ravenea
收藏Hugging Face2025-05-16 更新2025-05-17 收录
下载链接:
https://huggingface.co/datasets/jaagli/ravenea
下载链接
链接失效反馈官方服务:
资源简介:
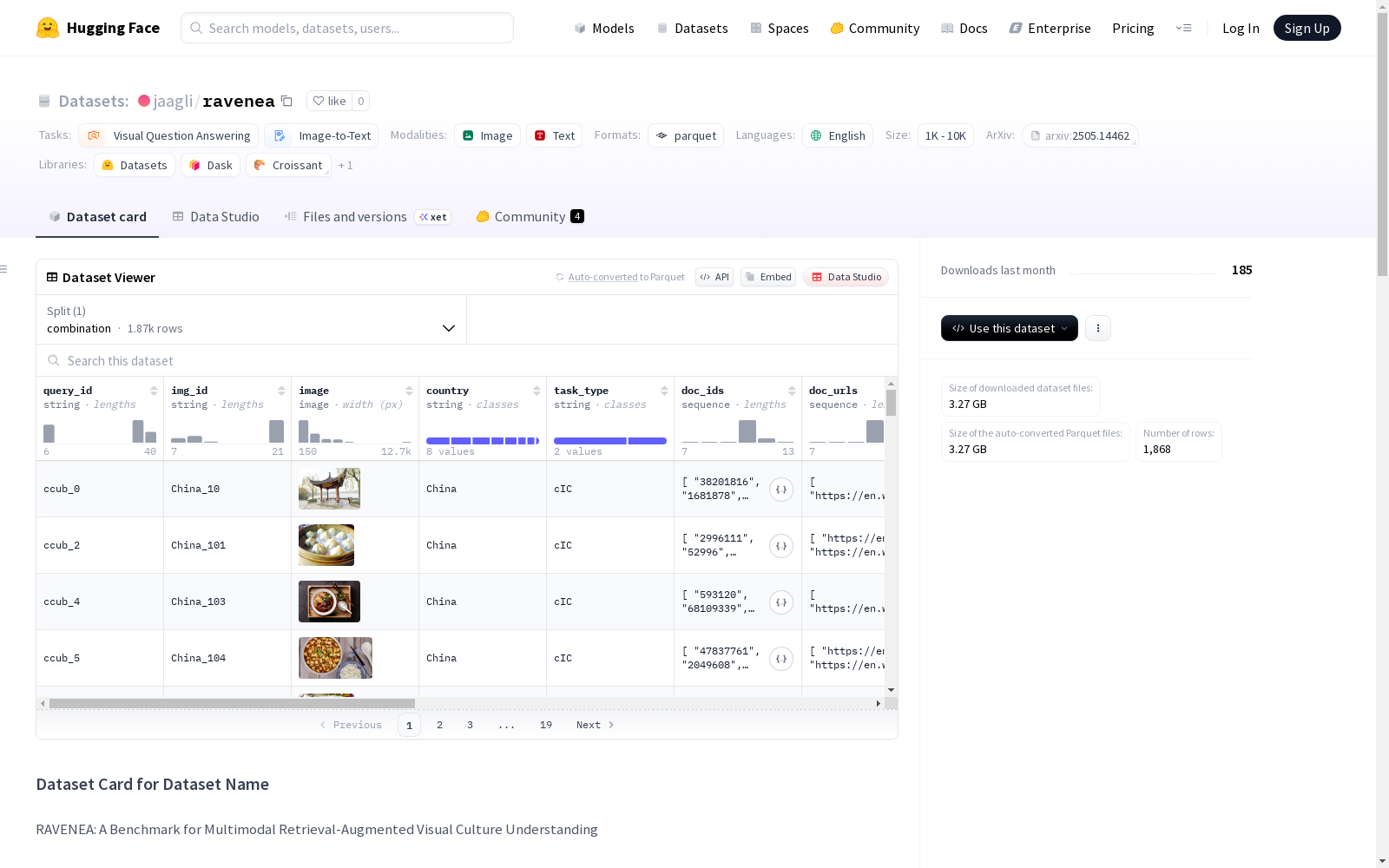
该数据集包含多个字段,如查询ID、图片ID、图片、国家、任务类型、文档ID列表、文档URL列表、文化相关性得分、问题、选项、答案和人类编写的标题。数据集被分割为一个名为'combination'的组合集,包含1868个样本,整个数据集的大小为3,271,632,733.292字节。数据集的具体用途和背景在README文件中未明确说明。
This dataset contains multiple fields, including query ID, image ID, image, country, task type, list of document IDs, list of document URLs, cultural relevance score, question, options, answer, and human-written caption. The dataset is partitioned into a combined subset named 'combination', which comprises 1,868 samples. The total size of the entire dataset is 3,271,632,733.292 bytes. The specific usage and background of this dataset are not clearly specified in the README file.
