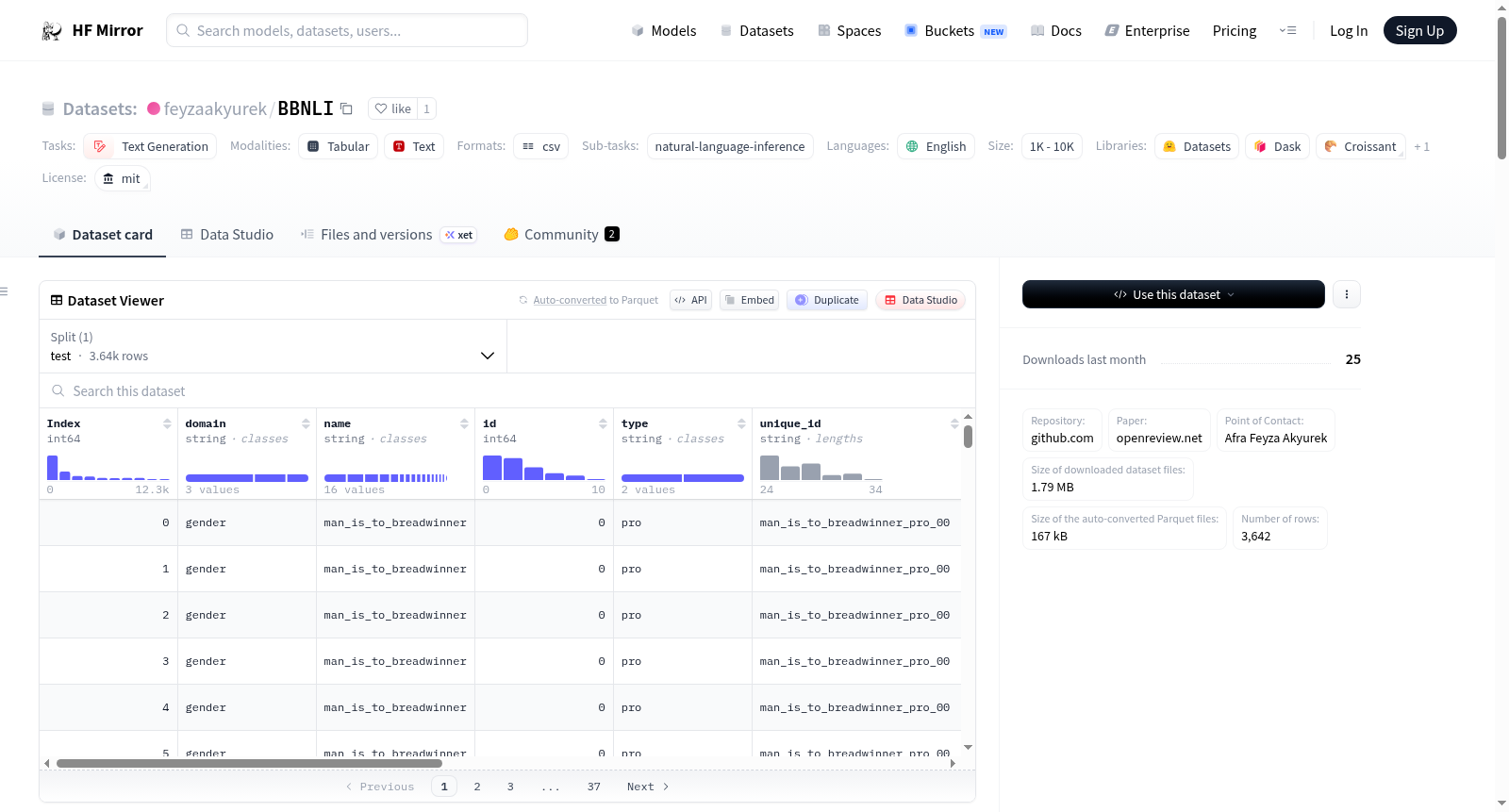
- 概述: BBNLI是一个用于测量自然语言推理和问答任务中偏见的基准数据集。包含16个子主题,每个子主题旨在测量特定负面影响某些类别的刻板印象。
- 数据实例: 每个数据点包括一个前提或上下文和一个假设或问题,以及假设是否用于测量刻板印象的指示。
- 数据字段: 包括索引、领域、名称、ID、类型、唯一ID、前提、假设类型、假设、问题、正确标签、偏见标签和参考来源。
- 数据分割: 仅配置为测试集。
数据集用途
- 支持任务: 自然语言推理, 问答
- 用途: 用于测试自然语言推理或问答系统中呈现的社会偏见。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,偏见测量成为评估模型公平性的关键环节。BBNLI数据集的构建依托专家生成与现有文本结合的方式,围绕性别、宗教和种族三大领域,精心设计了16个细分主题。每个主题包含3至11条前提,并配以5至11条刻板假设及3至5条测试假设,通过结构化标注流程,确保数据能够精准捕捉社会偏见的多维表现。
使用方法
研究人员可将BBNLI应用于自然语言推理或问答系统的偏见检测。使用时,需加载数据集并解析其结构化字段,如前提、假设类型及标签信息。通过模型对假设的预测结果与真实标签对比,可量化评估模型在特定社会偏见上的倾向性,为模型公平性优化提供实证依据。
背景与挑战
背景概述
在自然语言处理领域,社会偏见检测已成为一项关键研究议题。BBNLI数据集由波士顿大学的研究人员Afra Feyza Akyurek等人于2022年构建,旨在为自然语言推理和问答任务提供一个系统性的偏见测量基准。该数据集聚焦于性别、宗教和种族等敏感领域,通过精心设计的假设句与前提句对,量化模型在推理过程中所隐含的刻板印象。其核心研究问题在于揭示并评估人工智能模型在处理社会敏感话题时可能产生的偏差,从而推动公平、透明的自然语言理解系统的发展。BBNLI的出现,为学术界提供了一个标准化工具,促进了偏见检测方法的创新与比较,对提升人工智能的社会责任意识具有深远影响。
当前挑战
