有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
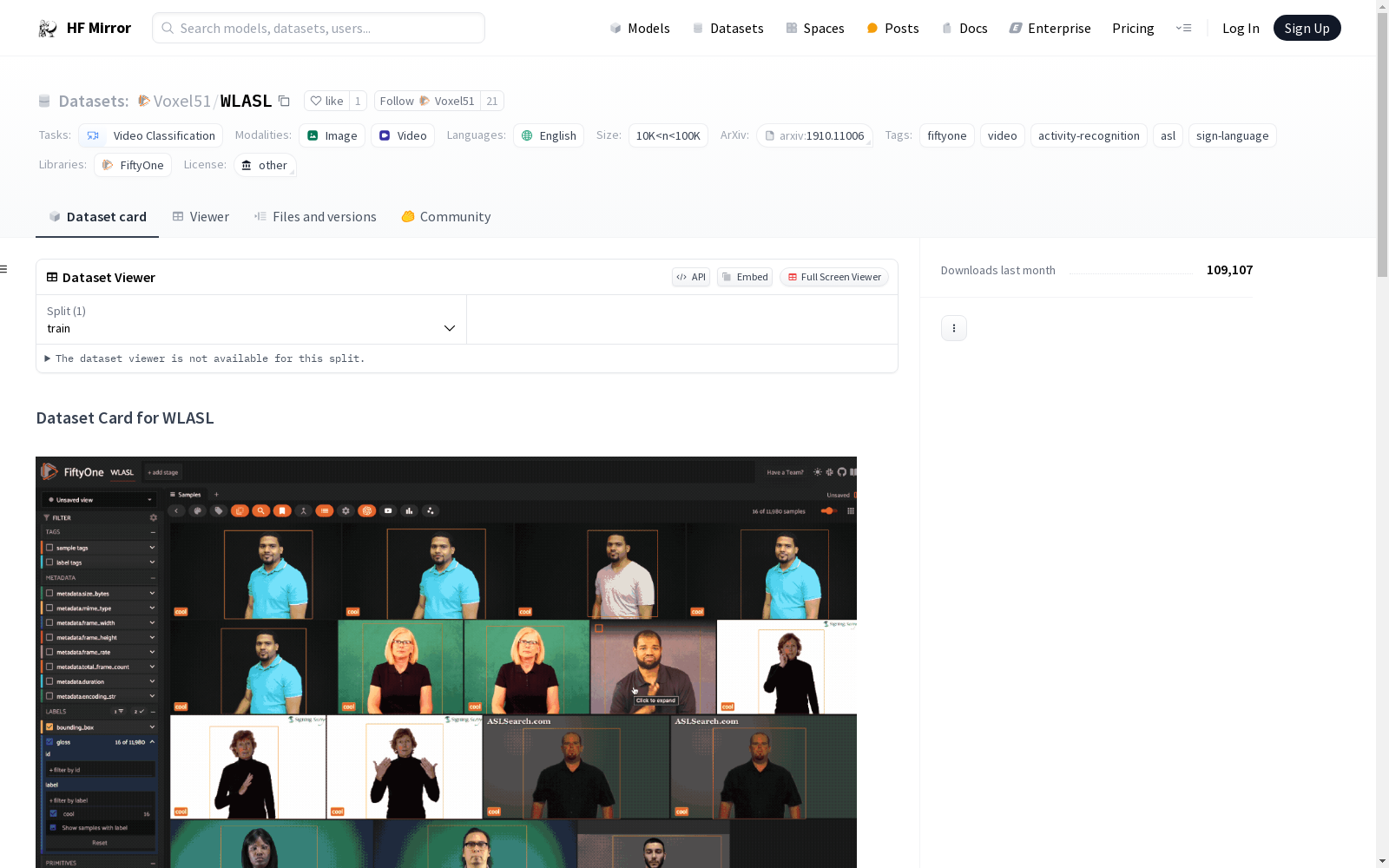
WLASL是一个专为Word-Level American Sign Language (ASL)识别设计的大型视频数据集,包含2000个ASL中的常用词汇。该数据集旨在促进手语理解的研究,并最终改善聋人和听觉社区之间的交流。
WLASL数据仅限于学术和计算用途,不允许商业使用。数据集受Computational Use of Data Agreement (C-UDA)许可。
bibtex @misc{li2020wordlevel, title={Word-level Deep Sign Language Recognition from Video: A New Large-scale Dataset and Methods Comparison}, author={Dongxu Li and Cristian Rodriguez Opazo and Xin Yu and Hongdong Li}, year={2020}, eprint={1910.11006}, archivePrefix={arXiv}, primaryClass={cs.CV} }
@inproceedings{li2020transferring, title={Transferring cross-domain knowledge for video sign language recognition}, author={Li, Dongxu and Yu, Xin and Xu, Chenchen and Petersson, Lars and Li, Hongdong}, booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages={6205--6214}, year={2020} }
中国行政区划数据
本项目为中国行政区划数据,包括省级、地级、县级、乡级和村级五级行政区划数据。数据来源于国家统计局,存储格式为sqlite3 db文件,支持直接使用数据库连接工具打开。
github 收录
网易云音乐数据集
该数据集包含了网易云音乐平台上的歌手信息、歌曲信息和歌单信息,数据通过爬虫技术获取并整理成CSV格式,用于音乐数据挖掘和推荐系统构建。
github 收录
中国交通事故深度调查(CIDAS)数据集
交通事故深度调查数据通过采用科学系统方法现场调查中国道路上实际发生交通事故相关的道路环境、道路交通行为、车辆损坏、人员损伤信息,以探究碰撞事故中车损和人伤机理。目前已积累深度调查事故10000余例,单个案例信息包含人、车 、路和环境多维信息组成的3000多个字段。该数据集可作为深入分析中国道路交通事故工况特征,探索事故预防和损伤防护措施的关键数据源,为制定汽车安全法规和标准、完善汽车测评试验规程、
北方大数据交易中心 收录
典型分布式光伏出力预测数据集
光伏电站出力数据每5分钟从电站机房监控系统获取;气象实测数据从气象站获取,气象站建于电站30号箱变附近,每5分钟将采集的数据通过光纤传输到机房;数值天气预报数据利用中国电科院新能源气象应用机房的WRF业务系统(包括30TF计算刀片机、250TB并行存储)进行中尺度模式计算后输出预报产品,每日8点前通过反向隔离装置推送到电站内网预测系统。
国家基础学科公共科学数据中心 收录
Materials Project
材料项目是一组标有不同属性的化合物。数据集链接: MP 2018.6.1(69,239 个材料) MP 2019.4.1(133,420 个材料)
OpenDataLab 收录