LLMs-First-Task
收藏Hugging Face2025-09-06 更新2025-09-07 收录
下载链接:
https://huggingface.co/datasets/giantfish-fly/LLMs-First-Task
下载链接
链接失效反馈官方服务:
资源简介:
PI-LLM数据集用于评估大型语言模型(LLM)的工作记忆和上下文干扰能力。数据集由多个键值对组成,其中相同的键会被更新多次,模型需要为每个键检索最后一个值。由于早期信息会干扰最近信息的检索,因此数据集对LLM来说具有挑战性。README文件详细介绍了数据集的结构、评估任务以及使用各种SOTA LLMs观察到的结果。它还包括有关数据集规模、上下文长度的影响以及与认知科学的联系的信息。文件还提供了一个快速入门指南,用于使用数据集评估模型,以及一个使用AUC评分的更高级评估方法。
The PI-LLM dataset is designed to evaluate the working memory and contextual interference capabilities of Large Language Models (LLMs). The dataset consists of multiple key-value pairs, where the same key is updated multiple times, and models are required to retrieve the final corresponding value for each key. Since earlier information can interfere with the retrieval of recent information, this dataset poses significant challenges for LLMs. The README file elaborates on the dataset structure, evaluation tasks, and observed results from various state-of-the-art (SOTA) LLMs. It also covers details regarding the dataset scale, the impact of context length, and its connections to cognitive science. Additionally, the document provides a quick start guide for evaluating models using this dataset, as well as a more advanced evaluation method that employs AUC scores.
创建时间:
2025-09-02
原始信息汇总
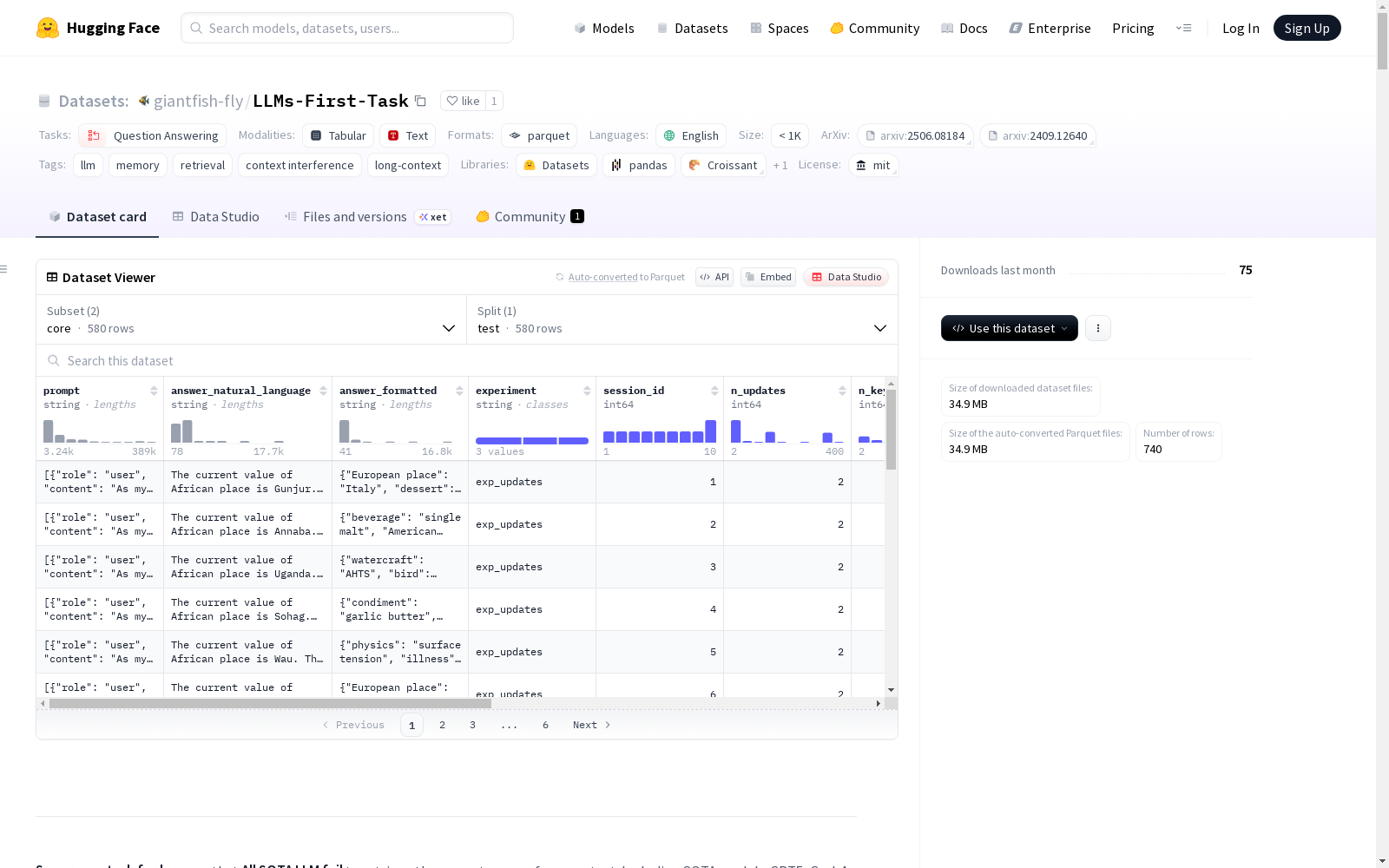
数据集概述
基本信息
- 名称: PI-LLM
- 许可证: MIT
