multimodal-rewardbench-2
收藏Hugging Face2025-12-20 更新2025-12-21 收录
下载链接:
https://huggingface.co/datasets/rl-research/multimodal-rewardbench-2
下载链接
链接失效反馈官方服务:
资源简介:
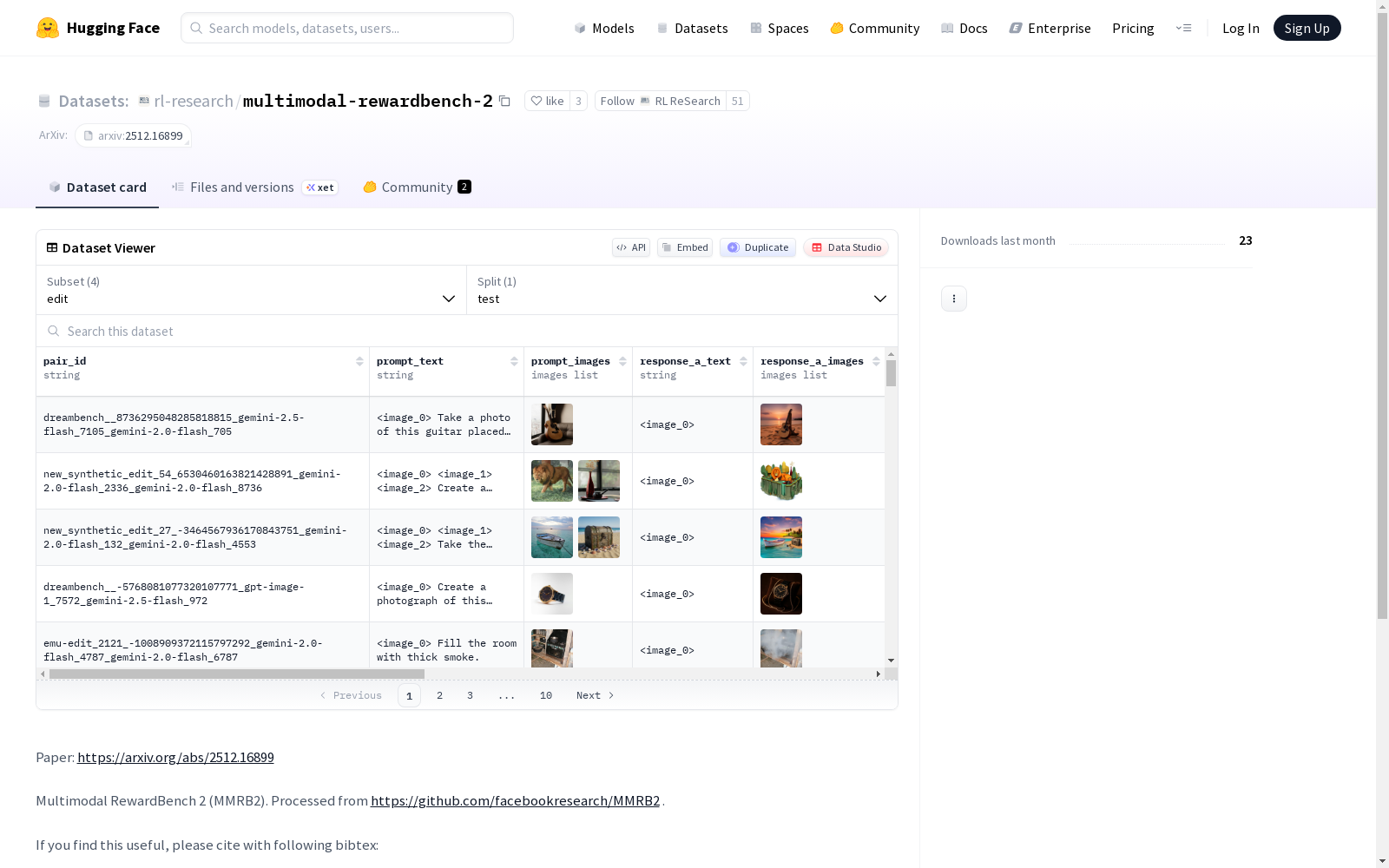
多模态奖励基准2(MMRB2)是一个用于评估交错文本和图像的全能奖励模型的数据集。该数据集包含多个配置,如编辑、交错、推理和文本到图像(t2i),每个配置都有测试分割,包含1000个示例。数据集的特征包括配对ID、提示文本、提示图像、响应文本、响应图像、选择结果、提示来源、响应模型、人类注释和提示元数据。该数据集是从GitHub仓库处理而来,旨在支持相关研究。
Multimodal Reward Benchmark 2 (MMRB2) is a dataset developed for evaluating general-purpose reward models that handle interleaved text and image inputs. This dataset encompasses multiple configurations, including editing, interleaved, reasoning, and text-to-image (t2i), each of which has a test split consisting of 1000 examples. The features of this dataset cover pair ID, prompt text, prompt image, response text, response image, selection result, prompt source, response model, human annotations, and prompt metadata. This dataset is curated from a GitHub repository and is intended to support relevant research.
