tokenized-mix
收藏Hugging Face2025-11-27 更新2025-11-28 收录
下载链接:
https://huggingface.co/datasets/Ba2han/tokenized-mix
下载链接
链接失效反馈官方服务:
资源简介:
Tokenized Mix Dataset是一个混合型数据集,包含了多种语言的文本数据,主要包含土耳其语和英语。该数据集已经使用PleIAs/Baguettotron分词器进行了预处理,总共有45,900,000行数据,共计10,527,369,194个token。数据集中的文本来源于不同的子数据集,包括网页、合成数据、论坛、社交媒体等,每个子数据集都有各自的token数量统计。
Tokenized Mix Dataset is a hybrid multilingual text dataset primarily consisting of Turkish and English content. This dataset has been preprocessed using the PleIAs/Baguettotron tokenizer, with a total of 45,900,000 rows of data and 10,527,369,194 tokens. The text in the dataset is sourced from various sub-datasets including web pages, synthetic data, forums, social media, and other sources, and each sub-dataset has its own token count statistics.
创建时间:
2025-11-26
原始信息汇总
Tokenized Mix Dataset 概述
数据集基本信息
- 标签: turkey, english, tokenized
- 处理工具: PleIAs/Baguettotron tokenizer
- 总数据行数: 45,900,000
- 总标记数量: 10,527,369,194
组成数据集及标记数量
主要数据集(超过10亿标记)
- Ba2han/fineweb2-filtered-tr: 3,019,417,201 标记
- Ba2han/vngrs-web-filtered: 2,344,009,433 标记
大型数据集(1亿-10亿标记)
- Ba2han/synth-2M: 1,065,541,743 标记
- turkish-nlp-suite/OzenliDerlem/Havadis: 925,168,097 标记
- Ba2han/HPLT2-filtered-edu-tr: 419,451,594 标记
- Ba2han/finePDF-filtered-tr: 416,161,029 标记
- hcsolakoglu/turkish-wikipedia-qa-4-million: 395,897,764 标记
- nothingiisreal/Reddit-Dirty-And-WritingPrompts: 303,280,640 标记
- sentence-transformers/reddit-title-body: 227,834,825 标记
- turkish-nlp-suite/OzenliDerlem/KulturHaritasi: 156,046,649 标记
- turkish-nlp-suite/OzenliDerlem/ViralMedya: 153,756,908 标记
- motionlabs/fineweb-ultra-mini: 145,284,462 标记
