ComposeMe
收藏arXiv2025-09-23 更新2025-09-24 收录
下载链接:
https://snap-research.github.io/composeme/
下载链接
链接失效反馈官方服务:
资源简介:
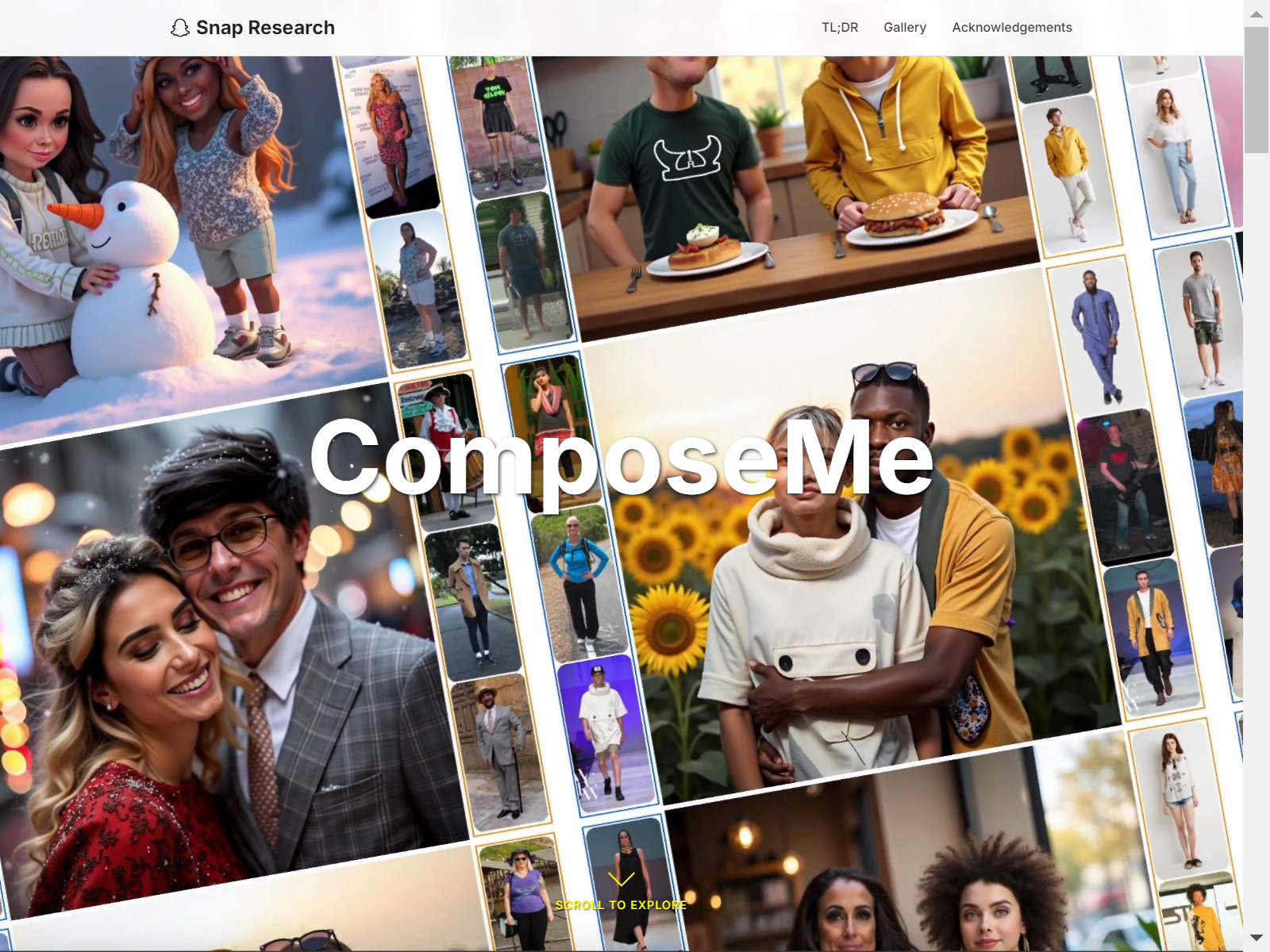
ComposeMe 数据集是用于可控人体图像生成的新框架,特别针对身份属性的组合。该数据集包含各种姿势和表情的主题,用于促进自然组合和鲁棒的解耦。数据集创建过程包括使用专用分词器处理每个视觉组件的参考图像,并将这些属性特定的标记注入到预训练的文本到图像扩散模型中。ComposeMe 的目标是实现细粒度的可控图像合成,允许用户通过指定不同的身份属性来合成图像,如面部身份、发型和服装。此外,该方法还扩展到多人生成,即使在单个图像中也能组合多个不同的身份。数据集的应用领域包括自由形式的虚拟试穿系统,以及设计人员探索不同角色之间视觉特征的创造性工具。
The ComposeMe dataset is a novel framework for controllable human image generation, specifically targeting the composition of identity attributes. This dataset includes subjects with diverse poses and expressions, aimed at facilitating natural composition and robust disentanglement. The dataset creation process involves using a specialized tokenizer to process reference images of each visual component, and injecting these attribute-specific tokens into pre-trained text-to-image diffusion models. The goal of ComposeMe is to achieve fine-grained controllable image synthesis, allowing users to generate images by specifying different identity attributes such as facial identity, hairstyle, and clothing. Furthermore, this method can be extended to multi-person generation, enabling the combination of multiple distinct identities even within a single image. The application areas of this dataset include free-form virtual try-on systems, as well as creative tools for designers to explore visual features across different characters.
