HuggingFaceFW/fineweb
收藏Hugging Face2025-07-11 更新2024-05-18 收录
下载链接:
https://hf-mirror.com/datasets/HuggingFaceFW/fineweb
下载链接
链接失效反馈官方服务:
资源简介:
FineWeb数据集包含超过15万亿个经过清理和去重的英文网页数据,源自CommonCrawl。数据处理的优化目标是提升大语言模型(LLM)的性能,并且使用了datatrove库进行大规模数据处理。数据集的目标是成为RefinedWeb的完全开源复制,并在性能上超越RefinedWeb及其他高质量网页数据集。
FineWeb数据集包含超过15万亿个经过清理和去重的英文网页数据,源自CommonCrawl。数据处理的优化目标是提升大语言模型(LLM)的性能,并且使用了datatrove库进行大规模数据处理。数据集的目标是成为RefinedWeb的完全开源复制,并在性能上超越RefinedWeb及其他高质量网页数据集。
提供机构:
HuggingFaceFW
原始信息汇总
数据集概述
基本信息
- 名称: FineWeb
- 许可证: ODC-By
- 任务类别: 文本生成
- 语言: 英语
- 数据集大小: 超过1TB
配置详情
- 默认配置: 数据路径为
data/*/* - 样本配置:
sample-10BT: 数据路径为sample/10BT/*sample-100BT: 数据路径为sample/100BT/*sample-350BT: 数据路径为sample/350BT/*
- 特定年份配置:
- 例如:
CC-MAIN-2024-10: 数据路径为data/CC-MAIN-2024-10/* - 包含自2013年以来的所有CommonCrawl数据
- 例如:
数据集结构
- 数据分割: 训练集
- 数据文件路径: 根据不同配置,路径有所不同,如
data/*/*或sample/10BT/*等
使用方法
- 使用
datatrove: 通过ParquetReader读取数据 - 使用
huggingface_hub: 通过snapshot_download下载数据 - 使用
datasets: 通过load_dataset加载数据
数据集样本
- 样本大小:
sample-10BT: 约10B gpt2 tokens (27.6GB)sample-100BT: 约100B gpt2 tokens (277.4GB)sample-350BT: 约350B gpt2 tokens (388GB)
数据集详细信息
- 数据来源: CommonCrawl
- 数据处理: 使用
datatrove库进行优化处理 - 数据性能: 优于其他高质量网络数据集,如C4、Dolma-v1.6等
下载与使用
- 下载选项: 可下载完整数据集或特定年份的数据
- 使用示例: 提供了Python代码示例,展示如何使用不同工具加载和处理数据
数据集性能评估
- 评估结果: 提供了评估结果和基准测试,显示数据集在多个任务上的表现
未来工作
- 改进方向: 计划继续探索数据集质量的提升方法
搜集汇总
数据集介绍
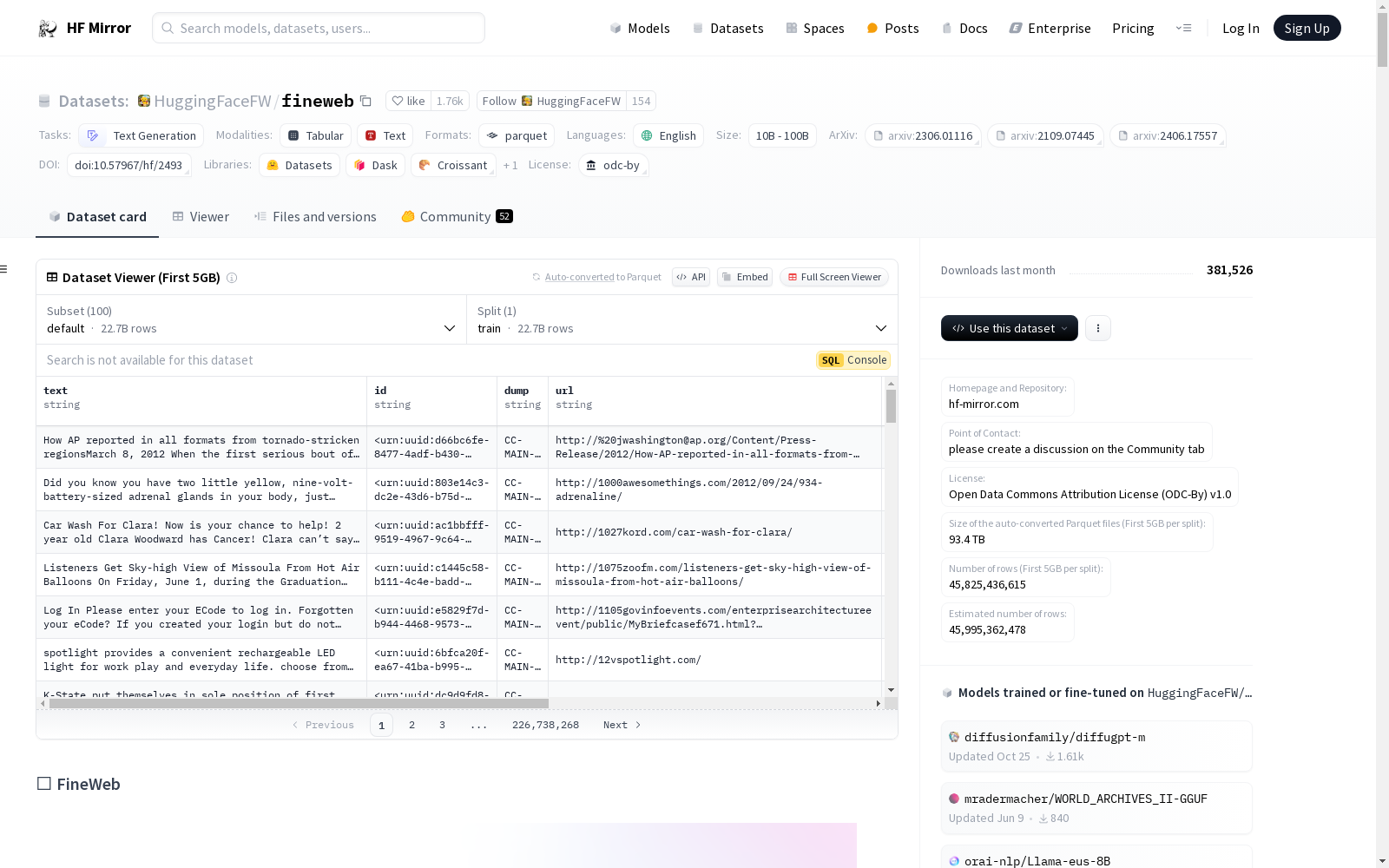
构建方式
🍷 FineWeb数据集的构建基于CommonCrawl的多个爬虫数据,涵盖了自2013年以来的大量网页内容。数据处理流程经过精心优化,以提升大型语言模型(LLM)的性能。该数据集通过使用🏭 [`datatrove`](https://github.com/huggingface/datatrove/)库进行大规模数据处理,确保了数据的高质量和去重效果。此外,数据集的构建过程中还引入了额外的过滤步骤,以进一步提高数据质量,使其在性能上超越了原始的🦅 RefinedWeb数据集。
特点
