ServicesSyntheticDataset-Dec21
收藏Hugging Face2024-12-21 更新2024-12-22 收录
下载链接:
https://huggingface.co/datasets/Abuthahir/ServicesSyntheticDataset-Dec21
下载链接
链接失效反馈官方服务:
资源简介:
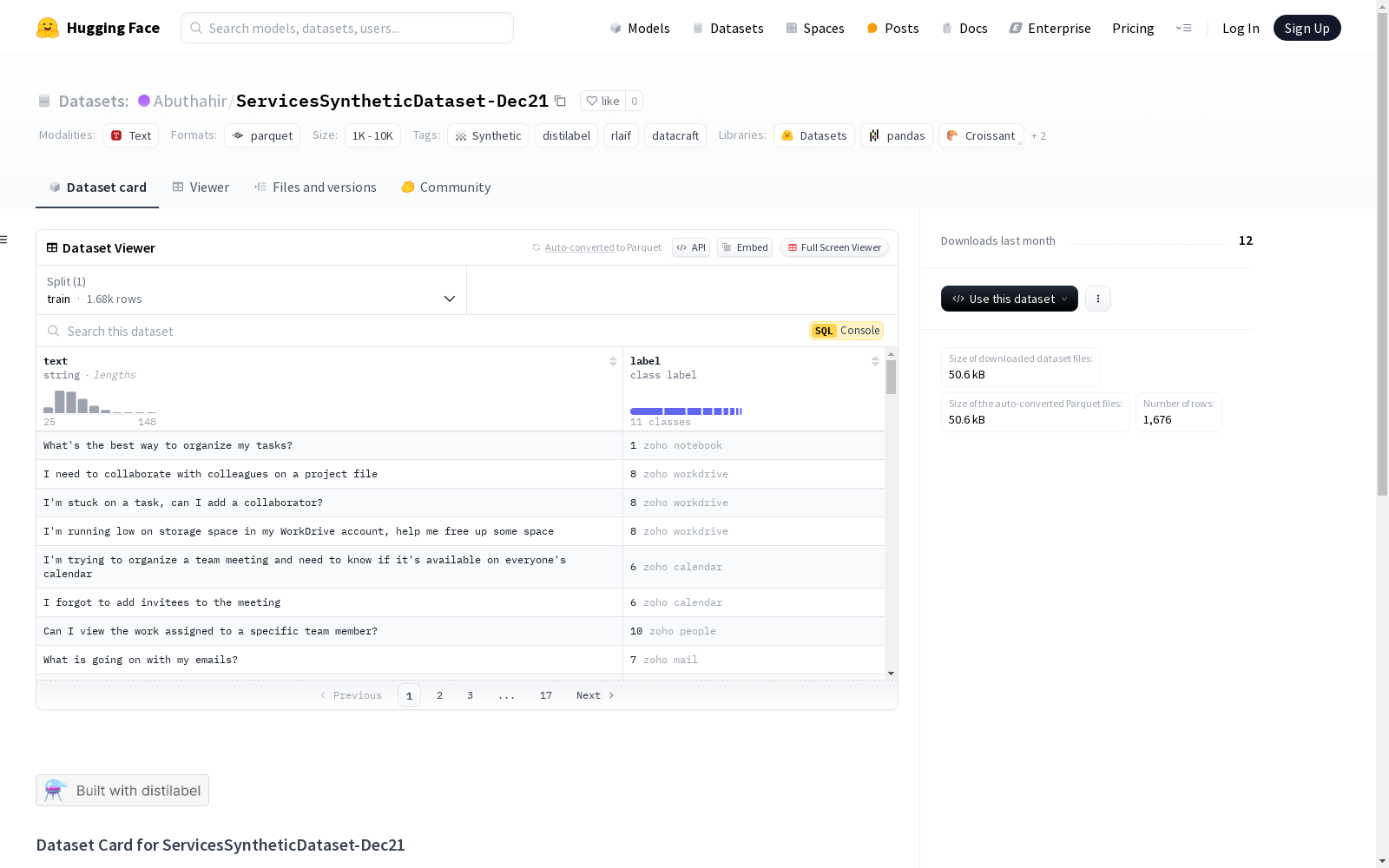
该数据集包含一个`pipeline.yaml`文件,可以用于在distilabel中重现生成该数据集的管道。数据集的结构包括文本和标签两个特征,标签对应不同的Zoho服务。数据集的大小在1K到10K之间,包含一个训练集,共有1676个样本。数据集的下载大小为50645字节,数据集大小为118778字节。数据集的配置名为'default',数据文件路径为'data/train-*'。数据集的标签包括zoho mail and people、zoho notebook等11种不同的Zoho服务。
This dataset contains a `pipeline.yaml` file that can be used to reproduce the pipeline for generating this dataset in distilabel. The dataset structure includes two features: text and label, where the labels correspond to distinct Zoho services. The dataset size ranges between 1K and 10K, with one training set consisting of 1676 samples in total. The download size of the dataset is 50645 bytes, and the stored dataset size is 118778 bytes. The configuration name of the dataset is 'default', and the data file path is 'data/train-*'. The dataset's labels cover 11 different Zoho services, including Zoho Mail and People, Zoho Notebook, and others.