- 语言: 英语
- 任务类别: 问答
- 标签: 大语言模型、记忆、检索、上下文干扰、长上下文
数据集配置
-
核心配置 (core)
- 描述: 随机化更新(键值对中的键被打乱)。推荐作为主要/SOTA比较设置。在最高压力层级,所有测试模型(截至2025年5月)都无法可靠恢复最终值。
- 数据文件: core.parquet
-
顺序附加配置 (sequential_additional)
- 描述: 非随机化——清晰严格的顺序块;证明短上下文(5k-8k token)已经可以对大多数大语言模型产生强烈的上下文干扰。即使使用这种格式良好的数据,许多模型的性能仍然迅速下降。
- 数据文件: sequential_additional.parquet
任务描述
键值更新范式:模型看到的内容格式为:
Key1: Value_1 Key1: Value_2 ...... Key1: Value_N
问题:Key1的当前值(最后一个值)是什么?
预期答案:Key1的当前值是Value_N。
关键发现
- 所有测试的SOTA大语言模型(包括GPT5、Grok4、DeepSeek、Gemini 2.5PRO、Mistral、Llama4等)都无法可靠检索Value_N
- 随着N值增加,答案分布从value_1到value_N,且答案越来越偏向value_1
- 人类在此任务上表现接近完美(99%+准确率),而所有大语言模型都以相同方式失败
实验维度
- 更新次数实验 (exp_updates): 随着每个键的更新次数(N)增加,大语言模型混淆早期值与最新值
- 并发键数实验 (exp_keys): 随着并发键数量增加,大语言模型的抗干扰能力和检索准确率呈对数线性下降
- 值长度实验 (exp_valuelength): 随着值长度增长,检索准确率呈对数线性下降
数据集规模
- 更新次数N从1到400
- 最多46个键组(key1到key46)组合在一起
- 所有值都不同,便于准确测量模型回答与正确答案的距离
应用场景
该数据结构常见于许多数据处理任务,如:
- 金融数据跟踪
- 健康监测(如血压读数序列)
- 光标位置跟踪
- 需要跟踪最新值的任何场景
相关资源
- 论文: https://arxiv.org/abs/2506.08184
- 演示网站: https://sites.google.com/view/cog4llm
- OpenAI MRCR数据集: https://huggingface.co/datasets/openai/mrcr
- DeepMind MRCR论文: https://arxiv.org/pdf/2409.12640v2
评估方法
提供完整的Python评估代码,包括:
- 基础准确率计算
- AUC评分(对数基1.5加权)
- 响应解析功能
- 实验结果分组分析
数据集已集成到Moonshot AI(Kimi)的内部基准测试框架中,用于评估大语言模型/代理的跟踪能力和上下文干扰。
搜集汇总
数据集介绍
构建方式
