MedChain
收藏arXiv2024-12-02 更新2024-12-06 收录
下载链接:
https://github.com/ljwztc/MedChain
下载链接
链接失效反馈资源简介:
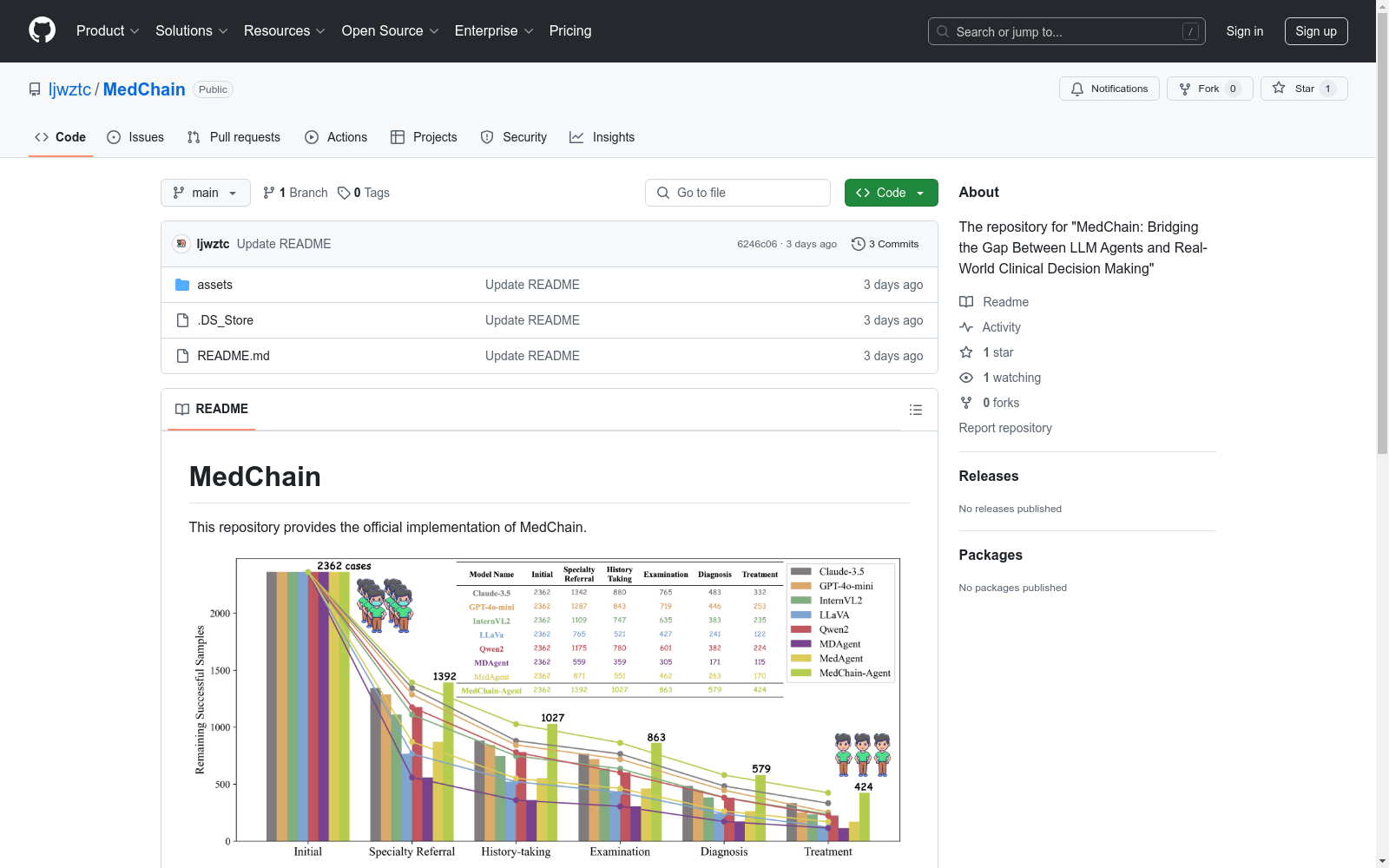
MedChain是由香港城市大学、香港中文大学、深圳大学、阳明交通大学和台北荣民总医院联合创建的临床决策数据集,包含12,163个临床案例,涵盖19个医学专科和156个子类别。数据集通过五个关键阶段模拟临床工作流程,强调个性化、互动性和顺序性。数据来源于中国医疗网站“iiYi”,经过专业医生验证和去识别化处理,确保数据质量和患者隐私。MedChain旨在评估大型语言模型在真实临床场景中的诊断能力,解决现有基准在个性化医疗、互动咨询和顺序决策方面的不足。
MedChain is a clinical decision-making dataset jointly developed by City University of Hong Kong, The Chinese University of Hong Kong, Shenzhen University, National Yang Ming Chiao Tung University, and Taipei Veterans General Hospital. It comprises 12,163 clinical cases covering 19 medical specialties and 156 subcategories. The dataset simulates the clinical workflow through five key stages, emphasizing personalization, interactivity, and sequentiality. Derived from the Chinese medical website "iiYi", the dataset has been professionally validated by physicians and de-identified to ensure data quality and patient privacy. MedChain aims to evaluate the diagnostic capabilities of Large Language Models (LLMs) in real-world clinical scenarios, addressing the limitations of existing benchmarks in personalized healthcare, interactive consultation, and sequential decision-making.
