Habitat模拟器构建的遮挡感知数据集
收藏arXiv2026-03-11 更新2026-03-12 收录
下载链接:
https://xin-yu-gao.github.io/beacon
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由代尔夫特理工大学团队基于Habitat仿真平台构建,专注于语言条件导航中的遮挡场景分析。数据集包含多视角RGB-D观测数据及自然语言指令,通过模拟家具或动态障碍物遮挡目标区域的情景,支持机器人局部导航目标的几何推理。其构建过程融合了深度投影与鸟瞰图特征编码,旨在解决复杂室内环境中因遮挡导致的空间 grounding 难题,为提升视觉-语言模型在机器人导航中的三维空间理解提供基准。
This dataset is constructed by the team at Delft University of Technology based on the Habitat simulation platform, focusing on occluded scene analysis in language-conditioned navigation. It contains multi-view RGB-D observation data and natural language instructions. By simulating scenarios where furniture or dynamic obstacles occlude target regions, it supports geometric reasoning for robotic local navigation goals. Its construction process integrates depth projection and bird's-eye view feature encoding, aiming to address the spatial grounding challenges caused by occlusions in complex indoor environments, and provides a benchmark for improving the 3D spatial understanding of vision-language models in robotic navigation.
提供机构:
代尔夫特理工大学·认知机器人学系
创建时间:
2026-03-11
搜集汇总
数据集介绍
构建方式
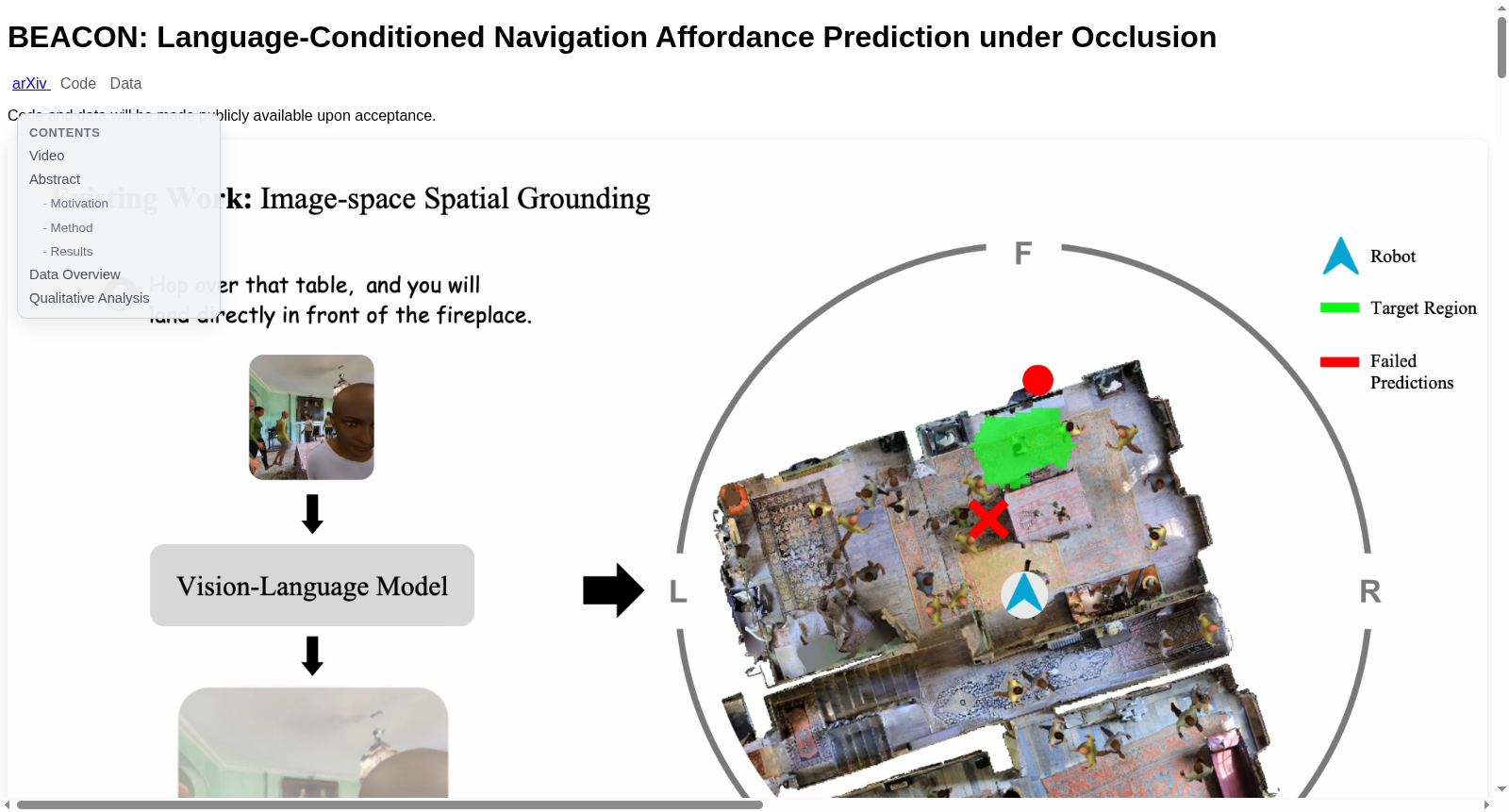
在机器人导航领域,对遮挡环境下语言指令的理解与空间推理提出了严峻挑战。该数据集基于Habitat模拟器构建,通过从Landmark-RxR数据集中提取局部导航样本,将每个指令片段转化为起始视点、语言指令及目标位置的三元组。在起始视点处,系统渲染四个环绕视角的RGB-D图像,并将目标限制在局部有界区域内,同时过滤掉需要探索或存在较大高度变化的样本。为了精准评估模型在遮挡场景下的性能,数据集进一步定义了遮挡目标子集,采用深度一致性检验来识别目标在所有视角中均被遮挡的样本,并引入了非交互式移动行人以模拟真实环境中的动态遮挡。
特点
该数据集的核心特点在于其专注于语言条件下的局部导航任务,并特别强调对遮挡目标的处理。数据集不仅包含了丰富的室内场景和多样化的自然语言指令,还通过严谨的深度投影与几何一致性检验,构建了一个专门用于评估模型在目标被静态结构或动态物体遮挡时推理能力的子集。其环绕多视角的RGB-D观测数据为模型提供了全面的环境几何信息,而基于测地距离的目标区域监督则鼓励模型在可通行空间内进行预测,从而显著提升了输出结果的结构合理性与实用性。
