Mapleyuchen/MME-RealWorld
收藏Hugging Face2026-03-17 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/Mapleyuchen/MME-RealWorld
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- multiple-choice
- question-answering
- visual-question-answering
language:
- en
size_categories:
- 100B<n<1T
---
* **`2024.11.14`** 🌟 MME-RealWorld now has a [lite version](https://huggingface.co/datasets/yifanzhang114/MME-RealWorld-Lite) (50 samples per task) for inference acceleration, which is also supported by VLMEvalKit and Lmms-eval.
* **`2024.10.27`** 🌟 LLaVA-OV currently ranks first on our leaderboard, but its overall accuracy remains below 55%, see our [leaderboard](https://mme-realworld.github.io/home_page.html#leaderboard) for the detail.
* **`2024.09.03`** 🌟 MME-RealWorld is now supported in the [VLMEvalKit](https://github.com/open-compass/VLMEvalKit) and [Lmms-eval](https://github.com/EvolvingLMMs-Lab/lmms-eval) repository, enabling one-click evaluation—give it a try!"
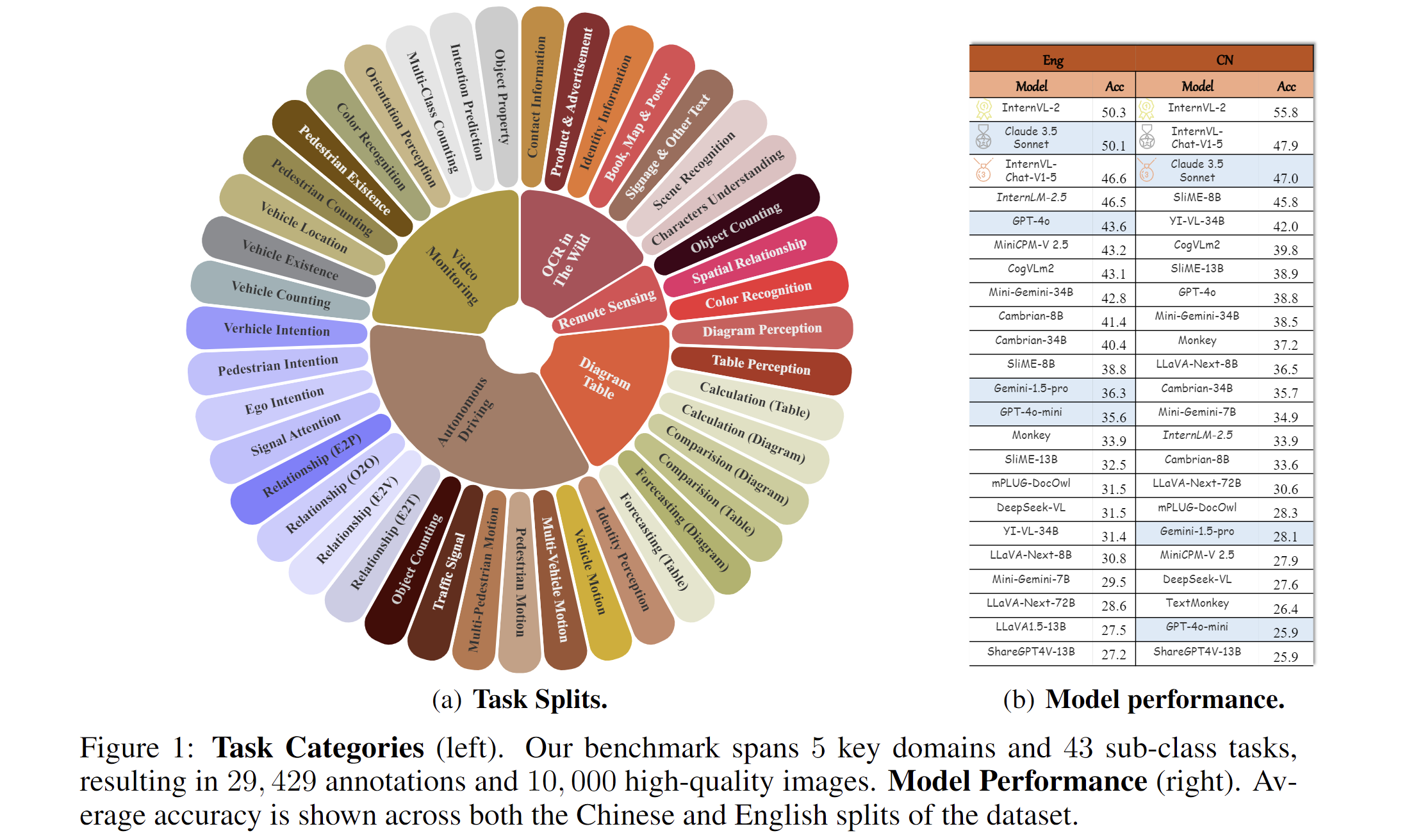
* **`2024.08.20`** 🌟 We are very proud to launch MME-RealWorld, which contains 13K high-quality images, annotated by 32 volunteers, resulting in 29K question-answer pairs that cover 43 subtasks across 5 real-world scenarios. As far as we know, **MME-RealWorld is the largest manually annotated benchmark to date, featuring the highest resolution and a targeted focus on real-world applications**.