提供机构:
Snap Inc., USA
创建时间:
2025-09-23
原始信息汇总
ComposeMe 数据集概述
基本信息
- 数据集名称:ComposeMe
- 发布机构:Snap Inc., USA
- 相关会议:SIGGRAPH Asia 2025
核心功能
- 支持对人类图像进行可控生成。
- 实现对多个视觉属性的解耦控制,如身份、发型和服装。
- 支持基于文本的控制。
技术方法
- 采用属性特定标记化技术,分别对身份、发型和服装进行表示。
- 使用多属性交叉参考训练策略。
- 基于预训练扩散模型进行嵌入合并和注入。
训练策略
第一阶段:单参考复制粘贴训练
- 学习每个属性的外观特征。
第二阶段:多属性交叉参考训练
- 将每个身份分解为不同的视觉属性。
- 从不同的输入图像中获取每个属性。
- 预测单独的目标图像。
- 能够从不对齐的属性输入生成自然对齐、连贯的输出。
实验内容
- 全身单人个性化
- 多属性单人个性化
- 仅面部双人个性化
- 多属性双人个性化
消融研究
- 面部和头发的交叉参考训练可有效控制表情和头部姿势。
- 服装的交叉参考训练可减轻来自服装区域的姿势泄漏。
- 多属性交叉参考训练使ComposeMe能够从不对齐的属性特定视觉提示实现高保真生成。
引用信息
bibtex @inproceedings{qian2025composeme, author = {Guocheng Gordon Qian and Daniil Ostashev and Egor Nemchinov and Avihay Assouline and Sergey Tulyakov and Kuan-Chieh Jackson Wang and Kfir Aberman}, title = {ComposeMe: Attribute-Specific Image Prompts for Controllable Human Image Generation}, booktitle = {ACM SIGGRAPH Asia 2025 Conference Proceedings}, year = {2025}, }
搜集汇总
数据集介绍
构建方式
在可控人像生成领域,ComposeMe数据集的构建采用了一种创新的多属性交叉参考训练策略。该数据集通过精心策划的跨参考训练样本,将人脸、发型和服装等视觉属性从不同个体和姿态的图像中解耦。具体流程包含两个阶段:初始的复制粘贴预训练阶段使用单参考图像对齐输入与目标,随后进入核心的多属性交叉参考微调阶段,通过故意错位的属性输入(如从不同人物图像中分别提取面部、发型和服装)来训练模型生成自然融合的输出。这种训练范式有效避免了传统方法中常见的拼贴式伪影,确保了属性在合成过程中的独立性和协调性。
使用方法
使用ComposeMe数据集时,研究者可通过属性特异性图像提示框架实现精细化的人像生成控制。具体操作分为三个步骤:首先为每个视觉属性(面部、发型、服装)提供独立的参考图像集,由专用标记器分别转换为属性特定标记;随后将这些标记与可学习的位置编码合并,形成多属性主题表征;最后通过解耦交叉注意力机制将融合后的表征注入预训练的扩散模型。在推理过程中,用户可通过调整缩放因子λ平衡图像提示与文本提示的影响权重。该数据集支持单属性单身份、多属性单身份及多属性多身份等多种生成模式,缺失属性可用黑色图像替代。这种设计使研究者能够开展可控人像合成、虚拟试穿等前沿研究。