使用方法
该数据集主要用于训练和评估像BEACON这类旨在预测鸟瞰图可通行性热图的模型。在使用时,模型接收单时间步的环绕视角RGB-D观测和一条自然语言指令作为输入,其训练目标是输出一个以机器人为中心的局部鸟瞰图热图,其中每个单元格的数值表示其作为导航目标的可能性。训练过程采用两阶段策略:第一阶段通过自动生成的以自我为中心的指令对视觉语言模型进行微调;第二阶段则结合几何感知的鸟瞰图编码器,并使用测地目标区域监督进行端到端训练。评估时,通过选取热图中概率最高的位置作为预测目标,并以预测点落入标注目标周围测地距离区域内的准确率作为核心评价指标。
背景与挑战
背景概述
在具身智能与机器人导航领域,语言指令驱动的局部导航要求机器人根据自然语言描述,在复杂室内环境中推断出可通行的目标位置。然而,现有基于视觉-语言模型的方法通常在图像空间进行推理,其预测结果受限于当前视野内的可见像素,难以有效处理由家具或移动行人造成的目标遮挡问题。为应对这一挑战,由代尔夫特理工大学认知机器人学系的研究人员于2026年提出的BEACON研究框架,配套构建了一个基于Habitat模拟器的遮挡感知数据集。该数据集旨在支撑语言条件下、存在遮挡场景的局部导航目标预测研究,通过利用模拟器生成包含四向环视RGB-D观测与自然语言指令的配对数据,为开发能够推理被遮挡目标位置的模型提供了关键训练与验证基础。其核心研究问题聚焦于如何融合几何感知的鸟瞰图表示与视觉-语言模型的语义理解能力,以提升机器人在遮挡条件下的空间 grounding 与导航决策性能,对推动鲁棒且实用的具身导航系统发展具有重要意义。
当前挑战
该数据集致力于解决的领域核心挑战,是语言条件导航中因目标被遮挡而导致的视觉 grounding 失效问题。具体而言,当导航目标被场景结构或动态障碍物完全或部分遮挡时,依赖单视角或图像空间预测的现有方法难以准确推断目标在可通行地面上的精确位置。这要求模型必须具备超越直接视觉证据的推理能力,整合场景布局、地标关系及自我中心的空间线索。在数据集构建过程中,主要挑战体现在如何高效且逼真地模拟现实世界中复杂的遮挡情形。这包括在Habitat模拟器中定义并自动化筛选出目标被遮挡的数据样本,以及引入非交互的行人模型来模拟动态遮挡,同时确保生成的数据在指令复杂性、场景多样性与几何合理性之间取得平衡,并为模型训练提供有效的密集监督信号(如基于测地距离的目标区域掩码),以引导模型学习在鸟瞰图空间中预测符合指令且结构可行的导航目标。
常用场景
经典使用场景
在具身智能与机器人导航领域,Habitat模拟器构建的遮挡感知数据集为语言条件导航研究提供了关键基准。该数据集通过模拟室内复杂环境中的动态与静态遮挡场景,系统化地评估模型在目标被家具或行人遮蔽时的空间推理能力。研究者利用其多视角RGB-D观测数据与自然语言指令,训练模型预测机器人本体的鸟瞰图可通行性热图,从而在遮挡条件下实现精准的局部目标定位。
解决学术问题
该数据集有效解决了视觉语言模型在图像空间推理中的固有局限,即难以处理观测视野外的目标定位问题。通过提供结构化遮挡场景与几何标注,它支持开发融合三维空间线索的鸟瞰图预测方法,显著提升了模型在遮挡环境下的语言接地能力。其意义在于推动了机器人导航从依赖可见证据到具备空间推断能力的范式转变,为开放词汇指令下的鲁棒性导航奠定了实证基础。
衍生相关工作
基于该数据集的特性,衍生出一系列聚焦于三维空间表征与语言融合的经典工作。例如,BEACON模型通过引入本体对齐的视觉语言模块与几何感知的鸟瞰图编码器,实现了遮挡条件下的可通行性预测;后续研究进一步探索了多模态特征加权、时空注意力机制等方向,推动了RoboPoint、RoboRefer等图像空间基线方法向三维几何空间的演进,形成了机器人空间认知的新技术脉络。
以上内容由遇见数据集搜集并总结生成


