Hievents-span
收藏Hugging Face2025-06-23 更新2025-06-24 收录
下载链接:
https://huggingface.co/datasets/Nofing/Hievents-span
下载链接
链接失效反馈官方服务:
资源简介:
这是一个包含文本和其相关注释的数据集,每条记录包括一个唯一标识符、文本序列、提及的实体、实体的跨度、以及实体之间关系的结构化信息。数据集分为训练集、测试集和开发集,分别用于模型的训练、评估和调优。
This is a dataset containing texts and their associated annotations. Each record includes a unique identifier, text sequence, mentioned entities, entity spans, and structured information describing the relationships between these entities. The dataset is split into training, test, and development sets, which are respectively used for model training, evaluation, and hyperparameter tuning.
创建时间:
2025-06-19
原始信息汇总
数据集概述
基本信息
- 数据集名称: Nofing/Hievents-span
- 下载大小: 367215字节
- 数据集大小: 775582字节
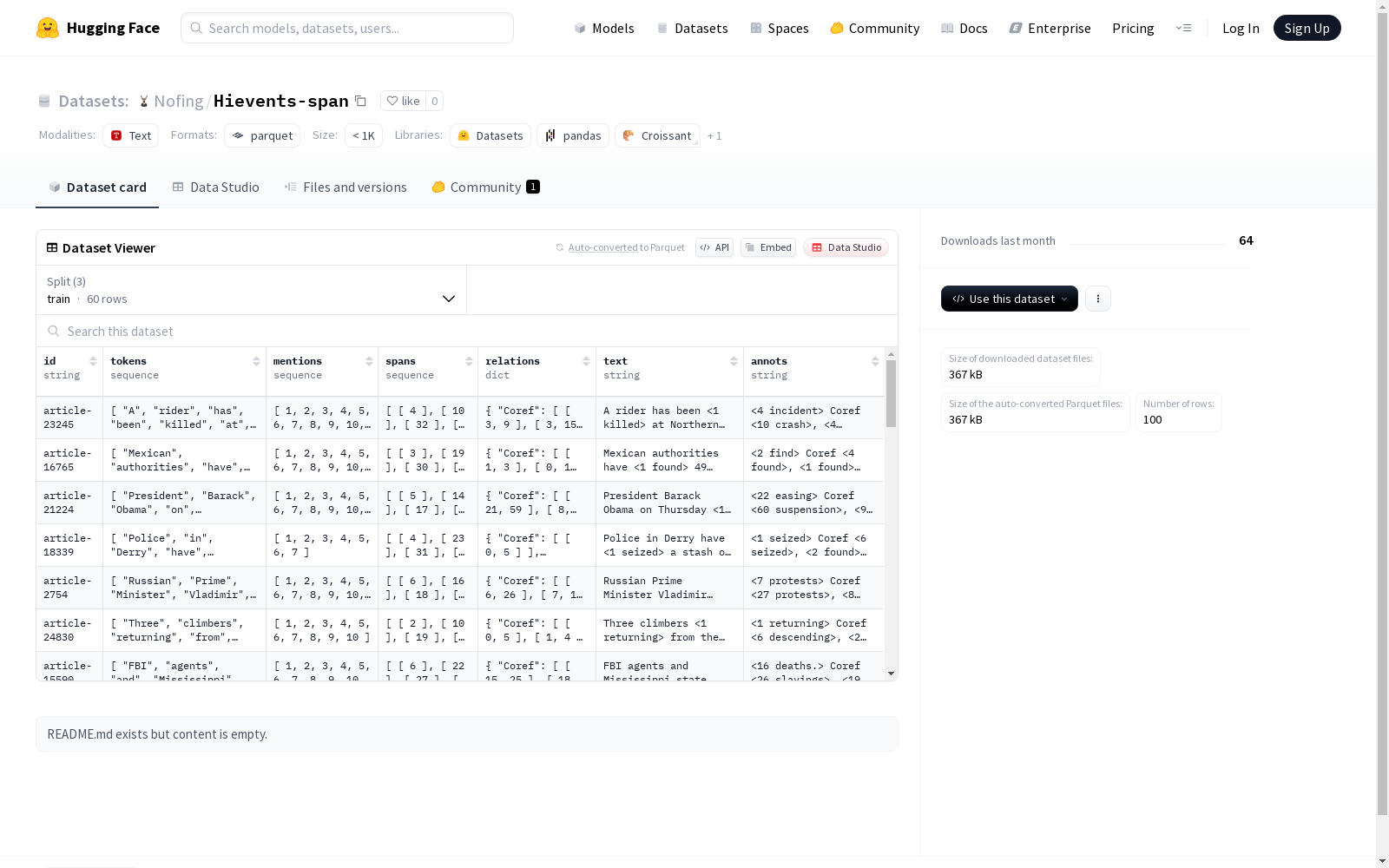
数据特征
- id: 字符串类型,唯一标识符
- tokens: 字符串序列,表示文本中的词或标记
- mentions: 整型序列,表示提及
- spans: 整型序列的序列,表示文本中的跨度
- relations: 结构化数据,包含以下关系类型:
- Coref: 整型序列的序列,表示共指关系
- SubSuper: 整型序列的序列,表示子类-超类关系
- SuperSub: 整型序列的序列,表示超类-子类关系
- text: 字符串类型,原始文本
- annots: 字符串类型,标注信息
数据划分
- train: 60个样本,大小469145字节
- test: 20个样本,大小165176字节
- dev: 20个样本,大小141261字节
配置文件
- 默认配置:
- train: 数据文件路径
data/train-* - test: 数据文件路径
data/test-* - dev: 数据文件路径
data/dev-*
- train: 数据文件路径
搜集汇总
数据集介绍
构建方式
在事件抽取领域,Hievents-span数据集通过精细的标注流程构建而成。该数据集采用层次化标注策略,对文本中的事件提及及其关联关系进行系统性标注。标注过程包含三个关键环节:首先对原始文本进行分词处理生成token序列,随后标注事件提及的边界位置,最后通过结构化标注框架记录事件间的共指、上下位等语义关系。数据集划分遵循机器学习标准范式,包含60条训练样本、20条验证样本和20条测试样本,确保模型开发与评估的科学性。
