Egocentric2Embodiment dataset (E2E-3M)
收藏arXiv2025-12-19 更新2025-12-20 收录
下载链接:
https://zgc-embodyai.github.io/PhysBrain/
下载链接
链接失效反馈官方服务:
资源简介:
E2E-3M数据集是由香港科技大学(广州)和中关村研究院等机构联合构建的大规模第一人称视角视频问答数据集,旨在通过人类第一人称视频数据提升机器人的物理智能。该数据集包含300万条结构化标注数据,数据来源于Ego4D、BuildAI和EgoDex等多源人类第一人称视频,通过Egocentric2Embodiment翻译流程将原始视频转化为多层次的视觉问答监督信号。数据集标注过程采用模式驱动的自动化流程,涵盖时间、空间、力学等七种互补的问答模式,并通过规则验证确保标注质量。该数据集主要用于训练和评估第一人称视角下的视觉语言动作(VLA)模型,解决机器人领域因缺乏大规模第一人称数据导致的规划与交互推理能力不足问题。
The E2E-3M dataset is a large-scale first-person video question answering (QA) dataset jointly developed by institutions including Hong Kong University of Science and Technology (Guangzhou) and Zhongguancun Institute. It aims to enhance the physical intelligence of robots via human first-person video data. This dataset contains 3 million structured annotated samples, sourced from multiple human first-person video datasets such as Ego4D, BuildAI, and EgoDex. Raw videos are converted into multi-level visual QA supervision signals via the Egocentric2Embodiment pipeline. The dataset’s annotation process adopts a pattern-driven automated workflow, covering seven complementary QA modes including temporal, spatial, mechanical and other categories, and ensures annotation quality through rule-based validation. It is primarily used to train