indian_food_images
收藏Hugging Face2025-08-15 更新2025-08-16 收录
下载链接:
https://huggingface.co/datasets/priya-dev/indian_food_images
下载链接
链接失效反馈官方服务:
资源简介:
这是一个包含印度食品图像的数据集,共有20个类别,包括汉堡、黄油烤饼、奶茶、恰巴提、黑扁豆面包等。数据集分为训练集和测试集,可用于图像分类任务。
This is a dataset consisting of Indian food images, which includes 20 categories such as hamburger, butter naan, masala chai, chapati, black dal bread and so on. The dataset is split into a training set and a test set, and can be used for image classification tasks.
创建时间:
2025-08-13
搜集汇总
数据集介绍
构建方式
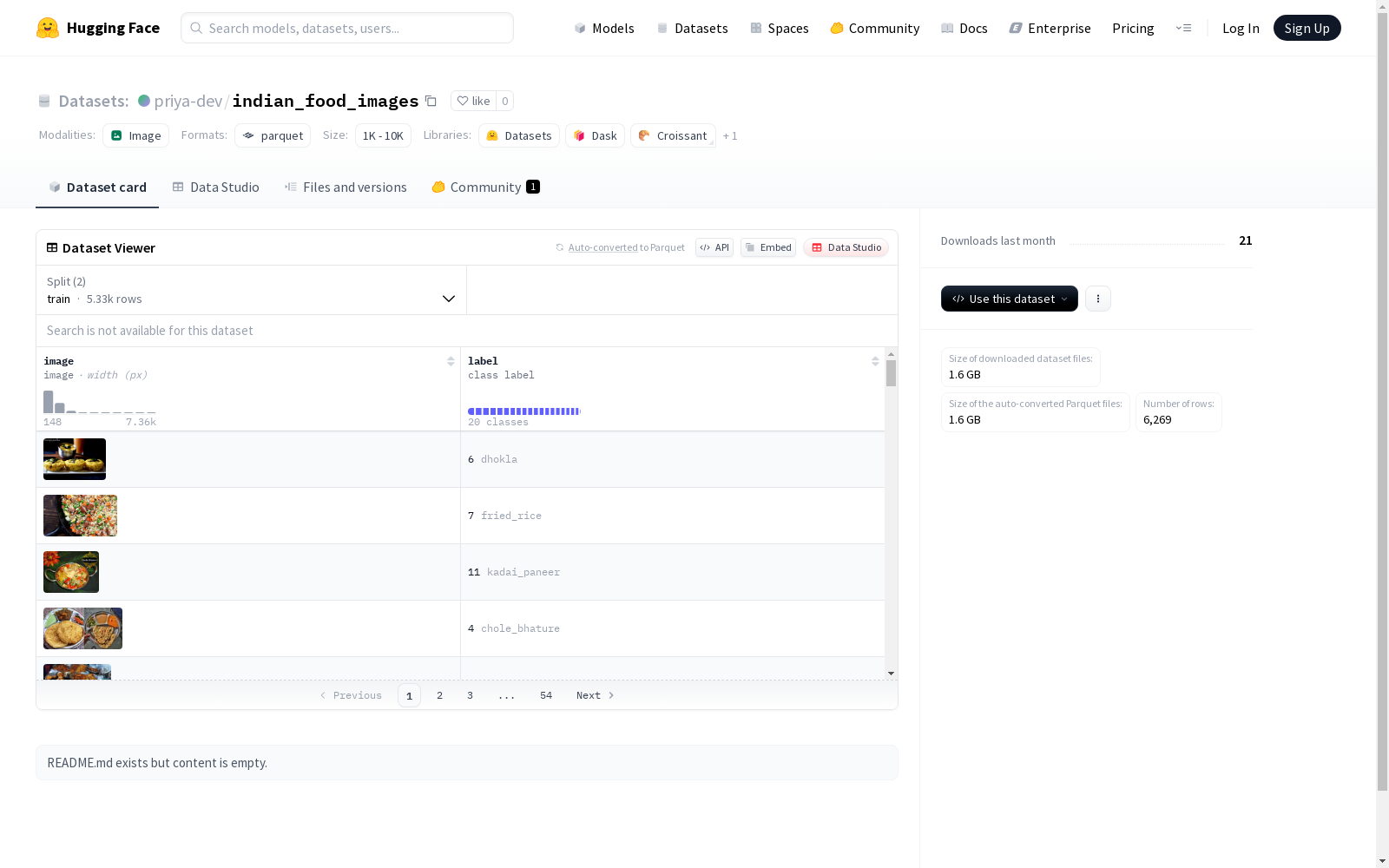
在印度美食文化研究领域,indian_food_images数据集通过系统化采集构建而成。该数据集包含5328张训练图像和941张测试图像,涵盖从传统小吃到现代融合菜等20类印度特色美食。数据收集过程注重菜品的多样性,每张图像均经过专业标注,确保类别标签的准确性,为计算机视觉任务提供高质量的基准数据。
特点
该数据集最显著的特点是涵盖印度饮食文化的广度和深度,包含chole_bhature、masala_dosa等地域特色菜品,以及pizza等国际化食品。图像数据具有丰富的视觉特征,从质感到色彩都保留了原始食物的真实属性。类别平衡的设计使模型能够全面学习不同美食的特征,而精确的标注则为监督学习提供了可靠基础。
使用方法
研究者可利用该数据集开展多类图像分类模型的训练与评估。建议采用卷积神经网络或视觉Transformer等先进架构,通过加载标准化的train-test拆分进行模型开发。数据集的层次化标签体系支持细粒度分类研究,同时也可用于跨文化饮食偏好的可视化分析,为食品识别领域提供新的研究视角。
