NathanGavenski/CartPole-v1
收藏CartPole-v1 - Imitation Learning Datasets
描述
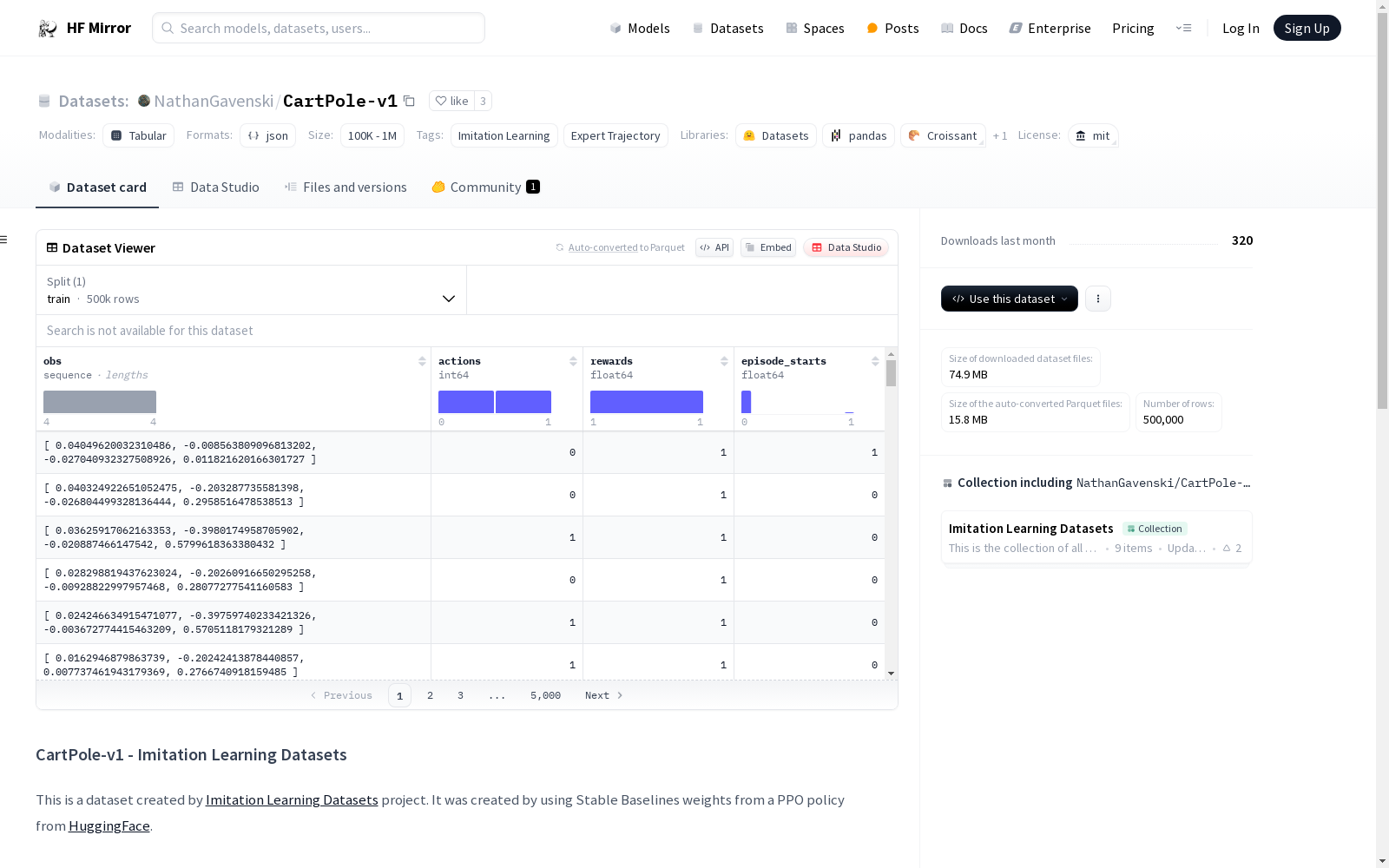
该数据集包含1,000个回合,平均回合奖励为500。每个条目包含以下内容:
obs(列表): 长度为4的观察值。action(整数): 动作(0或1)。reward(浮点数): 该时间步的奖励点。episode_returns(布尔值): 该状态是否为回合的初始时间步。
使用
可以自由下载并使用teacher.jsonl数据集。如果对使用PyTorch数据集实现感兴趣,可以查看IL Datasets项目。该项目实现了一个基础数据集,可以直接从HuggingFace下载此数据集及其他所有数据集。基础数据集还允许对训练和测试拆分进行更多控制,以及选择使用多少个回合(在不需要1,000个回合的情况下)。
引用
bibtex @inproceedings{gavenski2024ildatasets, author = {Gavenski, Nathan and Luck, Michael and Rodrigues, Odinaldo}, title = {Imitation Learning Datasets: A Toolkit For Creating Datasets, Training Agents and Benchmarking}, year = {2024}, isbn = {9798400704864}, publisher = {International Foundation for Autonomous Agents and Multiagent Systems}, address = {Richland, SC}, abstract = {Imitation learning field requires expert data to train agents in a task. Most often, this learning approach suffers from the absence of available data, which results in techniques being tested on its dataset. Creating datasets is a cumbersome process requiring researchers to train expert agents from scratch, record their interactions and test each benchmark method with newly created data. Moreover, creating new datasets for each new technique results in a lack of consistency in the evaluation process since each dataset can drastically vary in state and action distribution. In response, this work aims to address these issues by creating Imitation Learning Datasets, a toolkit that allows for: (i) curated expert policies with multithreaded support for faster dataset creation; (ii) readily available datasets and techniques with precise measurements; and (iii) sharing implementations of common imitation learning techniques. Demonstration link: https://nathangavenski.github.io/#/il-datasets-video}, booktitle = {Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems}, pages = {2800–2802}, numpages = {3}, keywords = {benchmarking, dataset, imitation learning}, location = {<conf-loc>, <city>Auckland</city>, <country>New Zealand</country>, </conf-loc>}, series = {AAMAS 24} }