sample-dataset-test-neural-pack
收藏Hugging Face2026-02-13 更新2026-02-14 收录
下载链接:
https://huggingface.co/datasets/Trelis/sample-dataset-test-neural-pack
下载链接
链接失效反馈官方服务:
资源简介:
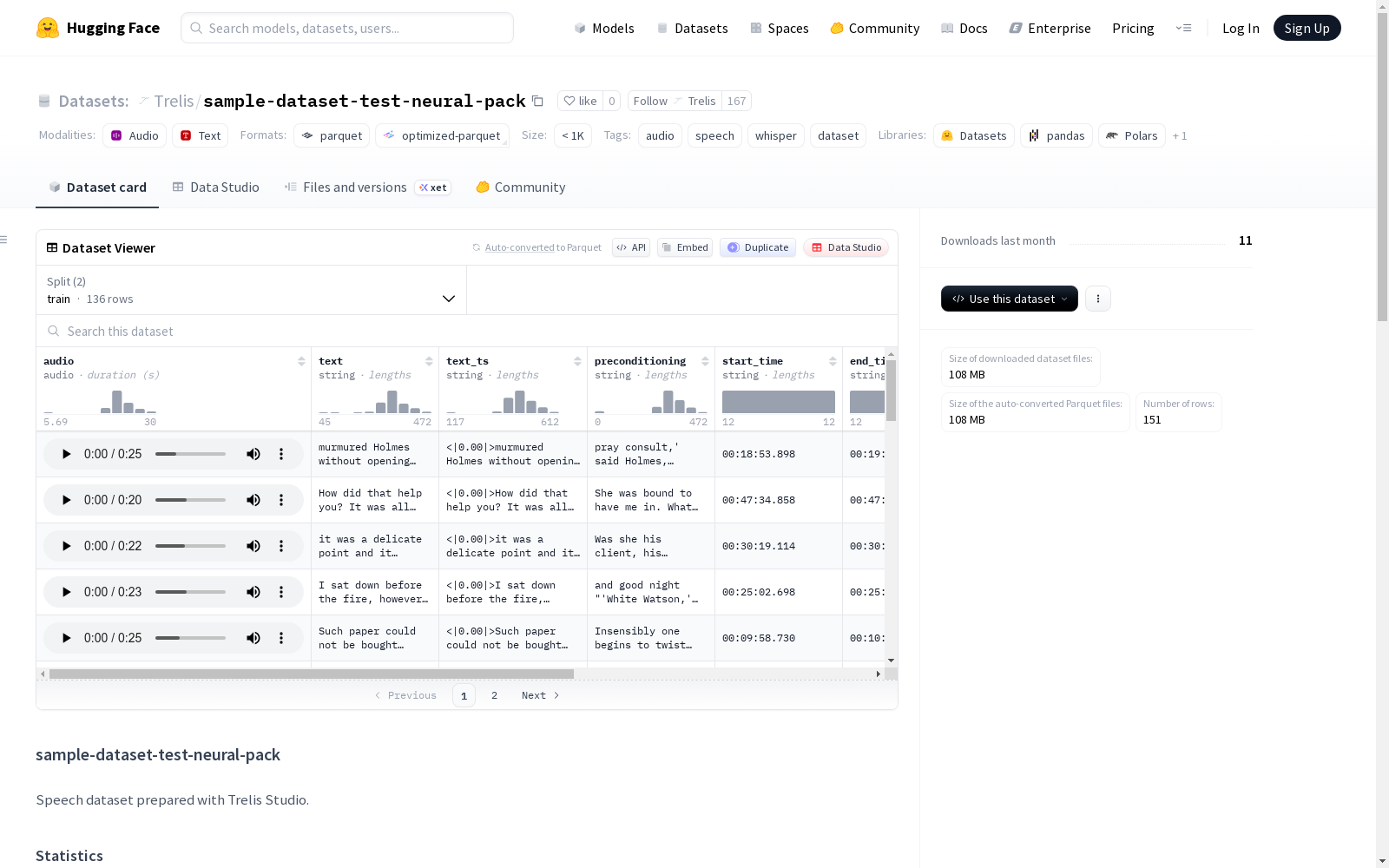
该数据集名为'sample-dataset-test-neural-pack',是一个专注于音频和语音处理的数据集,特别适用于whisper模型。数据集使用Trelis Studio准备,包含6个源文件,136个训练样本和15个验证样本,总时长为62.6分钟。数据集的主要字段包括:音频段(16kHz,仅语音,通过VAD去除静音)、纯文本转录(无时间戳)、带Whisper时间戳标记的转录、段落在原始音频中的开始和结束时间、语音持续时间(不包括静音)、词级时间戳(相对于仅语音的音频)以及原始音频文件名。数据集经过Silero VAD处理,确保训练数据与推理行为匹配。对于Whisper时间戳训练,建议使用两桶方法:50%使用纯文本转录,50%使用带时间戳标记的转录。
This dataset is named 'sample-dataset-test-neural-pack', a dataset focused on audio and speech processing specifically tailored for Whisper models. Prepared using Trelis Studio, it contains 6 source files, 136 training samples and 15 validation samples, with a total duration of 62.6 minutes. The core fields of the dataset include: audio segments (16kHz, speech-only, with silence removed via VAD), plain text transcriptions (without timestamps), transcriptions with Whisper timestamps, start and end timestamps of speech segments in the original audio, speech duration (excluding silence), word-level timestamps (relative to the speech-only audio), and the original audio filename. The dataset has been processed with Silero VAD to align the training data with inference behavior. For Whisper timestamp training, the two-bucket approach is recommended: 50% of the samples use plain text transcriptions, while the remaining 50% use transcriptions with timestamps.