背景与挑战
背景概述
Indian_food_images数据集聚焦于印度传统美食的图像识别领域,由计算机视觉与饮食文化研究交叉领域的学者于近年构建完成。该数据集收录了20类最具代表性的印度本土菜肴图像,包括黄油馕、恰帕提、马萨拉多萨等特色食品,旨在为食品识别算法提供具有文化特异性的训练资源。其构建得到了印度理工学院等机构的支持,通过系统性地采集印度多元饮食文化的视觉样本,填补了南亚食品图像数据集的研究空白,为跨文化食品计算提供了重要基准。
当前挑战
该数据集面临的核心挑战在于解决印度食品的高度形变识别问题,同类菜肴因地域差异呈现显著视觉变化,如萨摩萨饺的造型差异或恰伊茶的浓度变化。数据采集过程中遭遇了光照条件不统一、背景杂乱等现实场景干扰,部分小众菜品样本存在类别不平衡现象。标注环节需克服食品文化知识门槛,确保传统菜肴如豆糊玛卡尼与奶油馕的准确区分,这对标注人员的本土文化素养提出了特殊要求。
常用场景
经典使用场景
在计算机视觉与食品识别领域,indian_food_images数据集为研究者提供了丰富的印度食物图像样本,涵盖20类经典印度菜肴。该数据集最典型的应用场景是训练深度学习模型进行多类别食品图像分类,研究人员通过卷积神经网络或视觉Transformer等架构,实现对不同印度食物的精准识别。数据集的高质量标注和多样性特征使其成为食品图像分类任务的基准测试平台。
实际应用
在实际应用层面,该数据集支撑了智能餐饮系统的开发,如自动点餐识别系统和饮食健康管理应用。餐厅可利用基于该数据集训练的模型实现菜品自动识别,提升服务效率;健康类APP则可通过食物识别帮助用户追踪营养摄入。数据集中包含的印度特色小吃图像,特别适用于开发面向印度市场的智能化餐饮解决方案。
衍生相关工作
围绕该数据集已产生多项重要研究,包括基于深度学习的印度食物分类算法优化、跨文化食品识别迁移学习等。部分工作探索了数据增强技术在提升模型对印度食物识别准确率方面的应用,另有研究将该数据集与其它地域食品数据集结合,构建了全球食品识别基准。这些衍生研究显著丰富了食品计算领域的方法体系。
以上内容由遇见数据集搜集并总结生成


