EuroGEC-7
收藏Hugging Face2025-06-15 更新2025-06-16 收录
下载链接:
https://huggingface.co/datasets/NoeFlandre/EuroGEC-7
下载链接
链接失效反馈官方服务:
资源简介:
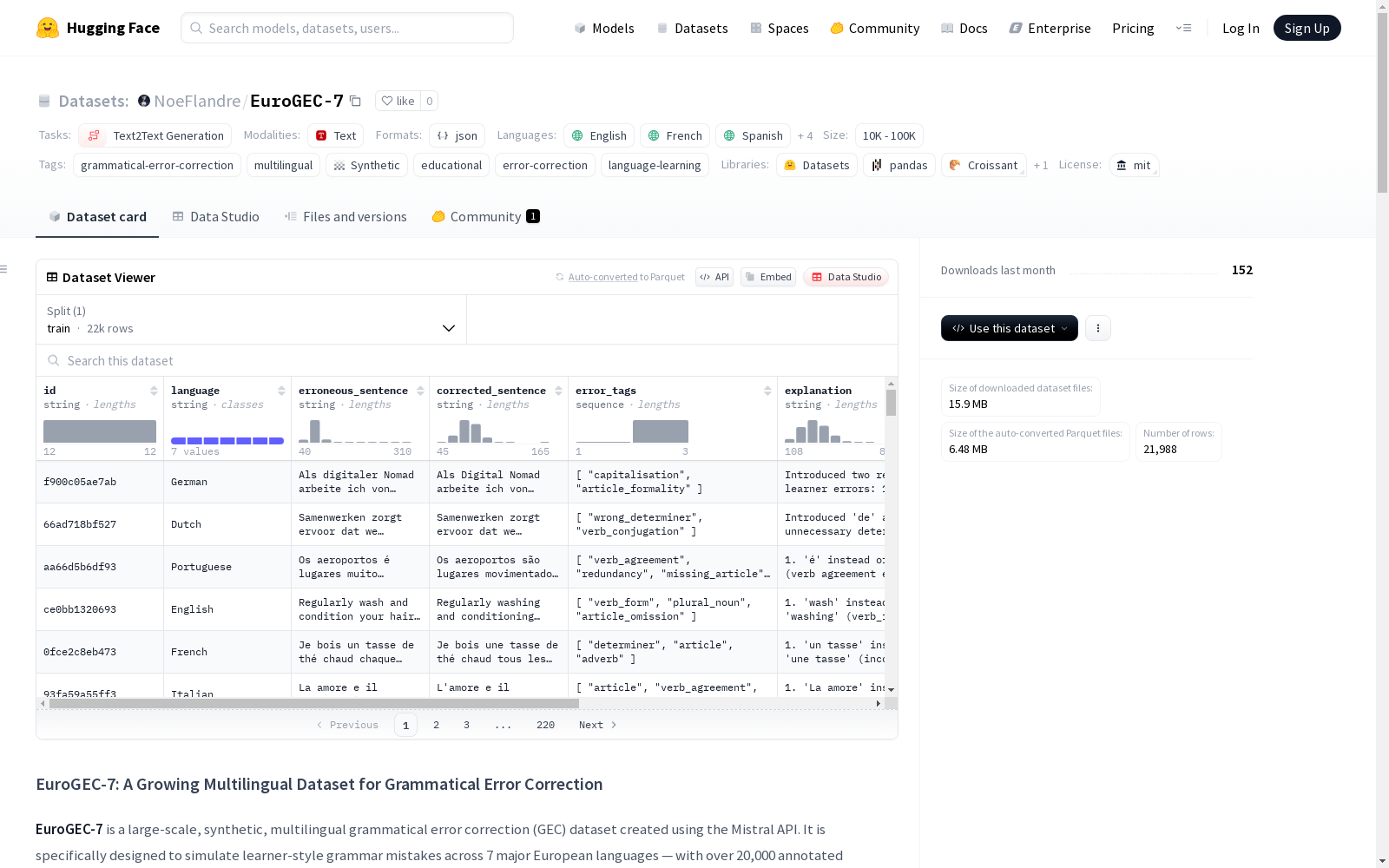
EuroGEC-7是一个大规模的多语种合成语法错误校正(GEC)数据集,使用Mistral API生成。它涵盖了7种主要的欧洲语言,包含具有典型语法错误的简短学习者风格的句子及其修正、错误标签和简短解释。数据集包含7000多个高质量的句子级错误/修正对,旨在模拟现实中的第二语言学习者错误,可用于训练和评估多语种GEC模型。
EuroGEC-7 is a large-scale multilingual synthetic grammatical error correction (GEC) dataset generated via the Mistral API. It covers 7 major European languages, and includes short learner-style sentences with typical grammatical errors, paired with their corresponding corrections, error tags and concise explanations. The dataset contains over 7,000 high-quality sentence-level error/correction pairs, which are intended to simulate real-world second language learner errors, and can be utilized for training and evaluating multilingual GEC models.
