Saibo-creator/wiki-nre
收藏Hugging Face2024-04-12 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/Saibo-creator/wiki-nre
下载链接
链接失效反馈官方服务:
资源简介:
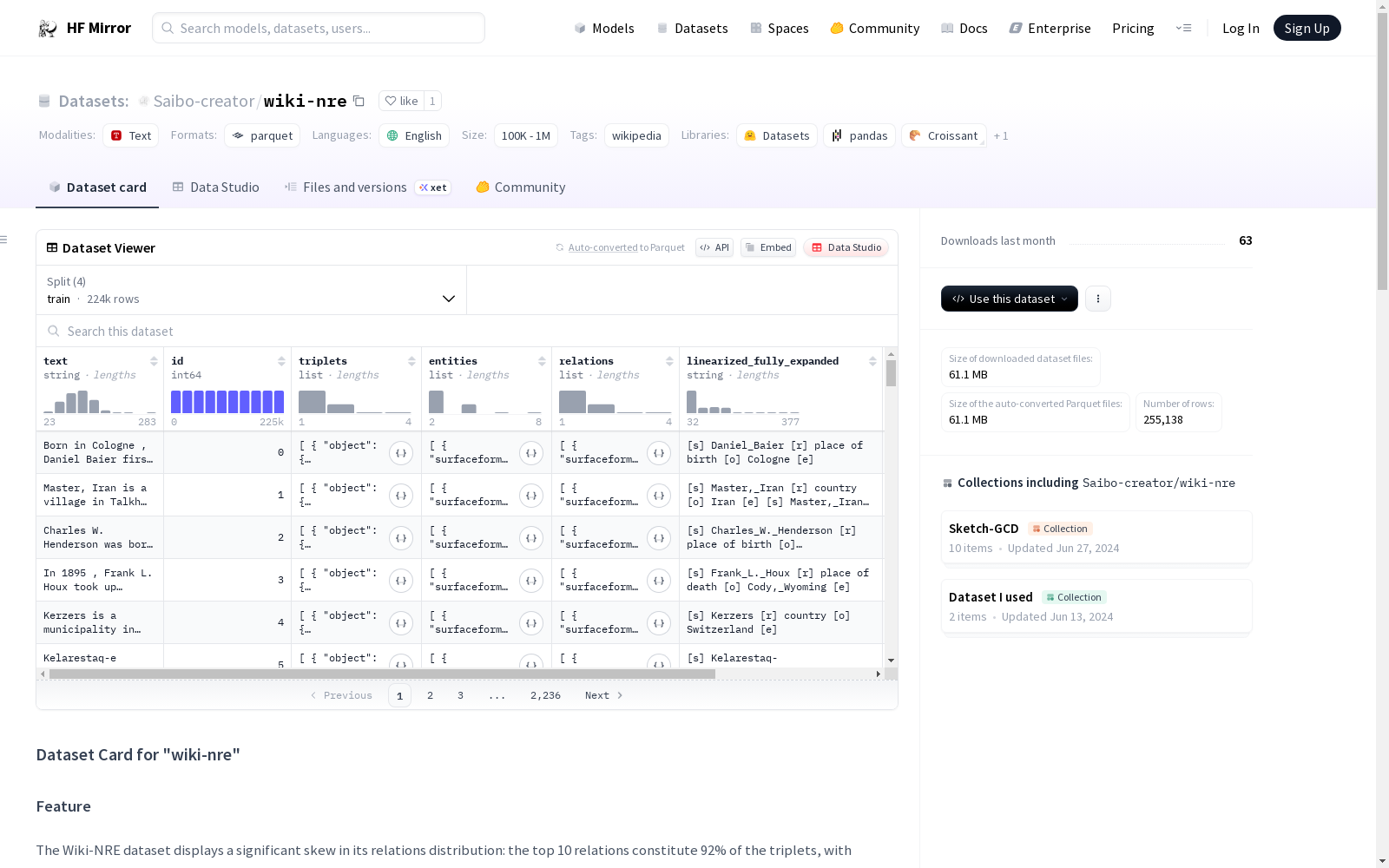
Wiki-NRE数据集展示了其关系分布的显著偏斜:前10个关系构成了92%的三元组,其中前3个关系单独占69%。我们创建了`stratified_test_1K`,它是从测试集中缩减到1,000个样本,并具有平衡的关系分布。
Wiki-NRE数据集展示了其关系分布的显著偏斜:前10个关系构成了92%的三元组,其中前3个关系单独占69%。我们创建了`stratified_test_1K`,它是从测试集中缩减到1,000个样本,并具有平衡的关系分布。
提供机构:
Saibo-creator
原始信息汇总
数据集概述
基本信息
- 语言: 英语(en)
- 大小: 10万至100万条记录
数据集特征
- text: 字符串类型
- id: 整数类型(int64)
- triplets: 列表类型,包含以下结构:
- object:
- surfaceform: 字符串类型
- uri: 字符串类型
- predicate:
- surfaceform: 字符串类型
- uri: 字符串类型
- subject:
- surfaceform: 字符串类型
- uri: 字符串类型
- object:
- entities: 列表类型,包含以下结构:
- surfaceform: 字符串类型
- uri: 字符串类型
- relations: 列表类型,包含以下结构:
- surfaceform: 字符串类型
- uri: 字符串类型
- linearized_fully_expanded: 字符串类型
- linearized_subject_collapsed: 字符串类型
数据分割
- train: 223,538条记录,117,206,023字节
- test: 29,620条记录,15,597,162字节
- stratified_test_1K: 1,000条记录,608,393字节
- val: 980条记录,522,524字节
下载与数据集大小
- 下载大小: 61,105,204字节
- 数据集大小: 133,934,102字节
数据集特性
- 关系分布显著倾斜:前10个关系占92%,前3个占69%。
- 创建了
stratified_test_1K,从测试集中抽取1,000个样本,关系分布平衡。
数据集来源
- 该数据集用于知识库丰富化的神经关系抽取研究,由Trisedya等人于2019年提出。
搜集汇总
数据集介绍
构建方式