创建时间:
2025-05-10
搜集汇总
数据集介绍
构建方式
在跨文化视觉理解研究领域,RAVENEA数据集的构建采用了多源融合策略,整合了来自维基百科知识库的逾万篇人文地理文档,并辅以CVQA和CCUB两大视觉文化数据集的标注资源。构建过程中通过人工专家对文档进行文化相关性标注,形成具有层次结构的文化知识索引体系。该数据集采用严格的跨模态对齐机制,确保每幅图像与对应的文化背景描述、问题答案对及人工撰写的文化感知标题形成有机关联,最终构建出包含1868个样本的多模态文化理解基准。
特点
该数据集最显著的特征在于其多维度的文化表征能力,不仅包含常规的视觉问答要素,更创新性地引入了文化相关性评分体系与结构化知识文档索引。数据样本覆盖建筑、民俗等多元文化场景,每个样本均配备经过人工校验的文化背景说明和跨语言知识链接。其独特的检索增强架构使模型能够动态调用外部文化知识库,为视觉语言模型提供了从表层特征识别到深层文化语义理解的完整演进路径。
使用方法
研究者可通过HuggingFace标准接口直接加载数据集,使用load_dataset函数指定'jaagli/ravenea'路径即可获取全部1868个样本。该数据集支持文化导向的视觉问答与文化感知图像描述两大核心任务,用户可依据task_type字段区分任务类型,通过doc_urls字段访问关联的文化知识文档。在模型训练过程中,建议结合culture_relevance_scores字段实现知识检索的加权优化,利用human_captions字段作为文化描述生成的监督信号,从而全面提升模型的文化认知能力。
背景与挑战
背景概述
视觉文化理解作为多模态人工智能研究的前沿领域,旨在探索视觉内容与特定文化背景之间的深层关联。RAVENEA基准数据集由Jiaang Li等研究人员于2025年联合创建,其核心研究聚焦于通过检索增强方法提升视觉语言模型的文化认知能力。该数据集整合了来自维基百科的逾万篇人工标注文档,构建了文化导向的视觉问答与文化感知图像描述两大任务范式,为跨文化视觉理解研究提供了系统化评估框架,显著推动了多模态人工智能在文化敏感性方面的发展进程。
当前挑战
在视觉文化理解领域,模型需克服文化符号的多样性与语境依赖性挑战,RAVENEA针对性地解决了文化特征与视觉内容的对齐难题。数据集构建过程中面临三重挑战:其一是文化相关文档的筛选与质量把控,需要人工标注者精准评估文档与图像的文化关联度;其二是多源数据融合的技术瓶颈,需协调维基百科、CVQA和CCUB等异构数据的标准化处理;其三是文化相关性评分的量化定义,要求建立细粒度的评分体系以准确反映文化元素的语义层次。
常用场景
经典使用场景
在跨文化视觉理解研究中,RAVENEA数据集被广泛用于评估和提升视觉语言模型的文化感知能力。其核心任务包括文化导向的视觉问答与文化感知图像描述生成,通过整合逾万篇人工标注的维基百科文档,模型需在理解图像内容基础上结合文化背景知识进行推理。这一设计有效模拟了真实世界中文化因素对视觉内容解读的影响,为多模态智能系统提供了标准化的测试平台。
衍生相关工作
基于该数据集已衍生出多项创新研究,如跨模态文化嵌入对齐算法和动态检索增强架构。这些工作通过改进文档检索策略与视觉特征融合方式,显著提升了文化问答任务的准确率。部分研究进一步探索了多语言文化知识的迁移学习,为构建面向低资源文化的视觉理解模型提供了重要技术路径。
数据集最近研究
最新研究方向
在跨模态文化理解领域,RAVENEA数据集正推动检索增强视觉文化理解的前沿探索。该数据集通过整合逾万篇人工标注的维基百科文档,聚焦文化导向的视觉问答与文化感知图像描述两大任务,为视觉语言模型注入深层次文化语境。当前研究热点集中于如何利用多模态检索机制增强模型对建筑、习俗等文化符号的语义解析能力,同时探索跨国家文化差异对模型泛化性的影响。这一方向不仅弥补了传统视觉任务中文化维度缺失的短板,更为构建具有文化敏感性的通用人工智能奠定了评估基准。
以上内容由遇见数据集搜集并总结生成


