adugeen/personal-facts-msc
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/adugeen/personal-facts-msc
下载链接
链接失效反馈官方服务:
资源简介:
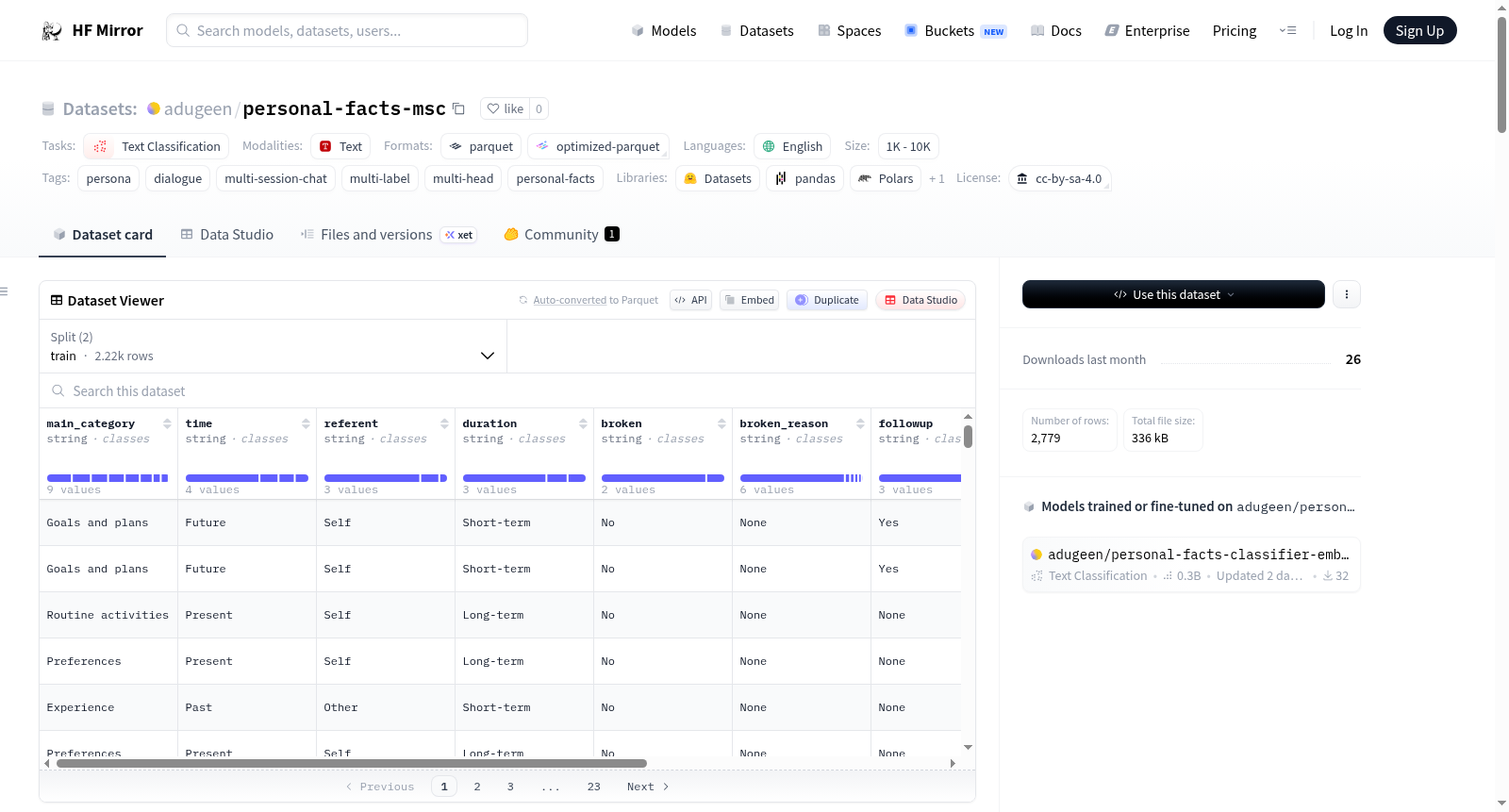
Personal Facts (MSC) — Multi-Dimensional Annotation是一个手动标注的数据集,包含2,779个从Multi-Session Chat (MSC)语料库中抽取的个人事实。这些事实标注了七个维度,包括主题、时间锚定、指称、生命周期、有效性以及对话延续潜力。数据集分为训练集(2,223个样本)和测试集(556个样本),并提供了每个字段的详细描述和标签清单。数据集的构建过程包括从MSC语料库中抽取、去重、嵌入和聚类,然后进行手动标注。数据集可用于训练和评估多标签分类器、质量过滤、记忆策略研究以及审计更大规模的人设语料库。数据集的局限性包括单一标注者、类别不平衡、源偏差以及标注噪声。
Personal Facts (MSC) — Multi-Dimensional Annotation is a manually annotated dataset of 2,779 personal facts sampled from the Multi-Session Chat (MSC) corpus, labeled across seven dimensions that jointly characterize a facts topic, temporal anchoring, referent, lifetime, validity, and dialogue-continuation potential. The dataset is split into a training set (2,223 examples) and a test set (556 examples), with detailed descriptions of each field and label inventory provided. The datasets construction involves sampling from the MSC corpus, deduplication, embedding, clustering, and manual annotation. It is intended for training and benchmarking multi-label classifiers, quality filtering of persona corpora, memory-policy research, and auditing larger persona corpora. Limitations include single annotator, class imbalance, source bias, and noisy annotations.