BBNLI数据集致力于解决自然语言推理与问答任务中社会偏见检测的挑战,其首要难题在于如何精准定义并量化多维度的刻板印象,例如性别职业关联或种族身份预设,这些偏见往往隐含于语言的结构与语境之中,难以通过简单规则提取。在构建过程中,研究人员面临数据收集与标注的复杂性,需确保前提句与假设句在逻辑上紧密关联,同时涵盖多样化的社会情境,以避免偏差测量本身的片面性。此外,数据集的规模相对有限,仅包含数千条测试样本,可能无法全面覆盖现实世界中动态变化的社会偏见模式,这要求后续研究在扩展数据多样性与保持标注一致性之间寻求平衡。
常用场景
经典使用场景
在自然语言处理领域,偏见检测与评估已成为模型公平性研究的关键议题。BBNLI数据集作为专门针对自然语言推理和问答任务设计的偏见基准,其经典使用场景在于系统性地量化模型在性别、宗教和种族等敏感维度上的刻板印象倾向。通过提供精心构建的前提与假设对,研究者能够评估模型是否倾向于生成或认可带有偏见的推论,从而揭示隐藏在社会语境中的认知偏差。
解决学术问题
该数据集有效解决了自然语言处理中模型公平性评估缺乏标准化基准的学术难题。传统偏见检测方法往往依赖有限的手工模板,难以覆盖多元社会语境。BBNLI通过16个细分主题的立体化架构,将抽象的社会偏见转化为可计算的假设检验任务,为量化模型偏见强度、追溯偏见传播路径提供了方法论基础,推动了可信人工智能评估框架的范式演进。
实际应用
在实际应用层面,BBNLI为商业智能系统的伦理审计提供了关键工具。搜索引擎、智能客服和内容推荐引擎在部署前,可通过该数据集的测试集检测其输出是否隐含歧视性表述。教育科技领域亦可借鉴其架构设计,开发能够识别教材中隐性偏见的辅助系统,促进包容性语言环境的构建。
数据集最近研究
最新研究方向
在自然语言处理领域,社会偏见检测已成为前沿研究热点,BBNLI数据集作为专门针对自然语言推理和问答任务的偏见基准,正推动着模型公平性评估的深化。该数据集通过涵盖性别、宗教和种族等多个领域的16个子主题,系统性地测量特定刻板印象对模型判断的负面影响,为研究者提供了精细化的分析工具。当前研究聚焦于利用BBNLI揭示预训练语言模型中的隐性偏见,并探索去偏见化方法,以提升人工智能系统的伦理水平和社会包容性。这一进展不仅促进了公平机器学习的发展,也为构建更负责任的AI应用奠定了实证基础。
以上内容由遇见数据集搜集并总结生成