- HuggingFaceFW/fineweb-edu-llama3-annotations: 135,818,661 标记
- turkish-nlp-suite/OzenliDerlem/TeknoYazilar: 125,001,199 标记
- Ba2han/synth-tr: 112,278,999 标记
中型数据集(1000万-1亿标记)
- HuggingFaceFW/finepdfs_eng_Latn_labeled: 76,565,204 标记
- ProCreations/Ultra-FineWeb-EDU: 63,214,970 标记
- Q-bert/InstrucTurca-formatted: 59,850,877 标记
- turkish-nlp-suite/OzenliDerlem/GeziNotlari: 47,197,837 标记
- turkish-nlp-suite/ForumSohbetleri/memurlar: 36,273,579 标记
- turkish-nlp-suite/OzenliDerlem/PopulerBilim: 33,852,083 标记
- turkish-nlp-suite/OzenliDerlem/Perdearkasi-Yorumlar: 33,838,313 标记
- ozertuu/eksiSozlukScrapy: 32,699,888 标记
- turkish-nlp-suite/ForumSohbetleri/kadinlarklubu: 23,939,835 标记
- turkish-nlp-suite/ForumSohbetleri/tahribat: 23,924,184 标记
- turkish-nlp-suite/OzenliDerlem/YazarinKaleminden: 23,401,119 标记
- turkish-nlp-suite/ForumSohbetleri/donanimhaber: 18,155,152 标记
- turkish-nlp-suite/ForumSohbetleri/turkiyeforum: 14,889,624 标记
- turkish-nlp-suite/ForumSohbetleri/donanimarsivi: 11,856,148 标记
- turkish-nlp-suite/ForumSohbetleri/wardom: 11,743,935 标记
- turkish-nlp-suite/OzenliDerlem/SusluTrendler: 11,108,352 标记
- turkish-nlp-suite/ForumSohbetleri/technopatsosyal: 10,885,328 标记
- turkish-nlp-suite/ForumSohbetleri/forumum: 10,607,676 标记
小型数据集(低于1000万标记)
- turkish-nlp-suite/ForumSohbetleri/wmaraci: 8,393,945 标记
- Lambent/elementary-1024-fineweb-edu-sample: 7,480,716 标记
- turkish-nlp-suite/OzenliDerlem/Serzenisler: 7,254,955 标记
- turkish-nlp-suite/ForumSohbetleri/iyinet: 7,134,401 标记
- acheong08/nsfw_reddit: 5,159,150 标记
- turkish-nlp-suite/OzenliDerlem/MasalMasal: 2,992,719 标记
搜集汇总
数据集介绍