and evaluate first-person visual language action (VLA) models, addressing the insufficient planning and interactive reasoning capabilities in robotics caused by the lack of large-scale first-person video datasets.
提供机构:
香港科技大学(广州)、中关村研究院、中关村人工智能研究所、哈尔滨工业大学、华中科技大学
创建时间:
2025-12-19
搜集汇总
数据集介绍
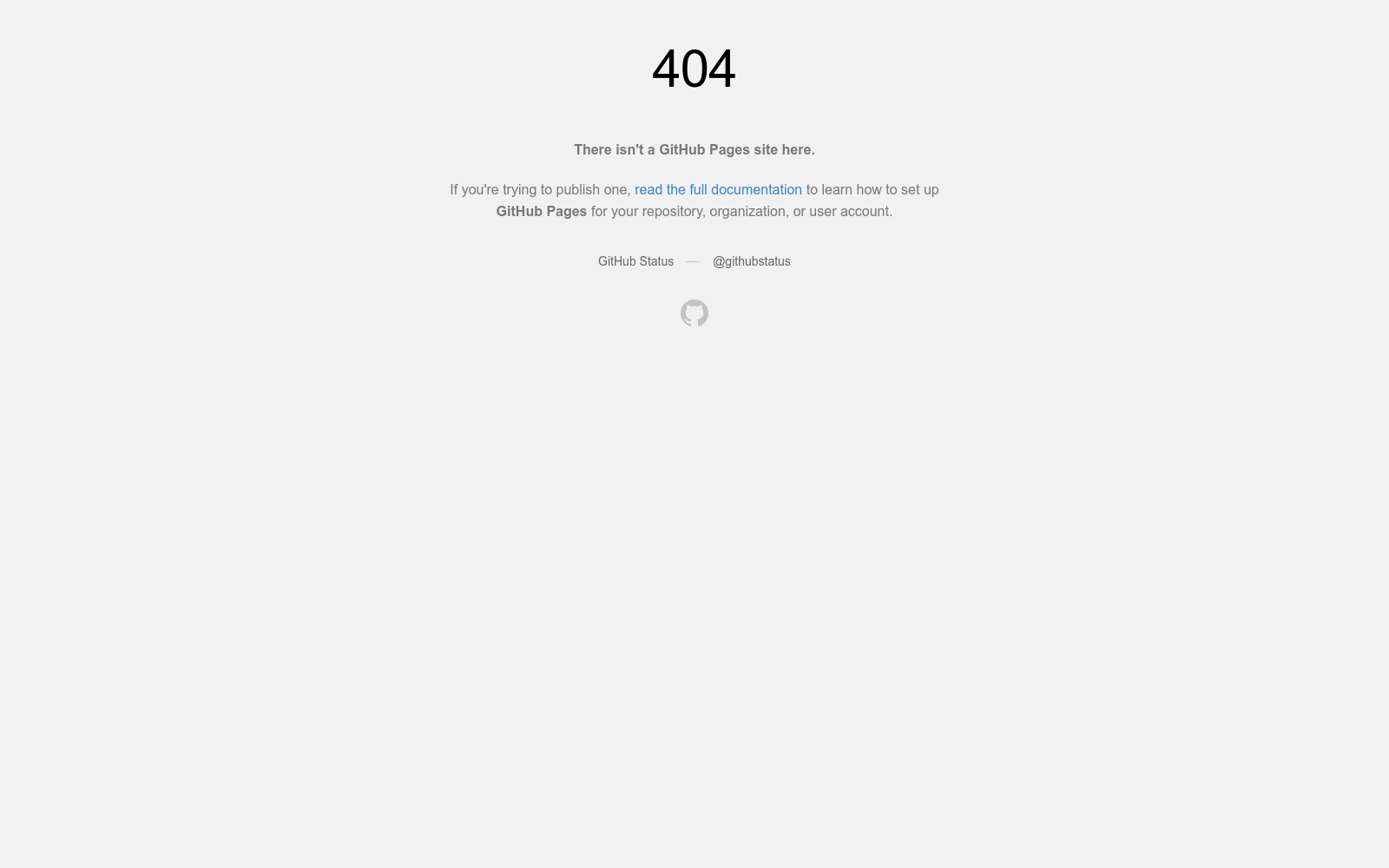
构建方式
在具身智能领域,大规模机器人数据的采集成本高昂且难以扩展,而人类第一人称视频则提供了丰富的交互语境与因果结构。E2E-3M数据集通过一套名为Egocentric2Embodiment的翻译流程构建而成,该流程将原始的第一人称视频转化为结构化、多层次的视觉问答监督数据。具体而言,流程首先对视频进行场景感知的时间分割,生成短片段作为基本监督单元;随后采用模式驱动的标注方案,为每个片段生成涵盖时间、空间、属性、力学、推理、摘要和轨迹等七种互补模式的问答对;最后通过基于确定性规则的验证逻辑,确保答案具备证据支撑、视角一致性与时间连贯性,从而产出可靠且适用于具身学习的训练信号。
特点
E2E-3M数据集的核心特点在于其广泛的数据源覆盖与丰富的语义多样性。数据集整合了来自家庭(Ego4D)、工厂(BuildAI)和实验室(EgoDex)三大互补领域的人类第一人称视频,确保了环境背景、物体构成与交互模式的显著差异。这种跨域聚合使得数据集在物体覆盖与动作覆盖两个维度上均表现出高度的互补性:家庭场景呈现极高的物体多样性,实验室环境则聚焦于精细的操作语义,而工厂数据反映了特定工具的重度使用。此外,数据集的标注设计强调对具身行为的层次化捕捉,其动作动词的多样性在推理、力学等与规划紧密相关的模式中尤为突出,为模型学习长时程规划与交互推理提供了结构化的监督。
使用方法
该数据集主要用于训练和增强视觉语言模型在具身智能任务中的第一人称理解与规划能力。典型的使用方法是对预训练的视觉语言模型(如Qwen2.5-VL-7B)在E2E-3M数据集上进行监督微调,从而获得一个具备优越自我中心感知能力的具身大脑模型,例如论文中提出的PhysBrain。经过微调的模型在EgoThink等第一人称推理基准上,尤其在规划维度,表现出显著提升。随后,该模型可作为视觉语言动作模型的高质量初始化骨干,在下游机器人控制任务(如SimulatorEnv仿真环境)中进行高效微调,仅需有限的机器人示范数据即可实现高性能,验证了从人类自我中心监督到机器人控制的有效迁移。
背景与挑战
背景概述
