MME-Emotion
收藏Hugging Face2026-01-17 更新2026-01-18 收录
下载链接:
https://huggingface.co/datasets/Karl28/MME-Emotion
下载链接
链接失效反馈官方服务:
资源简介:
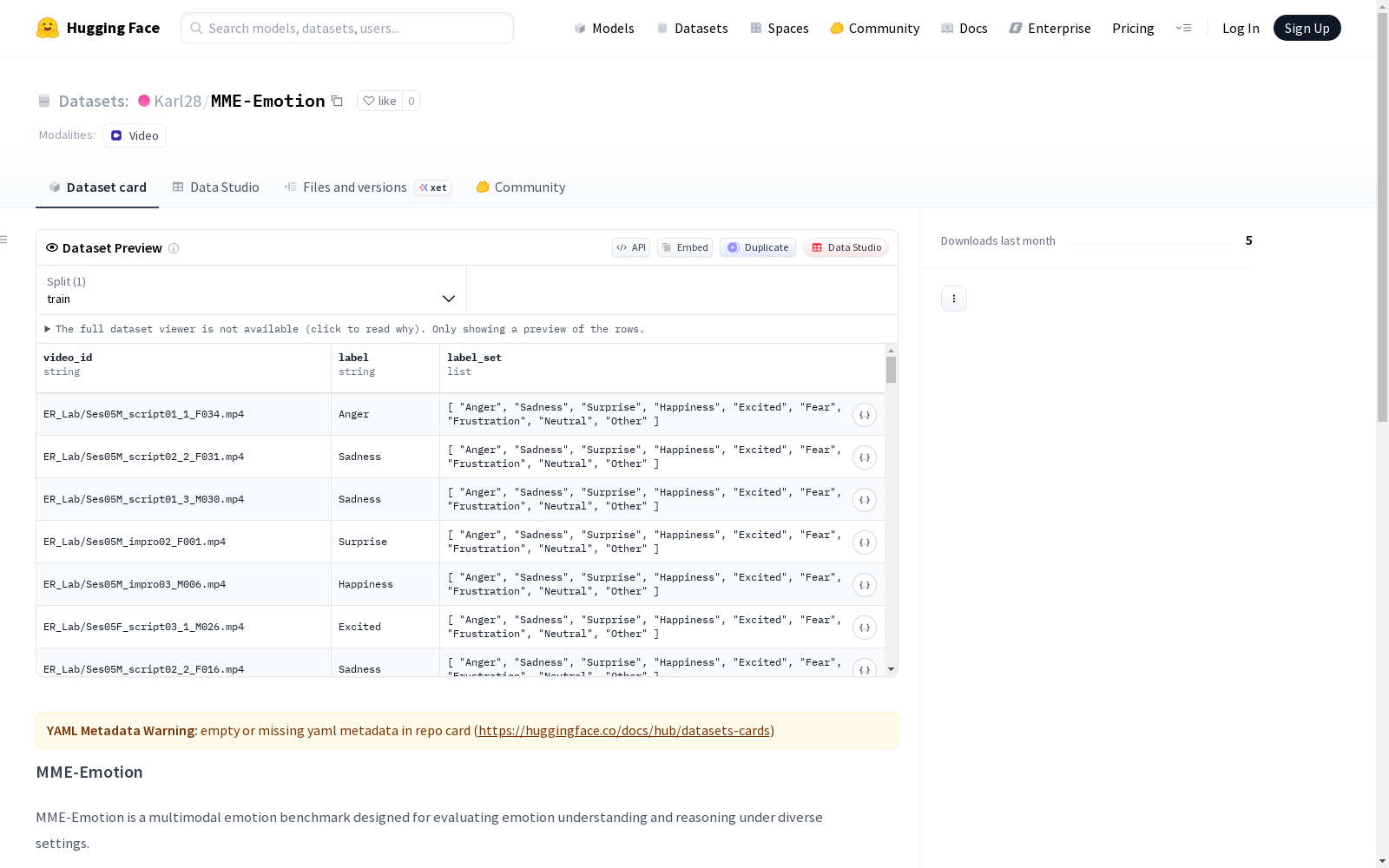
MME-Emotion是一个多模态情感基准数据集,旨在评估不同环境下的情感理解和推理能力。数据集包含多个子集,每个子集包括一个JSON注释文件和对应的视频剪辑ZIP存档。出于隐私考虑,原始视频仅以压缩形式分发。额外的音频解释在`audio_clue/`目录中提供。
MME-Emotion is a multimodal emotion benchmark dataset designed to evaluate emotion understanding and reasoning capabilities across various environments. The dataset comprises multiple subsets, each containing a JSON annotation file and a corresponding ZIP archive of video clips. For privacy considerations, the original videos are only distributed in compressed form. Additional audio explanations are provided in the `audio_clue/` directory.
