HumanML3D 和 Motion-X
收藏arXiv2025-03-24 更新2025-03-26 收录
下载链接:
https://www.pinlab.org/hmu
下载链接
链接失效反馈官方服务:
资源简介:
HumanML3D是一个包含丰富运动捕获数据的大型数据集,包含如打斗等危险行为动作;Motion-X包含来自现实世界和动画场景的数据,也包括有害动作。两个数据集都被用来创建第一个针对人类运动遗忘任务的基准,通过过滤掉有毒内容,用于安全、道德的运动生成。
HumanML3D is a large-scale dataset with rich motion capture data, including dangerous behaviors such as fighting. Motion-X contains data from both real-world and animated scenarios, and also encompasses harmful actions. Both datasets are employed to establish the first benchmark for the human motion forgetting task, while toxic content is filtered out to facilitate safe and ethical motion generation.
提供机构:
罗马大学
创建时间:
2025-03-24
搜集汇总
数据集介绍
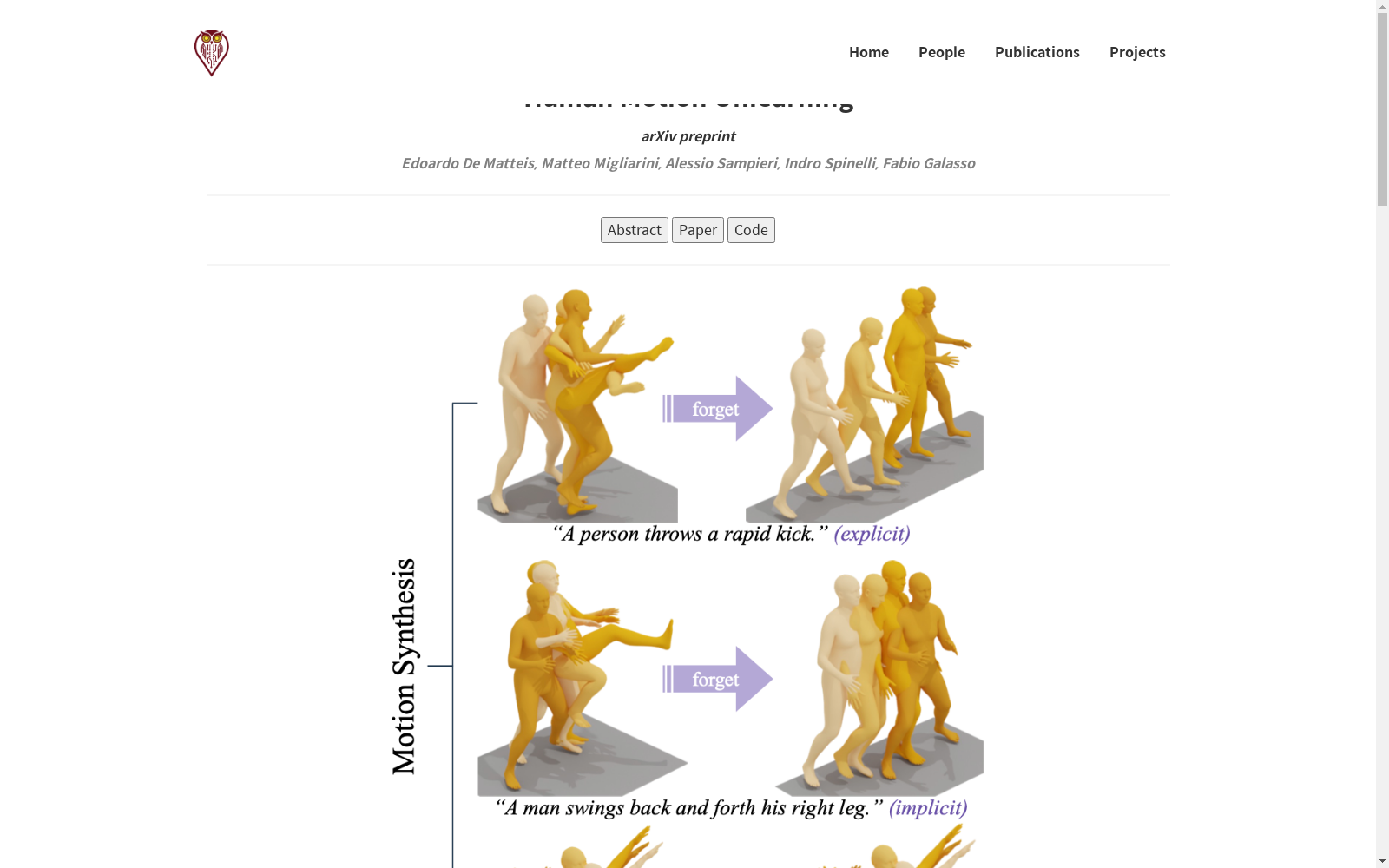
构建方式
HumanML3D和Motion-X数据集通过从大规模文本到动作数据集中筛选有害动作构建而成。研究团队首先定义了一组有害关键词,并将包含这些关键词的文本-动作对归类为遗忘集(Df),其余则归为保留集(Dr)。具体而言,HumanML3D包含14.6k个动作序列和44.9k条文本描述,其中7.7%的动作被标记为有害;Motion-X则包含81k个文本-动作对,有害动作占比达14.9%。数据预处理阶段采用语义角色标注(SRL)工具统一文本格式,并通过SMPL-X到SMPL的转换实现动作表征标准化。
特点
该数据集的核心特点体现在时空维度的毒性标注上。HumanML3D中暴力动作主要集中于踢腿(3.4%)和拳击(1.7%),而Motion-X则包含更复杂的危险行为如武器使用(5%)和武术动作。值得注意的是,毒性不仅存在于显式文本描述中,还可能通过安全动作的隐式组合产生(如"后摆腿前踢"构成踢击动作)。数据集创新性地引入多模态毒性距离(MM-Notox)指标,通过计算去毒化文本与生成动作的L2距离,量化模型对有害概念的遗忘效果。
使用方法
使用该数据集需分三个阶段:首先利用VQ-VAE将动作编码为离散潜空间标记,其中MoMask采用运动掩码策略,BAMM使用双向掩码变换器。评估时采用四类指标:基于FID的动作分布相似度、R-Precision的文本-动作对齐度、Diversity的生成多样性以及MultiModality的单文本多动作生成能力。特别地,对遗忘集的测试需结合显式和隐式毒性提示,例如同时检测"挥拳"和"手臂后摆前挥"的生成结果。实验表明,提出的潜代码替换(LCR)方法在HumanML3D上可使FID降低至9.712,较基线提升47.8%。