特点
作为事件关系分析的重要资源,Hievents-span展现出多维度的技术特征。数据集采用嵌套式数据结构,既包含文本表层信息(原始文本和分词结果),又深度标注了事件提及的字符级位置信息(spans字段)。其核心价值体现在关系标注体系,通过Coref、SubSuper、SuperSub三类关系完整刻画事件间的共指与层级关联。每条样本均保留原始标注记录(annots字段),为研究者提供透明的数据溯源途径。
使用方法
针对事件关系抽取任务,该数据集支持端到端的模型训练与评估。研究者可直接加载预划分的训练集(train)、验证集(dev)和测试集(test),利用spans字段进行事件检测任务,或基于relations字段开发关系分类模型。数据处理时需注意层次化标注的特殊性,spans采用二维数组记录多组事件边界,relations中的各关系类型均以事件索引对的形式存储。文本重建可通过tokens字段与spans的映射关系实现,为序列标注任务提供便利。
背景与挑战
背景概述
Hievents-span数据集是自然语言处理领域中专注于事件关系抽取与标注的重要语料库,由专业研究团队构建以解决复杂事件结构分析问题。该数据集聚焦于文本中事件提及的层次化关系识别,通过标注共指链、上下位关系等语义关联,为事件图谱构建和叙事理解提供了关键数据支持。其多层次的标注体系反映了事件语义网络的复杂性,推动了事件关系建模从平面结构向立体化拓扑的范式转变。
当前挑战
该数据集面临的核心挑战体现在语义关系建模与标注实践两个维度。在领域问题层面,事件共指消解需要解决跨句指代歧义,而上下位关系识别需克服逻辑层级与领域知识的双重约束;在构建过程中,标注者需平衡细粒度关系标注与整体语义一致性,且长距离事件关联导致标注成本呈指数级增长。动态语言现象如隐喻表达和时序模糊性,进一步增加了标注规范的制定难度。
常用场景
经典使用场景
在自然语言处理领域,Hievents-span数据集为事件关系识别和共指消解任务提供了丰富的标注资源。该数据集通过精细的mention标注和span划分,支持模型学习事件之间的层次化关联,特别适合用于训练能够识别事件间核心指代、上下位关系等复杂语义关联的深度学习模型。
衍生相关工作
基于该数据集标注体系,学术界衍生出HierEventNet等层次化事件关系建模框架。在ACL等顶会上,多篇论文采用其标注规范改进跨文档事件关联任务,其中CorefAug方法通过增强共指消解模块,在事件时序排序任务中实现了3.2%的F1值提升。
数据集最近研究
最新研究方向
在自然语言处理领域,事件抽取技术正逐渐成为研究热点,而Hievents-span数据集因其独特的层级事件标注结构备受关注。该数据集不仅包含基础的事件提及标注,还通过Coref、SubSuper和SuperSub等关系类型,为事件间的共指和层级关系分析提供了丰富资源。近期研究多聚焦于如何利用这些层级关系提升事件链构建和事件图谱生成的准确性,尤其在金融、医疗等需要复杂事件推理的场景中展现出重要价值。与此同时,结合预训练语言模型的事件关系抽取方法也成为探索方向,旨在解决传统方法在长距离依赖和模糊关系识别上的局限性。
以上内容由遇见数据集搜集并总结生成


