natural-questions-hard-negatives
收藏资源简介:
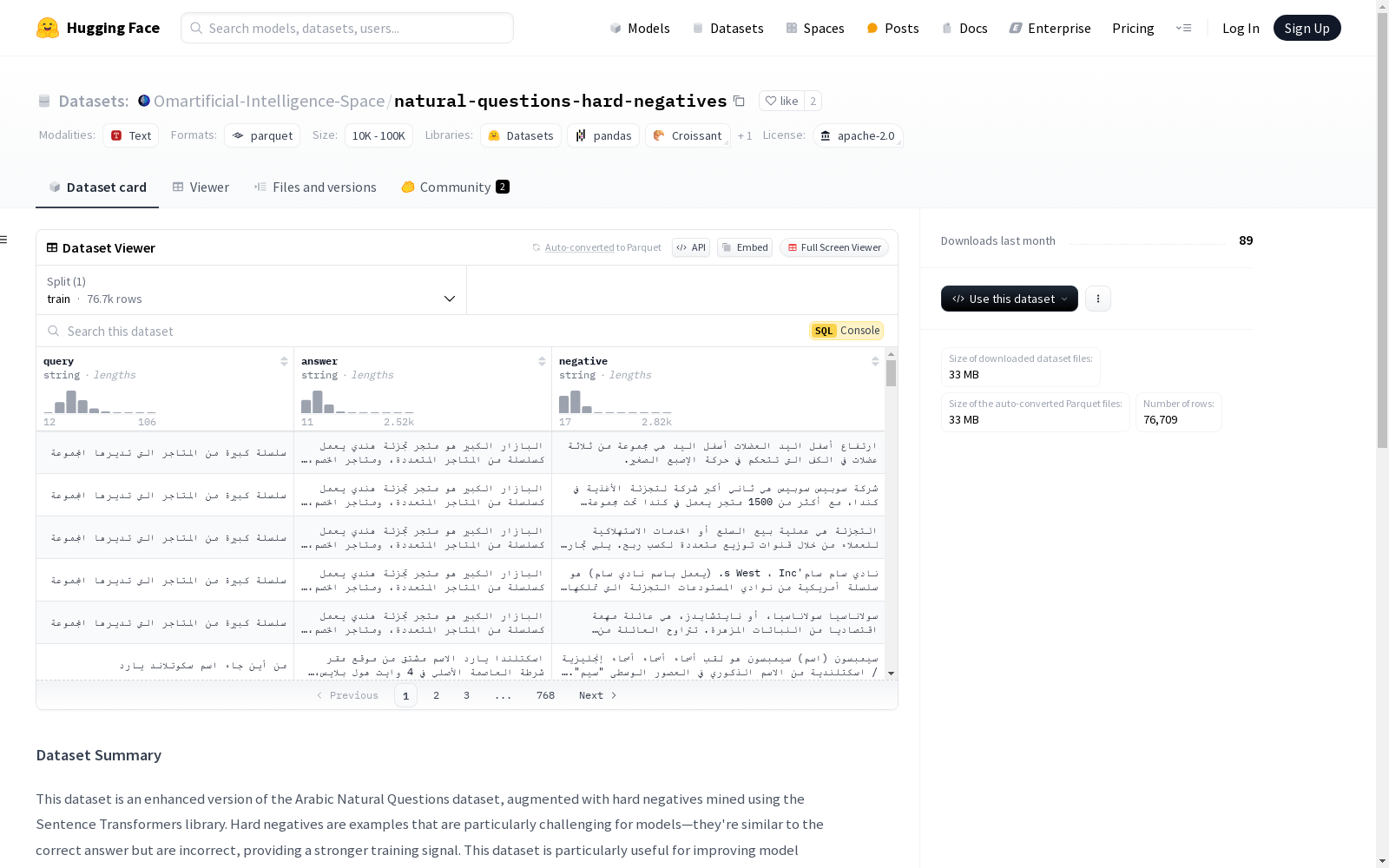
该数据集是阿拉伯语自然问题数据集的增强版本,通过使用Sentence Transformers库挖掘的硬负样本进行扩充。硬负样本是特别具有挑战性的例子,它们与正确答案相似但却是错误的,为模型提供了更强的训练信号。该数据集特别适用于改进问答、语义相似性和信息检索等任务中的模型性能。数据集包含三个主要特征:查询(query)、正确答案(answer)和硬负样本(negative)。数据集的创建过程中,使用了Sentence Transformers的mine_hard_negatives工具来挖掘硬负样本,以提供一组具有挑战性的训练示例,增强模型在细微差别区分方面的能力。数据集的语言为阿拉伯语,且目前没有相关的排行榜。
This dataset is an enhanced version of the Arabic natural questions dataset, augmented with hard negative samples mined using the Sentence Transformers library. Hard negative samples are particularly challenging examples that are similar to the correct answer but incorrect, providing stronger training signals for models. This dataset is specifically designed to improve model performance on tasks such as question answering, semantic similarity, and information retrieval. The dataset contains three core features: query, correct answer, and hard negative sample. During the dataset creation process, the mine_hard_negatives tool from Sentence Transformers was used to mine hard negative samples, providing a set of challenging training examples to enhance the model's ability to distinguish subtle nuances. The dataset is in Arabic, and currently, there are no relevant leaderboards available.
数据集概述
数据集信息
- 配置名称: triplet
- 特征:
- query: 字符串类型,表示原始问题或查询。
- answer: 字符串类型,表示与查询相关的正确答案。
- negative: 字符串类型,表示挖掘出的硬负样本,即与正确答案相似但错误的文本。
- 分割:
- train: 包含76709个样本,总大小为112942322字节。
- 下载大小: 33017802字节
- 数据集大小: 112942322字节
- 许可证: Apache 2.0
数据集结构
- query: 原始问题或查询。
- answer: 与查询相关的正确答案。
- negative: 挖掘出的硬负样本,即与正确答案相似但错误的文本。
数据集创建
- 初始数据集: 基于阿拉伯语自然问题数据集。
- 挖掘过程: 使用Sentence Transformers的mine_hard_negatives工具挖掘硬负样本,参数如下:
- range_min: 10
- range_max: 50
- max_score: 0.8
- margin: 0.1
- sampling_strategy: random
语言
- 数据集语言为阿拉伯语。
任务与排行榜
- 支持任务: 语义文本相似性、信息检索、问答系统。
- 排行榜: 该数据集目前没有关联的排行榜。