在认知科学与人工智能交叉领域的研究中,该数据集采用经典的前摄干扰范式构建,通过设计键值对更新任务来模拟多轮共指场景。具体而言,每个键被赋予从1到400次连续更新,每次更新对应一个唯一值,最终形成46组键值序列。数据生成过程中引入随机化处理,将不同键的更新交错排列以模拟现实场景中的无序变更,同时保留非随机化序列作为对照版本,确保评估的全面性与科学性。
特点
该数据集的核心特征在于其极简结构与高挑战性的结合。虽然任务对人类而言近乎 trivial,但所有测试的SOTA模型均表现出系统性检索失败。随着更新次数增加,模型回答呈现明显的对数线性衰减趋势,且错误答案偏向初始值而非最新值。数据集提供双重配置:随机化版本模拟现实干扰模式,顺序版本则揭示模型在结构化数据中的基础缺陷,二者共同凸显语言模型在共指解析与工作记忆方面的本质局限。
使用方法
研究者可通过HuggingFace接口直接加载parquet格式数据,利用提供的标准化评估框架测试模型性能。评估流程包含提示构建、响应解析与精度计算三个核心模块,支持准确率与AUC加权评分两种指标。特别推荐使用基于对数加权的AUC评分机制,其对高难度样本的敏感性更利于区分顶尖模型性能。评估脚本已集成响应字典提取与干扰维度分析功能,可直接适配主流API或本地模型接口。
背景与挑战
背景概述
LLMs-First-Task数据集由认知科学与人工智能交叉研究团队于2025年创建,旨在探索大语言模型在多重共指语境下的工作记忆极限。该数据集源于ICML 2025长上下文基础模型研讨会,其核心研究问题聚焦于模型对动态更新键值对的最终值检索能力。通过模拟人类工作记忆中的前摄干扰现象,该数据集揭示了即使是最先进的GPT-5、Grok-4等模型也无法可靠追踪最后值的本质缺陷,为长上下文建模和记忆机制研究提供了关键基准。
当前挑战
该数据集主要解决大语言模型在动态信息更新场景中的共指消解挑战,具体表现为模型难以从多次更新的相同键值对中准确检索最终值。构建过程中的核心挑战包括:设计能够诱发前摄干扰效应的多重共指结构,确保不同更新值间的语义独立性;建立精确的随机化与序列化双模式实验框架以控制变量;以及开发适用于模型输出的结构化解析算法来量化检索偏差。这些挑战直接反映了当前大语言模型在信息追踪与上下文干扰抵抗方面的根本性局限。
常用场景
经典使用场景
在长上下文语言模型评估领域,该数据集通过精心设计的键值对更新范式,系统性地测试模型在多轮共指场景下的信息检索能力。研究者将同一键名的多个更新值按随机或顺序方式排列,要求模型准确识别每个键对应的最终数值,这种设置有效模拟了现实世界中连续数据流的追踪需求。
实际应用
在医疗监护、金融交易和实时监控系统中,该数据集的评估范式具有重要应用价值。例如在连续血压监测场景中,系统需要准确记录患者最新读数而非历史数据,模型在此类任务上的表现直接关系到临床决策的可靠性。该测试框架已被集成到多个科技公司的内部评估体系,用于提升对话系统和智能代理的实时信息处理能力。
衍生相关工作
该研究推动了OpenAI的MRCR数据集和DeepMind的Gemini评估框架的发展,启发了多项关于长上下文建模的机理研究。其开创性的干扰测试方法被后续工作扩展应用到代码补全、多轮对话和文档分析等领域,促进了行业对模型记忆偏差问题的系统性认识,为下一代语言模型的架构改进提供了重要方向。
以上内容由遇见数据集搜集并总结生成


