TemplateMath Part I: TemplateGSM
收藏arXiv2024-11-27 更新2024-11-29 收录
下载链接:
https://huggingface.co/datasets/math-ai/TemplateGSM
下载链接
链接失效反馈官方服务:
资源简介:
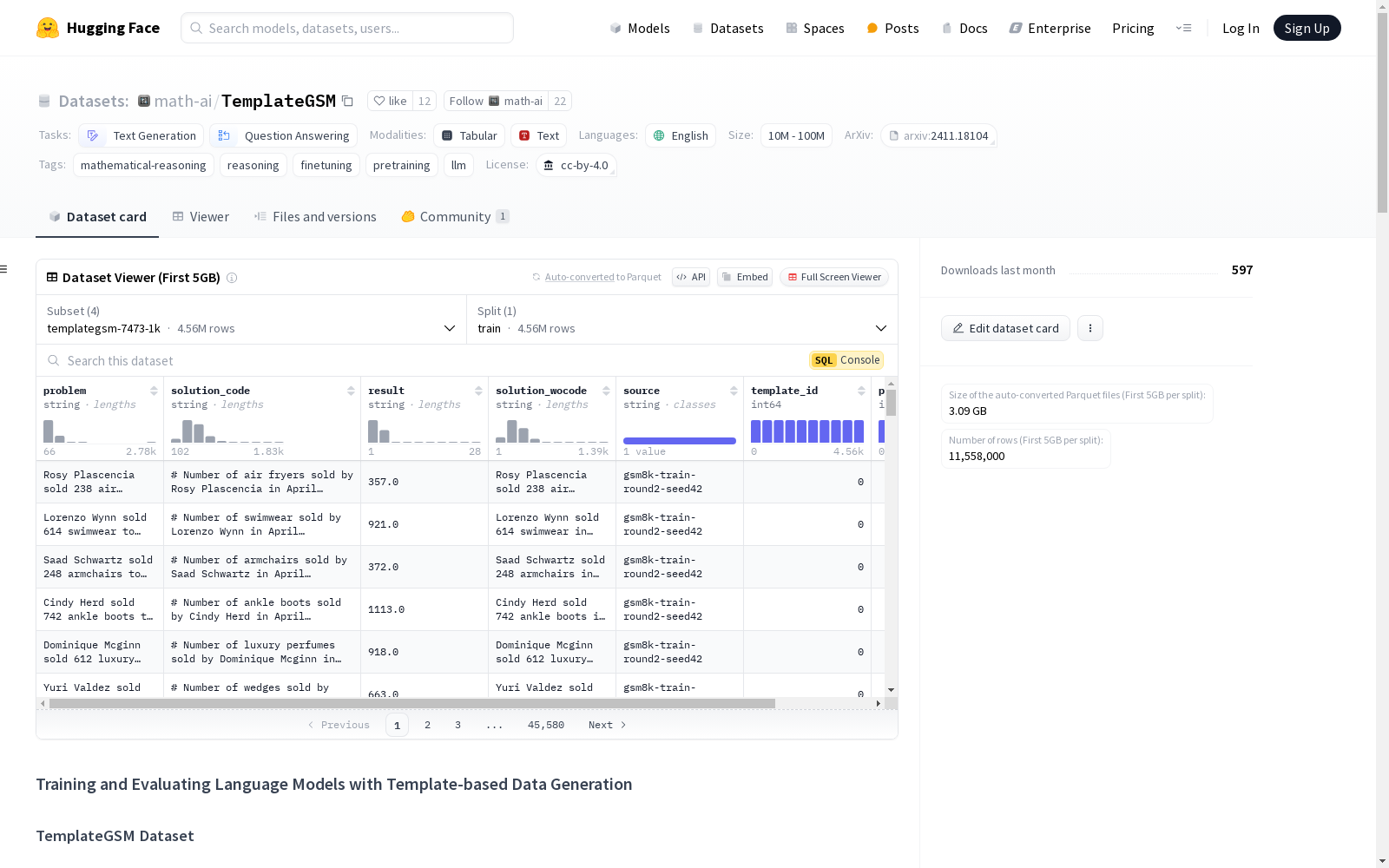
TemplateMath Part I: TemplateGSM是由清华大学IIIS实验室创建的一个大规模小学数学问题数据集。该数据集包含超过700万条合成生成的小学数学问题,每个问题都配有代码和自然语言的解决方案。数据集的创建过程利用了GPT-4生成的参数化模板,通过自动生成和验证确保了数据的高质量和多样性。该数据集主要用于预训练、微调和评估大型语言模型在数学推理任务中的表现,旨在解决现有数学数据集规模和多样性不足的问题。
TemplateMath Part I: TemplateGSM is a large-scale primary school mathematics problem dataset developed by the Institute for Interdisciplinary Information Sciences (IIIS) at Tsinghua University. This dataset contains over 7 million synthetically generated primary school math problems, each paired with both code-based and natural language solutions. The dataset construction process leverages parameterized templates generated by GPT-4, and ensures high data quality and diversity through automated generation and validation procedures. Primarily intended for pre-training, fine-tuning, and evaluating large language models (LLMs) on mathematical reasoning tasks, this dataset aims to address the limitations of existing math datasets in terms of scale and diversity.