Egocentric2Embodiment dataset (E2E-3M) 是由香港科技大学(广州)、中关村人工智能研究院等机构的研究团队于2025年提出的,旨在解决人形机器人物理智能发展中的关键瓶颈。该数据集的核心研究问题在于弥合视觉语言模型与具身智能之间的视角鸿沟,通过大规模人类第一人称视频数据,为机器人提供可扩展的具身监督信号。其创新性体现在将原始自我中心视频转化为结构化、多层次的视觉问答监督,显著提升了模型在自我中心场景下的规划与交互推理能力,对推动视觉语言动作模型的泛化与效率具有重要影响力。
当前挑战
E2E-3M数据集致力于应对自我中心具身智能领域的双重挑战。在领域问题层面,自我中心感知存在视角快速变化、手部遮挡频繁、长时程规划困难等固有难题,导致现有模型在交互推理与状态跟踪方面表现不足。在构建过程中,挑战主要集中于如何将原始人类自我中心视频转化为可靠且结构化的训练监督,包括确保时序一致性、证据可验证性以及跨场景语义覆盖,同时避免生成过程中的幻觉与模糊性,从而为具身大脑学习提供高质量、可扩展的基础数据。
常用场景
经典使用场景
在具身智能领域,Egocentric2Embodiment数据集(E2E-3M)为视觉-语言-动作模型提供了关键的第一人称视角训练资源。该数据集通过系统化流程将大规模人类第一人称视频转化为结构化、多层次的视觉问答监督信号,涵盖家庭、工厂和实验室等多种场景。其经典应用场景在于为具身大脑模型提供丰富的自我中心感知与交互推理训练,显著提升模型在长时程规划、手物交互理解和时空一致性推理等方面的能力,为后续机器人控制任务奠定坚实的认知基础。
衍生相关工作
E2E-3M数据集的推出催生了一系列围绕自我中心监督与具身智能融合的创新研究。基于该数据集训练的PhysBrain模型衍生出PhysGR00T和PhysPI等视觉-语言-动作架构,这些工作进一步探索了不同层次的视觉-语言表征与动作专家的耦合机制。同时,该数据集也为EgoVLA、Being-H0等利用人类第一人称视频进行机器人策略学习的研究提供了数据基础与方法启示,推动了跨视角协作、手部运动编码和物理对齐等方向的进展,丰富了具身智能领域的算法生态。
数据集最近研究
最新研究方向
在具身智能领域,Egocentric2Embodiment数据集(E2E-3M)正推动从第三人称视觉语言模型向第一人称具身理解的范式转移。该数据集通过结构化标注流程,将大规模人类第一人称视频转化为多层次、模式驱动的视觉问答监督信号,有效弥合了视觉感知与物理交互之间的鸿沟。前沿研究聚焦于利用此类人类中心数据作为可扩展的监督来源,以增强模型在长时程规划、接触推理及视角变化理解等方面的能力,从而为类人机器人提供更高效的物理智能初始化。这一方向不仅缓解了机器人数据收集的高成本瓶颈,也为视觉语言动作模型的样本效率与泛化性能开辟了新路径,在工业自动化、家庭服务机器人等热点场景中展现出深远影响。
相关研究论文
- 1PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence香港科技大学(广州)、中关村研究院、中关村人工智能研究所、哈尔滨工业大学、华中科技大学 · 2025年
以上内容由遇见数据集搜集并总结生成