创建时间:
2024-12-21
原始信息汇总
ServicesSyntheticDataset-Dec21 数据集概述
数据集信息
特征
- text: 数据类型为
string。 - label: 数据类型为
class_label,包含以下类别:- 0: zoho mail and people
- 1: zoho notebook
- 2: zoho desk
- 3: zoho projects
- 4: zoho crm
- 5: zoho cliq
- 6: zoho calendar
- 7: zoho mail
- 8: zoho workdrive
- 9: zoho bigin
- 10: zoho people
数据集划分
- train: 包含 1676 个样本,数据大小为 118778 字节。
数据集大小
- 下载大小: 50645 字节
- 数据集大小: 118778 字节
配置
- default: 数据文件路径为
data/train-*。
标签
- synthetic: 合成数据
- distilabel: 使用 Distilabel 创建
- rlaif: 相关标签
- datacraft: 数据工艺
数据集结构
- 每个样本的结构如下: json { "label": 1, "text": "Whats the best way to organize my tasks?" }
加载数据集
-
可以使用以下代码加载数据集: python from datasets import load_dataset
ds = load_dataset("Abuthahir/ServicesSyntheticDataset-Dec21", "default")
或者简化为: python from datasets import load_dataset
ds = load_dataset("Abuthahir/ServicesSyntheticDataset-Dec21")
搜集汇总
数据集介绍
构建方式
ServicesSyntheticDataset-Dec21数据集通过使用Distilabel工具构建,该工具能够自动化生成和标注数据。数据集的生成过程依赖于一个预定义的`pipeline.yaml`文件,该文件详细描述了数据生成的流程。通过Distilabel的CLI命令,用户可以轻松地复现或探索该数据集的生成配置,确保了数据集的可重复性和透明性。
特点
该数据集的主要特点在于其合成性质,通过自动化工具生成,避免了传统数据标注中的高成本和时间消耗。数据集包含多个Zoho服务相关的标签,如Zoho Mail、Zoho Notebook等,涵盖了广泛的业务场景。此外,数据集的规模适中,介于1K到10K之间,适合用于中小型模型的训练和评估。
使用方法
使用ServicesSyntheticDataset-Dec21数据集时,用户可以通过Hugging Face的`datasets`库进行加载。数据集默认配置为`default`,用户可以直接调用`load_dataset`函数加载数据。数据集的结构简单明了,每个样本包含一个文本字段和一个标签字段,便于模型训练和评估。
背景与挑战
背景概述
ServicesSyntheticDataset-Dec21数据集由Abuthahir创建,主要用于支持Zoho系列服务的文本分类任务。该数据集通过使用Distilabel工具生成,旨在帮助研究人员和开发者更好地理解和处理与Zoho服务相关的文本数据。数据集包含了多种Zoho服务的标签,如Zoho Mail、Zoho Notebook等,每个标签对应特定的服务类别。该数据集的创建不仅为自然语言处理领域提供了新的研究资源,也为企业服务领域的文本分类任务提供了有力的支持。
当前挑战
ServicesSyntheticDataset-Dec21数据集在构建过程中面临的主要挑战包括:首先,如何确保合成数据的多样性和代表性,以避免模型在实际应用中出现偏差。其次,由于数据集涉及多种Zoho服务,标签的定义和分类需要精确,以确保模型能够准确识别和分类不同的服务文本。此外,数据集的规模相对较小,如何在有限的样本中训练出高效且泛化能力强的模型也是一个重要的挑战。
常用场景
经典使用场景
ServicesSyntheticDataset-Dec21数据集主要用于训练和评估自然语言处理模型,特别是在服务分类任务中。该数据集包含多个Zoho服务相关的文本样本及其对应的标签,如Zoho Mail、Zoho Notebook等。通过使用该数据集,研究者和开发者可以训练模型以自动识别和分类用户查询或反馈中提到的具体服务,从而提升客户支持和服务管理的效率。
解决学术问题
ServicesSyntheticDataset-Dec21数据集解决了在服务分类领域中的一个关键学术问题,即如何有效地将用户生成的文本与特定的服务类别进行匹配。这一问题在客户服务自动化和智能客服系统中尤为重要。通过提供高质量的合成数据,该数据集为研究者提供了一个标准化的基准,用于评估和改进分类算法的性能,从而推动了自然语言处理技术在服务管理领域的应用和发展。
衍生相关工作
ServicesSyntheticDataset-Dec21数据集的发布催生了一系列相关研究和工作。例如,研究者利用该数据集开发了新的文本分类算法,以提高服务识别的准确性。此外,该数据集还被用于探索多标签分类和多任务学习在服务管理中的应用。这些衍生工作不仅丰富了自然语言处理领域的研究内容,还为实际应用提供了更多技术支持,推动了服务管理系统的智能化进程。
以上内容由遇见数据集搜集并总结生成