创建时间:
2026-01-16
原始信息汇总
MME-Emotion 数据集概述
数据集简介
MME-Emotion 是一个多模态情感基准数据集,旨在评估多样化设置下的情感理解与推理能力。
数据内容
每个子集包含以下内容:
- 一个 JSON 格式的标注文件。
- 一个包含对应视频片段的 ZIP 压缩包。
出于隐私考虑,原始视频仅以压缩形式分发。
子集构成
数据集包含以下子集:
- ER_Lab / ER_Wild
- FG_ER / FG_SA
- IR
- ML_ER
- Noise_ER
- SA
附加资源
在 audio_clue/ 目录下提供了基于音频的解释。
使用示例
python import json from zipfile import ZipFile
with open("ER_Lab.json") as f: data = json.load(f)
video_id = data[0]["video_id"] # ER_Lab/xxx.mp4
搜集汇总
数据集介绍
构建方式
在情感计算与多模态人工智能的交叉领域,MME-Emotion数据集的构建体现了严谨的工程与学术考量。该数据集通过系统性地收集与标注多模态视频片段,构建了涵盖实验室环境与自然场景的多个子集,包括ER_Lab、ER_Wild、FG_ER等。原始视频出于隐私保护被压缩分发,并辅以结构化的JSON标注文件,确保了数据使用的合规性与便捷性。音频线索的单独提供进一步丰富了数据的模态层次,为深入的情感理解研究奠定了坚实基础。
使用方法
对于希望利用MME-Emotion的研究者而言,其使用流程清晰而高效。通过加载特定子集的JSON标注文件,研究者可以便捷地获取视频ID及对应的结构化情感标签。随后,从压缩包中提取相应视频文件,即可进行多模态特征提取与模型训练。数据集支持从基础的情感分类到复杂的多模态推理等一系列任务,其模块化设计允许用户灵活选择子集以适配不同的实验目标,为推进情感智能系统的能力边界提供了实用工具。
背景与挑战
背景概述
情感计算作为人工智能领域的重要分支,致力于使机器能够识别、理解和响应人类情感。MME-Emotion数据集由研究团队于近年创建,旨在构建一个多模态情感基准,以评估模型在多样化场景下的情感理解与推理能力。该数据集整合了视觉、听觉等多源信息,核心研究问题聚焦于跨模态情感表征的融合与解析,推动了情感智能系统向更自然、更鲁棒的方向发展,对人机交互、心理健康监测等应用产生了深远影响。
当前挑战
在情感计算领域,准确捕捉并解释人类情感的细微变化与上下文依赖性始终是核心难题,MME-Emotion所针对的多模态情感识别任务需克服模态间信息对齐与语义鸿沟等挑战。数据构建过程中,研究团队面临隐私保护约束下原始视频数据的合规处理、多样化场景(如实验室与野外环境)中情感标注的一致性维护,以及噪声环境下情感信号的有效提取等实际困难,这些因素共同增加了数据集构建的复杂度与严谨性要求。
常用场景
经典使用场景
在情感计算领域,MME-Emotion数据集为多模态情感理解提供了基准测试平台。其经典使用场景集中于评估模型在实验室环境与野外场景下的情感识别与推理能力,通过整合视觉、音频及文本注释,支持研究者系统分析情绪表达的复杂动态。该数据集常用于训练和验证跨模态融合算法,以提升机器对非语言线索如面部表情、语音语调的解析精度,推动情感智能向更自然的人机交互迈进。
解决学术问题
MME-Emotion有效解决了多模态情感分析中的关键学术问题,包括如何统一处理异构数据源以增强情绪分类的鲁棒性,以及如何在噪声干扰下保持推理的稳定性。数据集通过细分子集如FG_SA(细粒度情感分析)和Noise_ER(噪声环境情感识别),为研究情绪表达的细微差异和现实世界干扰因素提供了结构化资源,促进了情感计算理论框架的完善,并助力于开发更具适应性的机器学习模型。
实际应用
在实际应用中,MME-Emotion数据集被广泛部署于智能客服、心理健康监测及娱乐内容推荐系统。例如,在客户服务场景中,基于该数据集的模型可实时分析用户视频对话中的情绪变化,优化服务响应策略;在医疗领域,它辅助开发工具以识别抑郁或焦虑迹象,提升早期干预效率。这些应用不仅增强了技术的实用性,还为社会福祉带来了积极影响。
数据集最近研究
最新研究方向
在情感计算领域,多模态情感理解正成为人机交互与心理健康监测的前沿焦点。MME-Emotion数据集凭借其涵盖实验室与野外环境、融合视觉、音频及文本线索的多元结构,为情感识别模型的鲁棒性与泛化能力评估提供了关键基准。当前研究热点集中于跨场景情感推理、噪声环境下的稳健性分析,以及细粒度情感属性与情境感知的融合建模,这些方向不仅推动了多模态大模型在情感智能方面的发展,也为自闭症辅助诊断、情感化机器人等实际应用奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