背景与挑战
背景概述
HumanML3D和Motion-X是两个专注于文本到动作生成(Text-to-Motion, T2M)的大规模数据集,由意大利罗马萨皮恩扎大学和ItalAI的研究团队于2023年至2024年间开发。这些数据集旨在解决动作合成领域中安全与伦理生成的核心问题,通过提供丰富的动作捕捉数据和详细的文本描述,支持生成模型在虚拟现实和动画等应用中的开发。HumanML3D包含14.6k动作序列和44.9k文本描述,而Motion-X则进一步扩展至81k动作-文本对,覆盖了更广泛的真实世界和动画场景。这些数据集的发布显著推动了动作合成技术的发展,同时也引发了关于生成内容安全性的重要讨论。
当前挑战
HumanML3D和Motion-X面临的挑战主要包括两个方面:领域问题的挑战和构建过程中的挑战。在领域问题方面,数据集需解决动作合成中的安全与伦理问题,例如避免生成暴力或不道德的动作(如踢打、使用武器等),这些动作可能通过显式或隐式的文本提示被模型合成。构建过程中的挑战包括数据清洗的复杂性,即从大规模数据中准确识别和过滤有害动作,同时保持数据的多样性和实用性。此外,动作的时空特性增加了识别和处理的难度,因为有害动作可能由一系列看似安全的动作组合而成。这些挑战要求开发者在数据标注、模型训练和评估中采用创新的方法,以确保生成内容的安全性和质量。
常用场景
经典使用场景
HumanML3D和Motion-X数据集在文本到动作生成领域具有广泛的应用。这些数据集通过提供丰富的动作捕捉数据和详细的文本描述,使得研究人员能够训练和评估生成模型,从而生成与文本描述相匹配的自然人体动作。特别是在虚拟现实、动画制作和人机交互等领域,这些数据集为生成高质量、多样化的动作序列提供了重要支持。
衍生相关工作
基于HumanML3D和Motion-X数据集,研究人员提出了多项经典工作。例如,MoMask和BAMM模型利用这些数据集的离散潜空间表示,实现了高质量的文本到动作生成。此外,Latent Code Replacement (LCR)方法通过操作潜空间中的代码本,有效去除了有害动作,同时保持了生成质量。这些工作不仅推动了文本到动作生成技术的发展,还为视频生成和机器遗忘等新兴领域提供了重要参考。
数据集最近研究
最新研究方向
随着生成式模型在文本到动作合成领域的快速发展,HumanML3D和Motion-X数据集的安全性和伦理问题日益凸显。近期研究聚焦于动作遗忘技术,旨在消除模型生成有害动作的能力,同时保持其整体性能。例如,通过潜在代码替换(LCR)等创新方法,研究者能够在无需重新训练的情况下,有效过滤暴力、自残等不当动作。这一方向不仅解决了数据集中隐含的毒性组合问题,还为虚拟现实、动画制作等应用提供了更安全的生成方案,标志着文本到动作合成领域向负责任AI发展的重要一步。
相关研究论文
- 1Human Motion Unlearning罗马大学 · 2025年
以上内容由遇见数据集搜集并总结生成