提供机构:
清华大学
创建时间:
2024-11-27
搜集汇总
数据集介绍
构建方式
TemplateMath Part I: TemplateGSM数据集的构建基于Template-based Data Generation (TDG)方法,该方法利用GPT-4生成参数化的元模板,随后通过这些模板合成大量高质量的数学问题及其解决方案。具体而言,GPT-4首先生成涵盖多种数学问题类型的元模板,这些模板包含变量组件的占位符。接着,通过替换这些占位符中的参数,生成具体的数学问题和对应的代码及自然语言解决方案。生成的每对问题和解决方案都经过代码执行和语言模型验证,确保其正确性和可靠性。
特点
TemplateGSM数据集的显著特点在于其规模和多样性。该数据集包含超过700万个合成生成的数学问题,每个问题均配有代码和自然语言解决方案,覆盖了小学数学的广泛主题。通过GPT-4生成的元模板,确保了问题结构的多样性和语言表达的丰富性,从而提高了数据集的多样性和质量。此外,数据集的生成和验证过程集成在一个步骤中,确保了数据的高效性和准确性。
使用方法
TemplateGSM数据集可用于预训练、微调和评估大型语言模型在数学推理任务中的表现。研究人员和实践者可以通过访问https://huggingface.co/datasets/math-ai/TemplateGSM获取数据集,并通过https://github.com/iiis-ai/TemplateMath获取数据生成代码,以复现结果或扩展数据集。该数据集的广泛应用包括训练模型解决复杂的数学问题,提升模型的推理能力和问题解决能力。
背景与挑战
背景概述
随着大型语言模型(LLMs)如GPT-3、PaLM和Llama的迅速发展,自然语言处理领域经历了显著的变革,这些模型在语言理解和生成方面展示了卓越的能力。然而,这些模型在需要复杂推理的任务中,特别是在数学问题解决方面,表现往往不尽如人意。这主要归因于缺乏大规模、高质量的领域特定数据集,这些数据集对于训练复杂的推理能力至关重要。为了解决这一问题,清华大学IIIS的Yifan Zhang等人于2024年提出了基于模板的数据生成(TDG)方法,并创建了TemplateMath Part I: TemplateGSM数据集。该数据集包含超过700万个合成生成的数学问题,每个问题都附有代码和自然语言的解决方案,旨在缓解大规模数学数据集的稀缺问题,并为LLMs在数学推理中的预训练、微调和评估提供宝贵的资源。
当前挑战
TemplateGSM数据集的构建面临多重挑战。首先,生成高质量、多样化的数学问题需要复杂的模板设计和参数化,这依赖于GPT-4的高级语言理解和生成能力。其次,确保每个问题及其解决方案的正确性和可靠性是一个重大挑战,这需要通过代码执行和LLM验证的双重检查机制来实现。此外,尽管TDG方法能够生成几乎无限的数据,但如何避免模板偏差,确保生成的数学问题在结构和语言风格上与人类编写的问题相匹配,仍然是一个待解决的问题。最后,当前数据集主要集中在小学数学水平,如何扩展到更高层次的数学问题,需要进一步的模板设计和验证机制的优化。
常用场景
经典使用场景
TemplateMath Part I: TemplateGSM数据集的经典使用场景主要集中在预训练和微调大型语言模型(LLMs)以增强其在数学推理任务中的表现。通过提供超过700万个合成生成的数学问题及其对应的代码和自然语言解决方案,该数据集为模型提供了丰富的训练材料,使其能够在复杂的数学问题解决中展现出更高的准确性和鲁棒性。
解决学术问题
TemplateMath Part I: TemplateGSM数据集解决了大型语言模型在数学推理任务中面临的两个主要学术问题:数据稀缺性和数据质量问题。通过利用GPT-4生成参数化模板,该数据集不仅大幅增加了训练数据的规模,还通过代码执行和语言模型验证确保了数据的高质量,从而显著提升了模型在数学推理任务中的表现。
衍生相关工作
TemplateMath Part I: TemplateGSM数据集的发布催生了一系列相关研究工作,包括使用该数据集进行模型预训练和微调的研究,以及探索如何进一步扩展和优化数据生成方法的研究。此外,该数据集还激发了对多语言数学数据集生成和跨学科数据集整合的研究兴趣,推动了数学推理和自然语言处理领域的技术进步。
以上内容由遇见数据集搜集并总结生成