🍷 FineWeb数据集的一个显著特点是其庞大的规模,包含了超过15万亿个标记(tokens),这些标记经过清洗和去重处理,确保了数据的高质量。此外,该数据集在处理过程中采用了先进的去重和过滤技术,使其在多个基准任务上的表现优于其他常用的优质网络数据集,如C4、Dolma-v1.6、The Pile、SlimPajama和RedPajam2。数据集的多样性和高质量使其成为训练大型语言模型的理想选择。
使用方法
🍷 FineWeb数据集可以通过多种方式进行访问和使用。用户可以选择加载整个数据集或特定的爬虫数据(如CC-MAIN-2024-10)。此外,数据集还提供了多个样本版本,如`sample-350BT`、`sample-100BT`和`sample-10BT`,以满足不同用户的需求。使用者可以通过🏭 [`datatrove`](https://github.com/huggingface/datatrove/)库、`huggingface_hub`或`datasets`库来加载和处理数据。详细的加载和使用方法在数据集的README文件中有详细说明。
背景与挑战
背景概述
🍷 FineWeb数据集由超过15万亿个经过清洗和去重处理的英文网页数据标记组成,源自CommonCrawl。该数据集的创建旨在优化大型语言模型(LLM)的性能,并通过使用大规模数据处理库[`datatrove`](https://github.com/huggingface/datatrove/)进行处理。FineWeb最初旨在完全开放地复制[RefinedWeb](https://huggingface.co/papers/2306.01116)数据集,但在添加额外的过滤步骤后,其性能显著超越了原始的RefinedWeb,并且在多个基准任务上优于其他高质量网页数据集。该数据集的发布旨在促进自然语言处理领域的研究,特别是针对大规模语言模型的训练和评估。
当前挑战
FineWeb数据集在构建过程中面临多个挑战。首先,数据的去重和清洗过程需要高效且精确,以确保数据质量。其次,处理和存储超过15万亿个标记的数据量巨大,对计算资源和存储技术提出了高要求。此外,如何在保持数据多样性的同时,过滤掉低质量和重复的内容,是一个复杂的问题。最后,评估数据集对模型性能的影响,需要设计并实施一系列基准测试,以确保结果的可靠性和可重复性。这些挑战不仅涉及技术层面,还包括对数据伦理和社会影响的深入考虑。
常用场景
经典使用场景
FineWeb数据集的经典使用场景主要集中在自然语言生成任务中。该数据集通过提供超过15万亿个经过清洗和去重处理的英文网页数据,为大规模语言模型(LLM)的训练提供了丰富的语料库。研究人员和开发者可以利用这些数据来训练和微调模型,以提升其在文本生成、摘要、翻译等任务中的表现。
衍生相关工作
FineWeb数据集的发布催生了一系列相关研究和工作。例如,研究人员基于该数据集开发了新的数据清洗和去重方法,进一步提升了数据质量。同时,基于FineWeb训练的模型在多个NLP基准测试中表现优异,推动了相关领域的技术进步。此外,FineWeb的开源性质也促进了社区的协作和创新,激发了更多基于该数据集的研究和应用。
数据集最近研究
最新研究方向
在自然语言处理领域,FineWeb数据集因其庞大的数据量和高质量的文本内容,成为研究大型语言模型(LLM)性能优化的重要资源。最新研究方向主要集中在通过进一步的过滤和优化技术,提升数据集的质量,从而增强模型的表现。研究者们正在探索更精细的文本去重方法和数据清洗策略,以减少噪声和冗余信息,提高训练数据的纯度。此外,FineWeb数据集还被用于评估和比较不同数据集对模型性能的影响,特别是在多任务学习和跨领域应用中的表现。这些研究不仅有助于提升现有模型的性能,还为未来开发更高效、更智能的语言模型奠定了基础。
以上内容由遇见数据集搜集并总结生成