创建时间:
2025-12-19
原始信息汇总
数据集概述
基本信息
- 数据集名称:Multimodal RewardBench 2 (MMRB2)
- 数据集地址:https://huggingface.co/datasets/rl-research/multimodal-rewardbench-2
- 相关论文:https://arxiv.org/abs/2512.16899
- 数据来源:处理自 https://github.com/facebookresearch/MMRB2
数据集配置
数据集包含四个独立的配置(config),每个配置对应一个测试集(test split),各有1000个样本。
1. 配置:edit
- 数据文件路径:edit/test-*
- 数据集大小:929,053,437 字节
- 下载大小:927,657,981 字节
2. 配置:interleaved
- 数据文件路径:interleaved/test-*
- 数据集大小:1,652,152,157 字节
- 下载大小:1,648,237,636 字节
3. 配置:reasoning
- 数据文件路径:reasoning/test-*
- 数据集大小:533,076,674 字节
- 下载大小:522,037,553 字节
4. 配置:t2i
- 数据文件路径:t2i/test-*
- 数据集大小:679,486,589 字节
- 下载大小:679,141,219 字节
数据特征
所有配置共享相同的特征结构(features):
pair_id:字符串类型prompt_text:字符串类型prompt_images:图像列表response_a_text:字符串类型response_a_images:图像列表response_b_text:字符串类型response_b_images:图像列表chosen:字符串类型prompt_source:字符串类型response_a_model:字符串类型response_b_model:字符串类型human_annotations:字符串类型prompt_metadata:字符串类型
引用信息
如果使用本数据集,请引用以下文献: bibtex @article{hu2025multimodalrewardbench2, title={Multimodal RewardBench 2: Evaluating Omni Reward Models for Interleaved Text and Image}, author={Hu, Yushi and Askari-Hemmat, Reyhane and Hall, Melissa and Dinan, Emily and Zettlemoyer, Luke and Ghazvininejad, Marjan}, journal={arXiv preprint arXiv:2512.16899}, year={2025} }
搜集汇总
数据集介绍
构建方式
在评估多模态奖励模型性能的背景下,Multimodal RewardBench 2数据集通过精心设计的流程构建而成。该数据集从公开的MMRB2资源中提取并处理,涵盖了编辑、交错、推理和文本到图像生成四个关键配置。每个配置均包含一千个测试样本,样本结构统一,包含提示文本与图像、两种模型生成的响应文本与图像,以及人工标注的偏好选择。构建过程注重数据的多样性与平衡性,确保每个配置独立反映特定多模态任务中的模型表现差异。
特点
该数据集的核心特征在于其全面的多模态评估框架,专门针对交错文本与图像的复杂场景设计。数据集划分为四个具有针对性的配置:编辑配置侧重于图像修改任务,交错配置处理文本与图像交替生成的内容,推理配置考察多模态逻辑分析能力,而文本到图像配置则专注于生成质量评估。每个样本均提供了详细的元数据,包括提示来源、生成模型信息和人工标注结果,为深入分析奖励模型的偏好对齐与泛化能力提供了结构化基础。
使用方法
研究人员可利用该数据集系统评估多模态奖励模型在不同任务上的性能。通过加载指定的配置(如edit、interleaved、reasoning或t2i),可以访问对应的测试分割,其中包含配对的多模态提示与响应。典型的使用方式涉及计算奖励模型对样本中两个响应的偏好评分,并与人工标注的chosen标签进行比较,从而量化模型与人类偏好的一致性。数据集中提供的prompt_metadata和human_annotations字段支持细粒度的错误分析与跨配置的泛化研究,助力多模态对齐技术的迭代与优化。
背景与挑战
背景概述
随着多模态人工智能技术的迅猛发展,评估模型在交织文本与图像任务中的表现成为关键研究课题。Multimodal RewardBench 2(MMRB2)数据集于2025年由Meta AI等机构的研究团队创建,旨在系统评估全能奖励模型在编辑、交织、推理及文本到图像生成等多模态场景下的性能。该数据集通过精心设计的提示与响应配对,结合人类标注的偏好选择,为核心研究问题——即如何准确量化多模态交互中的模型输出质量——提供了标准化基准,对推动多模态对齐与强化学习领域的发展具有重要影响力。
当前挑战
该数据集致力于解决多模态奖励模型评估中的核心挑战,即如何在不同模态交织的复杂任务中,如编辑、推理和图像生成,建立统一且可靠的性能度量标准。构建过程中的挑战主要体现在数据收集与标注的复杂性上,需要确保提示与响应在文本和图像模态上的高质量对齐,同时克服人类标注者在多模态偏好判断中可能存在的歧义与主观偏差,以维持数据的一致性与客观性。
常用场景
经典使用场景
在评估多模态奖励模型的性能时,Multimodal RewardBench 2数据集扮演着基准测试的核心角色。该数据集通过编辑、交错、推理和文本到图像生成等多样化配置,为研究者提供了标准化的评估框架。经典使用场景涉及将不同多模态模型对同一提示生成的两个响应进行对比,依据人类标注的偏好数据,系统性地衡量模型在图文混合任务中的输出质量与对齐程度。
解决学术问题
该数据集有效解决了多模态人工智能领域中对奖励模型进行可靠、全面评估的学术难题。它通过构建大规模、高质量的人类偏好标注对,为量化模型在复杂跨模态交互中的表现提供了实证基础。其意义在于推动了奖励模型从单一模态向图文交织场景的扩展,促进了对齐研究从纯文本向多模态环境的范式迁移,为开发更安全、更可控的多模态系统奠定了评估标准。
衍生相关工作
围绕该数据集,学术界衍生出一系列专注于提升多模态奖励模型性能的经典研究工作。这些工作通常借鉴其评估框架,开发新的模型架构或训练算法,以在编辑、交错推理等子任务上取得更优的评分。同时,该数据集也常被用作基准,用于比较不同多模态对齐方法的有效性,推动了如指令跟随、价值观对齐等技术在多模态语境下的深入发展与迭代。
以上内容由遇见数据集搜集并总结生成