背景与挑战
背景概述
ComposeMe数据集由Snap Inc.的研究团队于2025年提出,旨在解决个性化文本到图像生成中细粒度属性控制的难题。该数据集聚焦于人类图像合成领域,通过引入属性特定图像提示的新范式,将身份、发型和服装等视觉属性分解为独立模块。其核心研究问题在于实现多属性解耦控制,突破传统方法将整体身份视为单一概念的局限,为虚拟试穿、创意设计等应用提供了更灵活的定制化基础。这一创新推动了生成式AI在模块化组合方向的发展,显著提升了人类图像合成的可控性与真实感。
当前挑战
在解决领域问题方面,ComposeMe需应对多属性组合时的语义冲突与视觉不协调,例如不同来源的发型与面部轮廓的匹配难题。构建过程中的挑战包括跨参考训练数据集的标注复杂性,需确保不同姿态、表情下的属性对齐;同时,多属性交叉参考训练策略需克服单参考训练中属性与姿态等混淆因素的纠缠,避免生成图像出现拼贴式伪影。此外,专用标记器的设计需平衡不同属性(如面部、服装)的特征提取特异性与整体生成一致性。
常用场景
经典使用场景
在可控人像生成领域,ComposeMe数据集通过属性特异性图像提示机制,为多属性组合生成提供了经典应用场景。该数据集支持从不同来源图像中分别提取面部特征、发型和服装等视觉属性,并基于文本描述将其融合为协调的人像输出。这种模块化控制方式使得研究人员能够在保持身份一致性的同时,灵活调整局部特征,为虚拟试妆、数字人创建等任务提供了标准化测试平台。
解决学术问题
该数据集有效解决了生成式人工智能中多属性解耦控制的学术难题。传统方法将身份特征视为整体概念,难以实现发型、服装等属性的独立编辑。ComposeMe通过多属性交叉参考训练策略,突破了属性间耦合效应,使模型能够从错位输入中生成自然融合的图像。这一突破为可控生成领域提供了可量化的评估基准,推动了细粒度生成控制理论的发展。
实际应用
在实际应用层面,ComposeMe为虚拟试衣、个性化内容创作等场景提供了技术支撑。电商平台可借助该数据集构建虚拟试妆系统,用户只需上传面部照片和服装图片即可预览搭配效果。影视制作行业则能通过属性组合快速生成符合角色设定的数字形象,大幅降低特效制作成本。这些应用体现了生成式AI在消费级产品中的落地潜力。
数据集最近研究
最新研究方向
在可控人类图像生成领域,ComposeMe数据集的推出标志着模块化属性控制研究的前沿进展。该数据集聚焦于解耦身份、发型和服装等多重视觉属性的组合生成,通过属性特定图像提示技术,突破了传统方法将整体身份视为单一概念的局限。当前研究热点集中于跨参考训练策略与专用标记化器的协同优化,旨在解决多源输入不对齐导致的视觉伪影问题。这一方向对虚拟试穿、创意设计等应用产生了深远影响,为构建可配置化的人像生成系统奠定了技术基础。
相关研究论文
- 1ComposeMe: Attribute-Specific Image Prompts for Controllable Human Image GenerationSnap Inc., USA · 2025年
以上内容由遇见数据集搜集并总结生成