创建时间:
2025-06-14
搜集汇总
数据集介绍
构建方式
在构建EuroGEC-7数据集的过程中,研究团队采用了基于Mistral API的自动化生成流程。该流程首先从150多个真实世界主题中抽取话题样本,随后通过精心设计的提示词模板生成多语言基础句。通过模拟第二语言学习者的常见错误模式,系统自动注入语法、句法和词汇选择等方面的错误,并配套生成纠错版本、错误标签及简明解释。为确保数据质量,流程还包含去重、句子验证和长度控制等质量控制环节,同时完整记录语言类型、时间戳和模型版本等元数据。这种模块化设计使得数据集能够持续扩展新的主题、语言和错误类型。
使用方法
该数据集以标准化的JSON Lines格式存储,可直接接入主流NLP框架进行处理。研究人员可通过Hugging Face平台获取完整数据集,利用其丰富的标注信息开展多语言语法纠错模型训练。在教育技术领域,该数据集适用于开发智能语法检查工具,其简明解释字段特别适合用于构建交互式语言学习系统。对于大语言模型研究,数据集提供的错误-正确句对可作为优质的提示词优化素材。使用过程中需注意数据的合成性质,建议结合真实学习者语料进行交叉验证以获得更可靠的研究结果。
背景与挑战
背景概述
EuroGEC-7数据集是2025年由Noé Flandre开发的大规模多语言语法纠错数据集,专注于模拟七种欧洲语言(英语、法语、西班牙语、德语、意大利语、葡萄牙语和荷兰语)中第二语言学习者常见的语法错误。该数据集通过Mistral API生成,覆盖150多个现实主题,旨在为教育自然语言处理和多语言语法纠错模型训练提供支持。其独特之处在于结合了多样化的语境和详细的错误标注,为研究者提供了丰富的语言学习资源,推动了跨语言语法纠错技术的发展。
当前挑战
EuroGEC-7数据集面临的主要挑战包括:1) 领域问题方面,尽管数据集模拟了学习者常见的语法错误,但其完全基于合成数据,可能无法完全反映真实学习者的错误模式;2) 构建过程中,确保多语言错误注入的准确性和一致性是一项复杂任务,同时需要平衡句子多样性与主题覆盖范围。此外,依赖Mistral API可能引入模型偏见,影响生成数据的质量和风格。这些挑战限制了数据集在真实教育场景中的应用效果。
常用场景
经典使用场景
在自然语言处理领域,EuroGEC-7数据集为多语言语法错误纠正任务提供了标准化基准。研究者通过该数据集可训练和评估跨语言语法纠错模型,尤其擅长模拟英语、法语等七种欧洲语言学习者的典型错误模式。其覆盖150余个现实主题的语料,有效支撑了模型在多样化语境下的泛化能力测试。
解决学术问题
该数据集解决了多语言语法纠错研究中真实语料稀缺的核心难题。通过系统性生成学习者风格的错误标注数据,支持了低资源语言的GEC模型开发,并为跨语言错误模式比较研究提供实证基础。其细粒度的错误标签体系进一步推动了错误类型分类学的定量分析。
实际应用
在教育科技场景中,该数据集成为智能写作辅助系统的关键训练资源。语言学习应用利用其多语言纠错对提升自动批改功能,而在线教育平台则基于错误模式分析开发个性化语法教学模块。其合成数据的可控性也降低了商业应用中的隐私合规风险。
数据集最近研究
最新研究方向
随着多语言教育技术的快速发展,EuroGEC-7数据集在语法纠错领域展现出独特价值。该数据集通过模拟七种欧洲语言学习者的常见错误,为跨语言模型训练提供了丰富资源。当前研究聚焦于如何利用其合成数据特性提升低资源语言的纠错性能,特别是在德语和荷兰语等相对缺乏真实学习者语料的语言上。教育技术领域正探索将该数据集与大型语言模型结合,开发自适应学习系统,以识别不同母语背景学习者的语法错误模式。多语言语法错误的对比分析也成为热点,研究者试图通过跨语言错误标签的关联性,揭示语言习得过程中的共性规律。
以上内容由遇见数据集搜集并总结生成