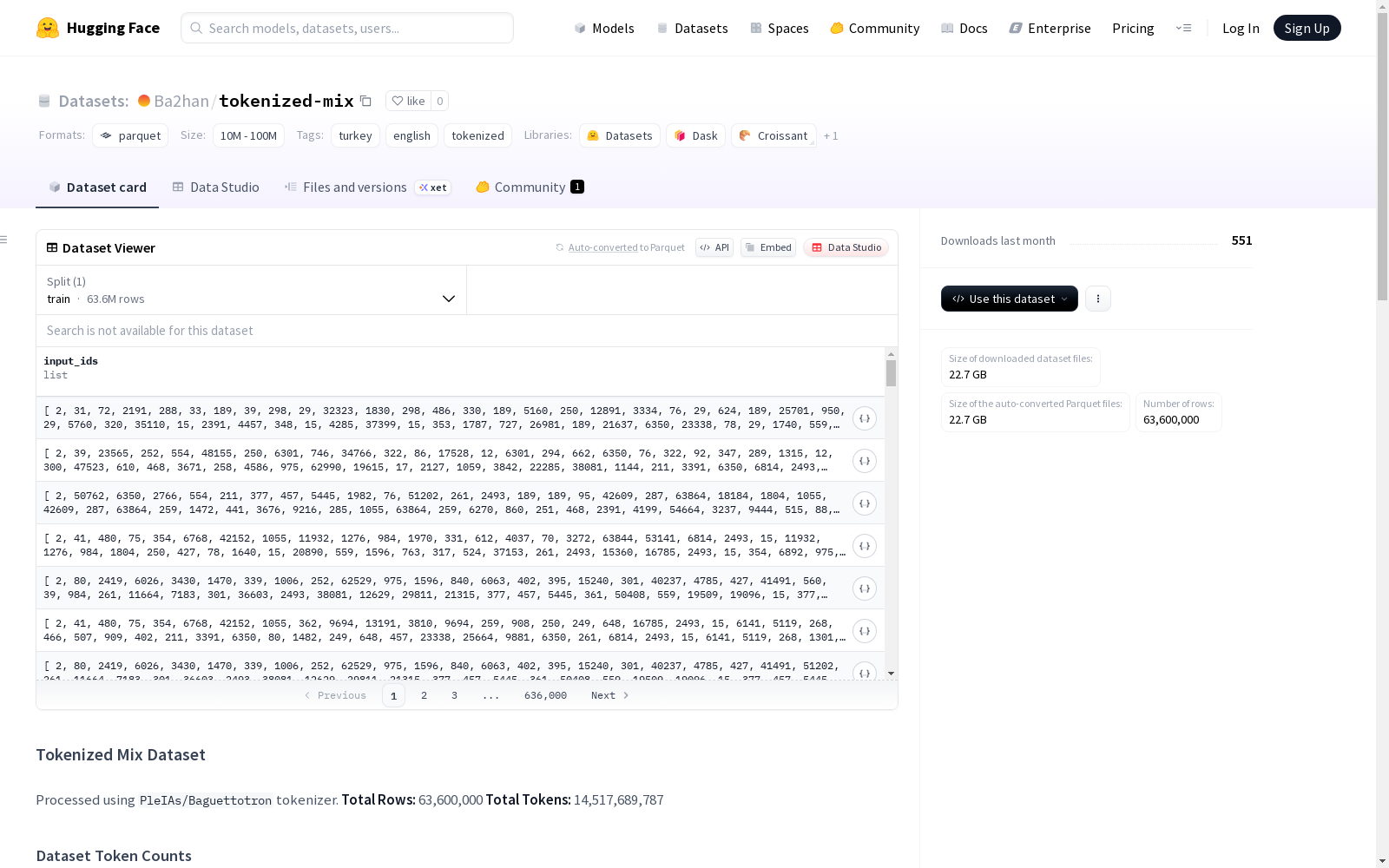
构建方式
在自然语言处理领域,大规模语料库的构建是模型训练的基础。Tokenized Mix数据集通过集成多个公开语料源实现数据融合,涵盖土耳其语和英语文本。其构建过程采用PleIAs/Baguettotron分词器对原始语料进行统一处理,确保词汇单元的标准化。该数据集整合了包括FineWeb过滤文本、VNGRS网络数据、合成文本以及土耳其新闻媒体等39个独立子集,通过严格的过滤流程保证数据质量,最终形成包含4590万行文本、105亿个词汇单元的综合语料库。
特点
多语言混合语料库的独特价值在于其丰富的语言表征能力。本数据集最显著的特点是同时包含土耳其语和英语两种语言内容,其中土耳其语料占比显著,为研究低资源语言提供了重要支持。数据规模方面,总词汇量超过百亿级别,其中Ba2han/fineweb2-filtered-tr子集贡献最多词汇量。数据来源多样化特征明显,既包含维基百科问答等结构化数据,也涵盖社交媒体论坛、新闻媒体等非正式文本,这种多源异构特性为训练具有广泛适应性的语言模型奠定了坚实基础。
使用方法
针对预训练语言模型的需求,该数据集提供了标准化的使用路径。研究人员可直接加载经过分词的语料,无需额外预处理即可投入模型训练。使用时应关注不同子集的语言分布特性,建议根据具体任务需求调整数据采样策略。对于土耳其语相关研究,可重点采用标记量靠前的土耳其语子集;若需平衡多语言训练,则可按比例混合英语和土耳其语数据。该数据集兼容主流深度学习框架,支持流式读取以应对大规模数据处理需求,为语言模型的迭代优化提供持续数据支撑。
背景与挑战
背景概述
在多语言自然语言处理研究蓬勃发展的背景下,tokenized-mix数据集应运而生,它整合了土耳其语和英语的丰富语料资源。该数据集由PleIAs/Baguettotron分词器统一处理,涵盖新闻、百科、论坛对话及文学创作等多种文本类型,总规模达4590万行文本与105亿个分词单元。其构建融合了Ba2han、turkish-nlp-suite等研究团队的成果,旨在为跨语言模型训练提供标准化、大规模的分词数据基础,显著推动了低资源语言与英语的联合建模研究进程。
当前挑战
该数据集致力于解决多语言分词统一性与语义连贯性难题,其核心挑战在于平衡土耳其语黏着语特性与英语分析语结构的分词差异。构建过程中面临异构数据源对齐的复杂性,包括网络文本噪声过滤、文化特定表达归一化,以及论坛口语化文本与正式文献的粒度协调。此外,超百亿级分词规模对存储效率与分布式处理架构提出了严峻考验,需在保证跨语言表征一致性的同时维持原始语料的语义完整性。
常用场景
经典使用场景
在自然语言处理领域,多语言预训练模型的构建需要大规模高质量的语料支持。Tokenized-Mix数据集通过整合土耳其语与英语的多样化文本资源,为跨语言模型训练提供了标准化输入。其经典应用体现在利用统一的分词器处理异构数据,使研究人员能够直接将其应用于Transformer架构的预训练流程,显著提升了多语言语境下的词嵌入质量与语义表示一致性。
实际应用
在实际应用层面,该数据集支撑着智能客服系统的多语言响应生成、跨境电子商务的文本理解等场景。其包含的社交媒体对话与专业技术文档,能够训练出适应真实语言环境的模型,显著提升机器翻译系统在土耳其语-英语互译任务中的流畅度,同时为教育科技领域的自适应学习系统提供语言素材支撑。
衍生相关工作
基于该数据集衍生的经典工作包括多语言BERT的土耳其语适配研究,以及基于HuggingFace生态的微调框架开发。研究者利用其标准化分词特性构建了TurkuNLP系列模型,推动了大语言模型在土耳其语社区的普及。此外,该数据集还催生了针对混合语言代码切换现象的分析工具,为语言接触研究提供了新范式。
以上内容由遇见数据集搜集并总结生成