Paper: arxiv.org/abs/2408.13257
Code: https://github.com/yfzhang114/MME-RealWorld
Project page: https://mme-realworld.github.io/

## How to use?
Since the image files are large and have been split into multiple compressed parts, please first merge the compressed files with the same name and then extract them together.
```
#!/bin/bash
# Function to process each set of split files
process_files() {
local part="$1"
# Extract the base name of the file
local base_name=$(basename "$part" .tar.gz.part_aa)
# Merge the split files into a single archive
cat "${base_name}".tar.gz.part_* > "${base_name}.tar.gz"
# Extract the merged archive
tar -xzf "${base_name}.tar.gz"
# Remove the individual split files
rm -rf "${base_name}".tar.gz.part_*
rm -rf "${base_name}.tar.gz"
}
export -f process_files
# Find all .tar.gz.part_aa files and process them in parallel
find . -name '*.tar.gz.part_aa' | parallel process_files
# Wait for all background jobs to finish
wait
# nohup bash unzip_file.sh >> unfold.log 2>&1 &
```
# MME-RealWorld Data Card
## Dataset details
Existing Multimodal Large Language Model benchmarks present several common barriers that make it difficult to measure the significant challenges that models face in the real world, including:
1) small data scale leads to a large performance variance;
2) reliance on model-based annotations results in restricted data quality;
3) insufficient task difficulty, especially caused by the limited image resolution.
We present MME-RealWord, a benchmark meticulously designed to address real-world applications with practical relevance. Featuring 13,366 high-resolution images averaging 2,000 × 1,500 pixels, MME-RealWord poses substantial recognition challenges. Our dataset encompasses 29,429 annotations across 43 tasks, all expertly curated by a team of 25 crowdsource workers and 7 MLLM experts. The main advantages of MME-RealWorld compared to existing MLLM benchmarks as follows:
1. **Data Scale**: with the efforts of a total of 32 volunteers, we have manually annotated 29,429 QA pairs focused on real-world scenarios, making this the largest fully human-annotated benchmark known to date.
2. **Data Quality**: 1) Resolution: Many image details, such as a scoreboard in a sports event, carry critical information. These details can only be properly interpreted with high- resolution images, which are essential for providing meaningful assistance to humans. To the best of our knowledge, MME-RealWorld features the highest average image resolution among existing competitors. 2) Annotation: All annotations are manually completed, with a professional team cross-checking the results to ensure data quality.
3. **Task Difficulty and Real-World Utility.**: We can see that even the most advanced models have not surpassed 60% accuracy. Additionally, many real-world tasks are significantly more difficult than those in traditional benchmarks. For example, in video monitoring, a model needs to count the presence of 133 vehicles, or in remote sensing, it must identify and count small objects on a map with an average resolution exceeding 5000×5000.
4. **MME-RealWord-CN.**: Existing Chinese benchmark is usually translated from its English version. This has two limitations: 1) Question-image mismatch. The image may relate to an English scenario, which is not intuitively connected to a Chinese question. 2) Translation mismatch [58]. The machine translation is not always precise and perfect enough. We collect additional images that focus on Chinese scenarios, asking Chinese volunteers for annotation. This results in 5,917 QA pairs.
---
许可证:Apache-2.0
任务类别:
- 多项选择
- 问答
- 视觉问答(Visual Question Answering)
语言:
- 英语
规模类别:
- 100B < n < 1T
---
* **`2024.11.14`** 🌟 MME-RealWorld 现已推出轻量版(lite version),每个任务包含50个样本以加速推理,该版本同时获得了VLMEvalKit与Lmms-eval的支持。[点击查看](https://huggingface.co/datasets/yifanzhang114/MME-RealWorld-Lite)
* **`2024.10.27`** 🌟 LLaVA-OV目前在我们的排行榜中位列第一,但其整体准确率仍低于55%,详细信息可参阅[排行榜页面](https://mme-realworld.github.io/home_page.html#leaderboard)。
* **`2024.09.03`** 🌟 MME-RealWorld 现已支持在[VLMEvalKit](https://github.com/open-compass/VLMEvalKit)与[Lmms-eval](https://github.com/EvolvingLMMs-Lab/lmms-eval)仓库中使用,支持一键式评估,欢迎尝试!