提供机构:
Trelis创建时间:
2026-02-13
搜集汇总
数据集介绍
构建方式
在语音处理领域,高质量的数据集是模型训练的基础。该数据集通过Trelis Studio精心构建,原始音频文件经过Silero VAD技术处理,有效剔除了静音部分,仅保留纯净的语音片段。每个片段均以16kHz采样率存储,并配备了精细的文本标注,包括不含时间戳的普通转录文本以及嵌入了Whisper时间戳标记的详细转录。此外,数据构建过程还记录了每个片段的起止时间、语音时长、词级时间戳及源文件信息,确保了数据结构的完整性与一致性。
特点
该数据集在语音识别研究领域展现出鲜明的技术特色。其核心特征在于同时提供了两种转录文本格式,既包含向后兼容的纯文本转录,也集成了符合Whisper模型规范的时间戳标记文本,为模型训练提供了灵活的标注选择。数据经过严格的静音剥离处理,使音频内容与推理环境高度匹配,有效提升了训练数据的实用性。丰富的元数据,如词级时间戳和精确的片段时长,为深入研究语音时序对齐和细粒度分析提供了有力支持。
使用方法
为充分发挥该数据集在语音识别模型训练中的价值,研究者可通过Hugging Face的`datasets`库便捷加载。在具体应用时,建议采用双桶策略进行训练:将50%的数据使用不含时间戳的普通转录文本,另外50%则使用包含Whisper时间戳标记的文本。这种方法有助于模型同时学习准确的语音内容识别与精细的时间戳预测能力,从而适配更广泛的语音处理任务需求。
背景与挑战
背景概述
随着语音识别技术的快速发展,尤其是基于Transformer架构的模型如Whisper的出现,对高质量、精细标注的语音数据集需求日益增长。sample-dataset-test-neural-pack数据集由Trelis机构创建,旨在支持语音识别模型在转录准确性及时间戳预测方面的训练与评估。该数据集通过专业工具处理,剔除了静音部分,保留了纯语音片段,并提供了带时间戳的文本标注,核心研究问题聚焦于提升语音识别模型在实时转录与时间对齐方面的性能,对推动语音处理领域的模型优化与应用部署具有重要影响。
当前挑战
该数据集致力于解决语音识别领域中转录与时间戳同步的挑战,即如何准确预测语音内容及其对应的时间边界,这在实时字幕生成、音频分析等应用中至关重要。构建过程中,挑战包括通过VAD技术有效剥离静音以确保数据纯净性,同时维护时间戳在原始音频与处理后音频间的一致性,以及设计双桶训练策略以平衡带时间戳与不带时间戳样本的使用,从而模拟真实推理场景并提升模型泛化能力。
常用场景
经典使用场景
在语音处理领域,该数据集专为训练和评估Whisper模型而设计,尤其侧重于时间戳预测任务。通过提供包含纯文本转录和带时间戳标记的转录版本,它支持双桶训练策略,使模型能够同时学习语音识别和时间戳对齐。这种设计模拟了实际推理场景,其中语音活动检测已去除静默部分,从而提升了模型在连续语音流中定位词汇的精确性。数据集的小规模特性使其成为快速原型开发和算法验证的理想选择,为研究者提供了高效的实验平台。
解决学术问题
该数据集直接应对语音识别中时间戳预测的学术挑战,解决了传统方法在词汇级对齐上的不足。通过集成Whisper时间戳标记和词级时间戳注释,它促进了端到端模型的发展,这些模型能够同步输出转录文本及其时间位置。这不仅增强了语音识别的可解释性,还为音频内容分析、语音检索等任务提供了可靠的数据基础。其静默剥离处理确保了训练与推理的一致性,推动了语音处理技术向更精细化、实用化的方向演进。
衍生相关工作
围绕该数据集,衍生了一系列经典研究工作,主要集中在Whisper模型的扩展与优化上。例如,研究者利用其双桶训练策略开发了改进的时间戳预测算法,增强了模型对长音频的处理能力。此外,基于词级时间戳注释,出现了针对语音分割和说话人识别的混合方法。这些工作不仅推动了开源语音工具库(如Hugging Face Transformers)的更新,还促进了跨语言语音识别技术的发展,为后续大规模数据集的构建提供了方法论参考。
以上内容由遇见数据集搜集并总结生成