提供机构:
adugeen
搜集汇总
数据集介绍
构建方式
Personal Facts (MSC) 数据集源自多会话对话语料库 Multi-Session Chat (MSC),其构建过程严谨且系统。首先,从对话响应中提取的个人事实通过精确文本匹配进行去重,随后利用 BGE-M3 模型进行稠密嵌入与 L2 归一化,并采用 K-Means 聚类算法将事实归入 1,000 个簇中。为确保主题覆盖的广度,每个簇至多采样 3 条事实,最终得到 2,779 条候选事实。在标注环节,每条事实由作者依据书面指南在 Label Studio 平台上完成多维标注;虽然借助大语言模型(如 Gemma-3-27B、Qwen-3-VL-32B、GPT-5-mini)进行预标注作为参考锚点,但所有标签均经过人工逐一审查与修正,以确保标注质量。
特点
该数据集的独特之处在于其多维标注体系,将个人事实从七个维度进行联合刻画,涵盖主题类别、时间锚定、指代对象、持续期限、有效性及其原因,以及对话延续潜力。相较于已有的 PeaCoK 方案,本数据集引入了“人口统计学”与“个人财产”两个全新顶级类别,并新增了持续期限、有效性及对话延续性三个维度,从而实现了对个人事实更为精细的结构化描述。数据集包含训练集 2,223 条与测试集 556 条,测试集按主题类别进行分层采样(80/20 划分),可作为黄金标准评估集。此外,标注一致性在 300 条事实的预实验中达到较高水准,有效性判定的表面一致性高达 92.1%。
使用方法
本数据集可通过 Hugging Face Datasets 库直接加载,使用代码 `load_dataset("adugeen/personal-facts-msc")` 即可获取包含训练集与测试集的数据字典。每条样本由候选事实文本及其前序对话轮次上下文构成,并附带七个维度的详尽标签。数据适用于多任务或多标签分类模型的训练与评估,尤其适用于人物画像事实的表征学习。其有效性标注可直接用于对话系统个人记忆的质量过滤,而持续期限与对话延续性维度则为长期记忆策略与对话管理研究提供了抓手。在评估模型性能时,鉴于类别分布存在不均衡(如“关系”类别仅占 1.5%),建议采用宏平均 F1 值而非准确率,以获得更为可靠的评价指标。
背景与挑战
背景概述
Personal Facts (MSC) 数据集由研究者 Konstantin Zaitsev 于2026年创建,旨在弥补现有对话系统中个人事实表征的维度不足。该数据集从多会话聊天(MSC)语料库中精心采样2779条个人事实,并在七个标注维度上进行细粒度人工标注,包括主题、时间锚定、指代对象、持续时间、有效性及对话延续潜力等。其核心研究问题围绕如何为对话代理构建更精准、更可操作的个人记忆表征,扩展了PeaCoK方案,新增人口统计与财产拥有两大类别以及持续时间、有效性与后续对话三个维度。该数据集为多标签分类、记忆策略研究及人物语料质量过滤等领域提供了重要的基准资源,推动了对话系统中长期记忆与人格建模的发展。