* **`2024.08.20`** 🌟 我们非常荣幸推出MME-RealWorld,该数据集包含13366张高质量图像,由32名志愿者完成标注,最终生成29429条问答对,覆盖5个真实场景下的43个子任务。据我们所知,**MME-RealWorld是目前规模最大的人工标注基准数据集,具备最高的图像分辨率,且专门针对真实世界应用场景设计**。
论文:arxiv.org/abs/2408.13257
代码:https://github.com/yfzhang114/MME-RealWorld
项目页面:https://mme-realworld.github.io/

## 使用方法
由于图像文件体积较大且已拆分为多个压缩分卷,请先将同名的压缩分卷合并,再一并解压。
#!/bin/bash
# 功能:处理拆分后的压缩分卷集合
process_files() {
local part="$1"
# 获取文件的基础名称
local base_name=$(basename "$part" .tar.gz.part_aa)
# 将拆分的分卷合并为单个归档文件
cat "${base_name}".tar.gz.part_* > "${base_name}.tar.gz"
# 解压合并后的归档文件
tar -xzf "${base_name}.tar.gz"
# 删除单个拆分的分卷文件
rm -rf "${base_name}".tar.gz.part_*
# 删除合并后的归档文件(可选,可根据需求保留)
rm -rf "${base_name}.tar.gz"
}
export -f process_files
# 查找所有以.tar.gz.part_aa结尾的文件,并并行处理
find . -name '*.tar.gz.part_aa' | parallel process_files
# 等待所有后台任务完成
wait
# nohup bash unzip_file.sh >> unfold.log 2>&1 &
# 说明:使用nohup后台运行脚本,日志输出至unfold.log
# MME-RealWorld 数据集卡片
## 数据集详情
现有多模态大语言模型(Multimodal Large Language Model, MLLM)基准数据集存在若干共性障碍,难以准确衡量模型在真实世界中面临的实际挑战,具体包括:
1. 数据规模较小,导致模型性能波动幅度较大;
2. 依赖基于模型的自动标注,导致数据质量受限;
3. 任务难度不足,这一问题尤其由图像分辨率偏低所导致。
我们提出MME-RealWord,一款专为真实世界应用场景精心设计的基准数据集。该数据集包含13366张平均分辨率为2000×1500像素的高分辨率图像,为模型带来了极具挑战性的识别任务。我们的数据集共覆盖43个任务,包含29429条标注,所有标注均由25名众包工作者与7名多模态大语言模型专家组成的团队精心审核与整理。相较于现有多模态大语言模型基准数据集,MME-RealWorld的核心优势如下:
1. **数据规模**:通过32名志愿者的共同努力,我们针对真实世界场景手动标注了29429条问答对,是目前已知规模最大的全人工标注基准数据集。
2. **数据质量**:1)分辨率:许多图像细节(例如体育赛事中的计分板)承载着关键信息,只有借助高分辨率图像才能准确解读,而这对为人类提供有意义的辅助至关重要。据我们所知,MME-RealWorld的平均图像分辨率在现有同类基准中处于领先水平。2)标注质量:所有标注均由人工完成,并由专业团队进行交叉审核,以确保数据质量。
3. **任务难度与真实世界实用性**:现有研究表明,即便是最先进的多模态大语言模型,在该数据集上的准确率也未超过60%。此外,许多真实世界任务的难度显著高于传统基准数据集。例如在视频监控场景中,模型需要统计133辆车辆的出现情况;而在遥感场景中,模型必须识别并统计平均分辨率超过5000×5000的地图上的小型物体。
4. **MME-RealWord-CN**:现有中文基准数据集通常由英文版本翻译而来,存在两处明显局限:1)图像与问题不匹配:图像可能关联英文场景,与中文问题无法形成直观的语义关联;2)翻译偏差[58]:机器翻译往往难以达到完美的精准度。为此,我们收集了聚焦于中文场景的额外图像,并邀请中文志愿者进行标注,最终生成5917条问答对。

提供机构:
Mapleyuchen