Saibo-creator/wiki-nre数据集的构建是基于对维基百科文本中实体及其关系的抽取。该数据集通过远监督方法,结合共指消解和释义检测,收集高质量的训练数据。数据集中包含文本、实体、关系以及三元组等信息,这些信息被结构化为易于机器处理的形式,以便于后续的神经网络模型训练和知识库丰富。
特点
该数据集的特点在于其关系分布存在显著偏斜,前10个关系构成了92%的三元组,其中前3个关系占据了69%。为了解决这一问题,数据集特别构建了一个名为`stratified_test_1K`的子集,该子集从测试集中缩减至1000个样本,并实现了关系的平衡分布。此外,数据集还提供了相应的实体和关系子集目录,以便于用户进行更精细的数据操作。
使用方法
使用该数据集时,用户可以从HuggingFace提供的链接中下载不同 splits 的数据文件,包括训练集、测试集、平衡分布的测试子集以及验证集。数据集的配置文件指明了各个数据文件的路径,用户可以根据这些路径加载相应的数据,并利用数据集中的信息进行知识库的丰富、实体关系抽取等任务。
背景与挑战
背景概述
在知识图谱构建与关系提取领域,Saibo-creator/wiki-nre数据集的诞生标志着一种新的研究进展。该数据集由Trisedya等人于2019年创建,依托于维基百科的丰富内容,旨在通过端到端的方式提取实体及其关系,进而丰富知识库。研究团队来自于多个知名机构,包括德国马克思普朗克研究所等,其成果在ACL会议上发表,对知识图谱的自动构建与维护领域产生了深远影响。
当前挑战
该数据集在构建过程中面临了诸多挑战,首先,关系分布的偏斜问题导致了数据集中少数关系占据绝大多数三元组,这对于模型的泛化能力提出了挑战。其次,实体和关系的识别与映射过程中,传统的命名实体消歧方法容易引入误差,从而影响整体精确度和召回率。为了应对这些挑战,研究团队采用了远程监督、共指消解和释义检测等方法来收集高质量的训练数据,并设计了一种基于n-gram注意力的模型来捕捉句子中的多词实体名称。
常用场景
经典使用场景
在知识图谱构建与完善的过程中,Saibo-creator/wiki-nre数据集扮演着至关重要的角色。该数据集广泛用于关系抽取任务,旨在从文本中提取出实体及其相互之间的关系,并以三元组的形式表示。经典的使用场景包括利用其预训练好的模型直接进行关系抽取,或者在此基础上进行微调以适应特定的领域需求。
解决学术问题
该数据集解决了知识图谱构建中关系抽取的准确性问题。通过提供大量标注好的三元组数据,研究者能够训练出更加精确的模型,从而提高关系抽取的F1分数。这对于减少知识图谱中的噪音数据,提升图谱质量和丰富度具有显著意义。
衍生相关工作
基于wiki-nre数据集,研究者们衍生出了一系列相关工作,如提出了更为高级的模型架构、关系抽取算法以及实体识别与消歧技术。这些工作进一步推动了知识图谱和自然语言处理领域的发展,为相关任务提供了新的视角和方法论。
以上内容由遇见数据集搜集并总结生成