当前挑战
该数据集面对的核心领域挑战包括:对话系统需从非结构化对话中精准提取并分类个人事实,现有方案多局限于事实对相似性比较,缺乏对事实时效性、有效性和对话延续性的统一建模。构建过程中,研究者面临多维标签体系设计的复杂性,尤其是broken_reason维度一致性极低(Fleiss' κ仅0.458),表明区分意见、多事实捆绑、语境不足等无效原因高度依赖主观判断;此外,长尾类别如人际关系的样本占比仅约1.5%,导致模型在此类标签上泛化困难。单标注者导致的标注偏差以及MSC语料库的英文众包属性,进一步限制了数据集向其他语言或专业领域的迁移能力,需要在后续研究中通过多标注者协同和跨语料库验证加以克服。
常用场景
经典使用场景
Personal Facts (MSC) 数据集的核心价值在于其多维度的标注体系,为对话智能体的个性化事实表征提供了精细化的训练与评估基准。其典型使用场景是训练和评估多头或多标签分类器,用于从对话上下文中抽取并分类用户陈述中蕴含的个人事实。具体而言,模型需要同时预测该事实的语义范畴(如偏好、经历、目标与规划)、时间锚定(过去、现在、未来)、所指对象(自我、他人)、持续时长(短期、长期)、有效性(有效或无效)以及对话延续潜力(是否适合追问)。这种多维度联合标注的设计,使得模型不仅能够识别事实的存在,更能理解其语义属性与对话功能,从而为更自然、更具记忆能力的对话系统奠定基础。
解决学术问题
该数据集直面了对话系统中长期记忆管理与个性化建模的两大核心难题。在学术层面,它首先解决了个人事实细粒度分类标准不足的问题,通过引入人口统计信息、所有物以及失效原因等全新标注维度,大幅扩展了传统的个人事实分类体系。其次,它有效支撑了对话记忆中数据质量过滤的研究,标注中的有效性标记及失效原因为自动检测并过滤噪声事实提供了可靠的监督信号。此外,持续时长与对话延续性维度的引入,为学术社区探索长期记忆的遗忘策略与话题连贯性策略提供了量化评估工具,推动了对话智能体从短时记忆向持久化、情境化理解能力的跃迁。
衍生相关工作
该数据集的发布催生了一系列围绕对话模型中个人事实记忆与推理的重要工作。一方面,它启发研究者利用其多标签标注训练统一的事实抽取与分类模型,例如将动态时间注意力机制与多头分类器相结合,提升对跨会话事实的鲁棒提取能力。另一方面,其失效原因标注直接促进了对话数据质量自动审计工具的发展,研究人员在更大规模的对话语料如完整 Multi-Session Chat 上训练分类器,发现约30%的事实预测为无效,从而揭示了当前对话数据集普遍存在的事实噪声问题。此外,持续时长属性为端到端对话系统中的记忆衰减机制提供了理论依据,推动了基于事实生命周期建模的可解释记忆管理模块的设计与优化。
以上内容由遇见数据集搜集并总结生成