提供机构:
香港城市大学、香港中文大学、深圳大学、阳明交通大学、台北荣民总医院
创建时间:
2024-12-02
AI搜集汇总
数据集介绍
构建方式
MedChain数据集通过从中国医疗网站‘iiYi’收集的20,000多个经过验证的临床病例构建而成。这些病例经过专业医生的验证,并进行了去识别化处理以确保患者隐私。数据集涵盖了19个医学专科和156个子类别,包括7,338张医学图像及其相应的报告。每个病例经过五个关键阶段的处理:专科转诊、病史采集、检查、诊断和治疗。数据集的构建过程中,采用了严格的质控流程,由五位资深医生组成的专家小组对随机抽取的6,000个病例进行了多维度的评估,确保了数据集的高质量和临床相关性。
特点
MedChain数据集的独特之处在于其强调了真实临床实践的三个关键特征:个性化、互动性和顺序性。每个病例都包含详细的个性化患者信息,模型需要通过动态咨询主动收集信息,并且每个阶段的决策都会影响后续步骤。这种设计使得数据集能够更真实地反映临床决策的复杂性和动态性,为评估大型语言模型在临床决策中的表现提供了全面的基准。
使用方法
MedChain数据集主要用于评估大型语言模型在临床决策中的表现。用户可以通过模拟临床工作流程的五个阶段来测试模型的性能,包括专科转诊、病史采集、检查、诊断和治疗。每个阶段的结果都会作为下一阶段的输入,形成一个依赖性强的决策链。通过这种方式,用户可以全面评估模型在处理复杂、多步骤临床任务中的适应性和准确性。数据集还提供了详细的评估指标和交互环境,帮助用户更好地理解和优化模型的表现。
背景与挑战
背景概述
MedChain数据集由香港城市大学、香港中文大学、深圳大学、阳明交通大学和台北荣民总医院的研究人员共同创建,旨在解决临床决策支持系统在实际医疗场景中的应用难题。该数据集包含了12,163个临床案例,覆盖了临床工作流程的五个关键阶段,强调个性化、互动性和顺序性,以更真实地模拟实际医疗实践。MedChain的推出填补了现有基准数据集在评估大型语言模型(LLM)在临床决策中的不足,为医疗AI系统的发展提供了新的标准。
当前挑战
MedChain数据集面临的挑战主要集中在两个方面。首先,构建过程中需要确保数据的真实性和准确性,这要求研究人员在数据收集和处理阶段进行严格的质量控制。其次,该数据集旨在解决现有基准数据集在评估LLM在临床决策中的不足,特别是在个性化信息、互动性和顺序性方面的缺失。这些挑战要求MedChain在设计和实施过程中不断优化,以确保其能够有效评估和提升医疗AI系统的性能。
常用场景
经典使用场景
MedChain数据集在临床决策支持系统(CDSS)中展现了其经典应用场景。通过模拟真实的临床工作流程,该数据集涵盖了从专科转诊、病史采集、检查、诊断到治疗的五个关键阶段。这种全面的模拟使得研究人员能够评估和优化基于大型语言模型(LLM)的智能代理在处理复杂、动态的临床决策任务中的表现。MedChain不仅提供了详细的个性化患者信息,还通过交互性和顺序性的设计,确保了评估环境的逼真性,从而为LLM在实际临床环境中的应用提供了宝贵的测试平台。
解决学术问题
MedChain数据集解决了当前学术研究中一个关键问题:缺乏能够全面评估LLM在真实临床环境中决策能力的基准数据集。现有的医学知识评估数据集往往忽略了患者个性化信息、临床决策的交互性和顺序性,导致LLM在实际应用中的表现受限。MedChain通过提供包含个性化信息、交互式咨询和顺序决策的多样化临床案例,填补了这一空白,为研究人员提供了一个更为真实和全面的评估工具。这不仅推动了LLM在医学领域的研究进展,也为未来开发更为智能和适应性强的临床决策支持系统奠定了基础。
衍生相关工作
MedChain数据集的发布催生了一系列相关研究工作,特别是在多智能体协作和检索增强生成(RAG)技术在医学领域的应用。例如,MedChain-Agent框架通过引入反馈机制和MedCase-RAG模块,显著提升了LLM在处理顺序临床任务中的表现。这一框架的成功应用激发了更多关于如何优化多智能体系统以应对复杂临床决策的研究。此外,MedChain还推动了医学图像分析和报告生成领域的研究,通过提供丰富的医学图像和相应报告,促进了图像识别和自然语言处理技术在医学诊断中的融合应用。
以上内容由AI搜集并总结生成


